 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROADWork Dataset: Learning to Recognize, Observe, Analyze and Drive Through Work Zones
Jun 11, 2024



Perceiving and navigating through work zones is challenging and under-explored, even with major strides in self-driving research. An important reason is the lack of open datasets for developing new algorithms to address this long-tailed scenario. We propose the ROADWork dataset to learn how to recognize, observe and analyze and drive through work zones. We find that state-of-the-art foundation models perform poorly on work zones. With our dataset, we improve upon detecting work zone objects (+26.2 AP), while discovering work zones with higher precision (+32.5%) at a much higher discovery rate (12.8 times), significantly improve detecting (+23.9 AP) and reading (+14.2% 1-NED) work zone signs and describing work zones (+36.7 SPICE). We also compute drivable paths from work zone navigation videos and show that it is possible to predict navigational goals and pathways such that 53.6% goals have angular error (AE) < 0.5 degrees (+9.9 %) and 75.3% pathways have AE < 0.5 degrees (+8.1 %).
WALT3D: Generating Realistic Training Data from Time-Lapse Imagery for Reconstructing Dynamic Objects under Occlusion
Apr 01, 2024



Current methods for 2D and 3D object understanding struggle with severe occlusions in busy urban environments, partly due to the lack of large-scale labeled ground-truth annotations for learning occlusion. In this work, we introduce a novel framework for automatically generating a large, realistic dataset of dynamic objects under occlusions using freely available time-lapse imagery. By leveraging off-the-shelf 2D (bounding box, segmentation, keypoint) and 3D (pose, shape) predictions as pseudo-groundtruth, unoccluded 3D objects are identified automatically and composited into the background in a clip-art style, ensuring realistic appearances and physically accurate occlusion configurations. The resulting clip-art image with pseudo-groundtruth enables efficient training of object reconstruction methods that are robust to occlusions. Our method demonstrates significant improvements in both 2D and 3D reconstruction, particularly in scenarios with heavily occluded objects like vehicles and people in urban scenes.
Addressing Source Scale Bias via Image Warping for Domain Adaptation
Mar 19, 2024



In visual recognition, scale bias is a key challenge due to the imbalance of object and image size distribution inherent in real scene datasets. Conventional solutions involve injecting scale invariance priors, oversampling the dataset at different scales during training, or adjusting scale at inference. While these strategies mitigate scale bias to some extent, their ability to adapt across diverse datasets is limited. Besides, they increase computational load during training and latency during inference. In this work, we use adaptive attentional processing -- oversampling salient object regions by warping images in-place during training. Discovering that shifting the source scale distribution improves backbone features, we developed a instance-level warping guidance aimed at object region sampling to mitigate source scale bias in domain adaptation. Our approach improves adaptation across geographies, lighting and weather conditions, is agnostic to the task, domain adaptation algorithm, saliency guidance, and underlying model architecture. Highlights include +6.1 mAP50 for BDD100K Clear $\rightarrow$ DENSE Foggy, +3.7 mAP50 for BDD100K Day $\rightarrow$ Night, +3.0 mAP50 for BDD100K Clear $\rightarrow$ Rainy, and +6.3 mIoU for Cityscapes $\rightarrow$ ACDC. Our approach adds minimal memory during training and has no additional latency at inference time. Please see Appendix for more results and analysis.
Virtual Home Staging: Inverse Rendering and Editing an Indoor Panorama under Natural Illumination
Nov 21, 2023We propose a novel inverse rendering method that enables the transformation of existing indoor panoramas with new indoor furniture layouts under natural illumination. To achieve this, we captured indoor HDR panoramas along with real-time outdoor hemispherical HDR photographs. Indoor and outdoor HDR images were linearly calibrated with measured absolute luminance values for accurate scene relighting. Our method consists of three key components: (1) panoramic furniture detection and removal, (2) automatic floor layout design, and (3) global rendering with scene geometry, new furniture objects, and a real-time outdoor photograph. We demonstrate the effectiveness of our workflow in rendering indoor scenes under different outdoor illumination conditions. Additionally, we contribute a new calibrated HDR (Cali-HDR) dataset that consists of 137 calibrated indoor panoramas and their associated outdoor photographs. The source code and dataset are available: https://github.com/Gzhji/Cali-HDR-Dataset.
TPSeNCE: Towards Artifact-Free Realistic Rain Generation for Deraining and Object Detection in Rain
Nov 08, 2023



Rain generation algorithms have the potential to improve the generalization of deraining methods and scene understanding in rainy conditions. However, in practice, they produce artifacts and distortions and struggle to control the amount of rain generated due to a lack of proper constraints. In this paper, we propose an unpaired image-to-image translation framework for generating realistic rainy images. We first introduce a Triangular Probability Similarity (TPS) constraint to guide the generated images toward clear and rainy images in the discriminator manifold, thereby minimizing artifacts and distortions during rain generation. Unlike conventional contrastive learning approaches, which indiscriminately push negative samples away from the anchors, we propose a Semantic Noise Contrastive Estimation (SeNCE) strategy and reassess the pushing force of negative samples based on the semantic similarity between the clear and the rainy images and the feature similarity between the anchor and the negative samples. Experiments demonstrate realistic rain generation with minimal artifacts and distortions, which benefits image deraining and object detection in rain. Furthermore, the method can be used to generate realistic snowy and night images, underscoring its potential for broader applicability. Code is available at https://github.com/ShenZheng2000/TPSeNCE.
Toward Planet-Wide Traffic Camera Calibration
Nov 06, 2023Despite the widespread deployment of outdoor cameras, their potential for automated analysis remains largely untapped due, in part, to calibration challenges. The absence of precise camera calibration data, including intrinsic and extrinsic parameters, hinders accurate real-world distance measurements from captured videos. To address this, we present a scalable framework that utilizes street-level imagery to reconstruct a metric 3D model, facilitating precise calibration of in-the-wild traffic cameras. Notably, our framework achieves 3D scene reconstruction and accurate localization of over 100 global traffic cameras and is scalable to any camera with sufficient street-level imagery. For evaluation, we introduce a dataset of 20 fully calibrated traffic cameras, demonstrating our method's significant enhancements over existing automatic calibration techniques. Furthermore, we highlight our approach's utility in traffic analysis by extracting insights via 3D vehicle reconstruction and speed measurement, thereby opening up the potential of using outdoor cameras for automated analysis.
Learned Two-Plane Perspective Prior based Image Resampling for Efficient Object Detection
Mar 25, 2023Real-time efficient perception is critical for autonomous navigation and city scale sensing. Orthogonal to architectural improvements, streaming perception approaches have exploited adaptive sampling improving real-time detection performance. In this work, we propose a learnable geometry-guided prior that incorporates rough geometry of the 3D scene (a ground plane and a plane above) to resample images for efficient object detection. This significantly improves small and far-away object detection performance while also being more efficient both in terms of latency and memory. For autonomous navigation, using the same detector and scale, our approach improves detection rate by +4.1 $AP_{S}$ or +39% and in real-time performance by +5.3 $sAP_{S}$ or +63% for small objects over state-of-the-art (SOTA). For fixed traffic cameras, our approach detects small objects at image scales other methods cannot. At the same scale, our approach improves detection of small objects by 195% (+12.5 $AP_{S}$) over naive-downsampling and 63% (+4.2 $AP_{S}$) over SOTA.
Learning Continuous Implicit Representation for Near-Periodic Patterns
Aug 25, 2022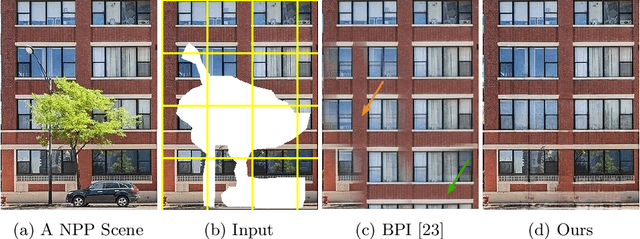
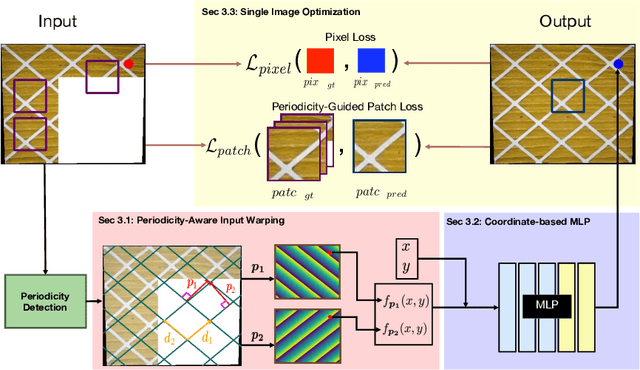
Near-Periodic Patterns (NPP) are ubiquitous in man-made scenes and are composed of tiled motifs with appearance differences caused by lighting, defects, or design elements. A good NPP representation is useful for many applications including image completion, segmentation, and geometric remapping. But representing NPP is challenging because it needs to maintain global consistency (tiled motifs layout) while preserving local variations (appearance differences). Methods trained on general scenes using a large dataset or single-image optimization struggle to satisfy these constraints, while methods that explicitly model periodicity are not robust to periodicity detection errors. To address these challenges, we learn a neural implicit representation using a coordinate-based MLP with single image optimization. We design an input feature warping module and a periodicity-guided patch loss to handle both global consistency and local variations. To further improve the robustness, we introduce a periodicity proposal module to search and use multiple candidate periodicities in our pipeline. We demonstrate the effectiveness of our method on more than 500 images of building facades, friezes, wallpapers, ground, and Mondrian patterns on single and multi-planar scenes.
Active Safety Envelopes using Light Curtains with Probabilistic Guarantees
Jul 08, 2021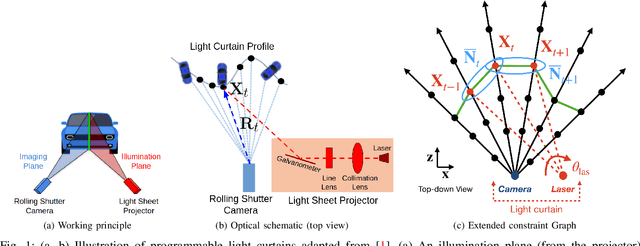
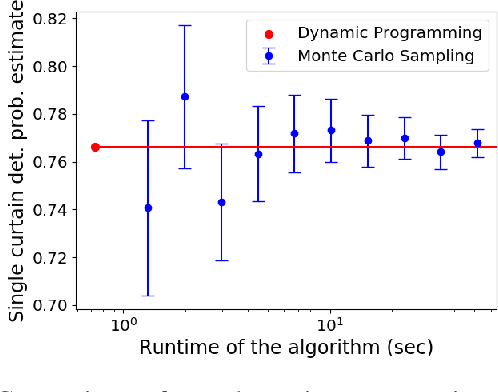
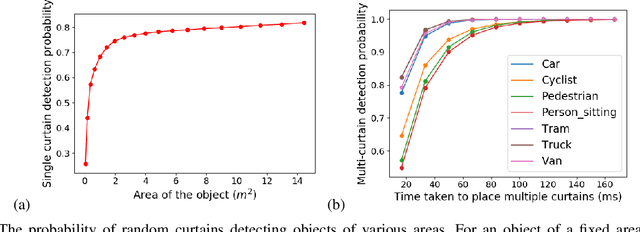

To safely navigate unknown environments, robots must accurately perceive dynamic obstacles. Instead of directly measuring the scene depth with a LiDAR sensor, we explore the use of a much cheaper and higher resolution sensor: programmable light curtains. Light curtains are controllable depth sensors that sense only along a surface that a user selects. We use light curtains to estimate the safety envelope of a scene: a hypothetical surface that separates the robot from all obstacles. We show that generating light curtains that sense random locations (from a particular distribution) can quickly discover the safety envelope for scenes with unknown objects. Importantly, we produce theoretical safety guarantees on the probability of detecting an obstacle using random curtains. We combine random curtains with a machine learning based model that forecasts and tracks the motion of the safety envelope efficiently. Our method accurately estimates safety envelopes while providing probabilistic safety guarantees that can be used to certify the efficacy of a robot perception system to detect and avoid dynamic obstacles. We evaluate our approach in a simulated urban driving environment and a real-world environment with moving pedestrians using a light curtain device and show that we can estimate safety envelopes efficiently and effectively. Project website: https://siddancha.github.io/projects/active-safety-envelopes-with-guarantees
TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video
Aug 29, 2020
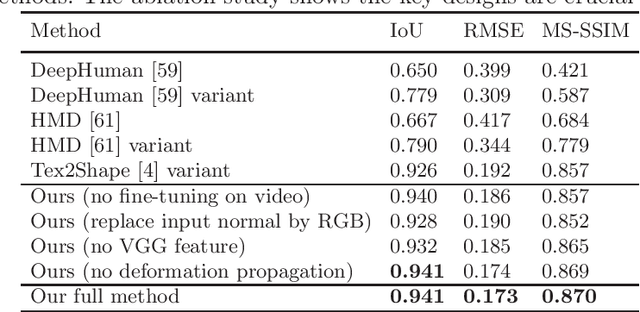
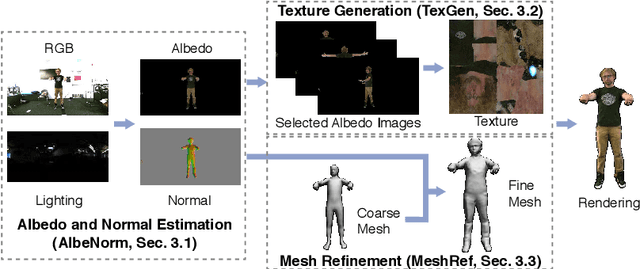

We present TexMesh, a novel approach to reconstruct detailed human meshes with high-resolution full-body texture from RGB-D video. TexMesh enables high quality free-viewpoint rendering of humans. Given the RGB frames, the captured environment map, and the coarse per-frame human mesh from RGB-D tracking, our method reconstructs spatiotemporally consistent and detailed per-frame meshes along with a high-resolution albedo texture. By using the incident illumination we are able to accurately estimate local surface geometry and albedo, which allows us to further use photometric constraints to adapt a synthetically trained model to real-world sequences in a self-supervised manner for detailed surface geometry and high-resolution texture estimation. In practice, we train our models on a short example sequence for self-adaptation and the model runs at interactive framerate afterwards. We validate TexMesh on synthetic and real-world data, and show it outperforms the state of art quantitatively and qualitatively.