 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoHumans: An Egocentric 3D Multi-Human Benchmark
May 25, 2023



We present EgoHumans, a new multi-view multi-human video benchmark to advance the state-of-the-art of egocentric human 3D pose estimation and tracking. Existing egocentric benchmarks either capture single subject or indoor-only scenarios, which limit the generalization of computer vision algorithms for real-world applications. We propose a novel 3D capture setup to construct a comprehensive egocentric multi-human benchmark in the wild with annotations to support diverse tasks such as human detection, tracking, 2D/3D pose estimation, and mesh recovery. We leverage consumer-grade wearable camera-equipped glasses for the egocentric view, which enables us to capture dynamic activities like playing soccer, fencing, volleyball, etc. Furthermore, our multi-view setup generates accurate 3D ground truth even under severe or complete occlusion. The dataset consists of more than 125k egocentric images, spanning diverse scenes with a particular focus on challenging and unchoreographed multi-human activities and fast-moving egocentric views. We rigorously evaluate existing state-of-the-art methods and highlight their limitations in the egocentric scenario, specifically on multi-human tracking. To address such limitations, we propose EgoFormer, a novel approach with a multi-stream transformer architecture and explicit 3D spatial reasoning to estimate and track the human pose. EgoFormer significantly outperforms prior art by 13.6% IDF1 and 9.3 HOTA on the EgoHumans dataset.
Snipper: A Spatiotemporal Transformer for Simultaneous Multi-Person 3D Pose Estimation Tracking and Forecasting on a Video Snippet
Jul 13, 2022
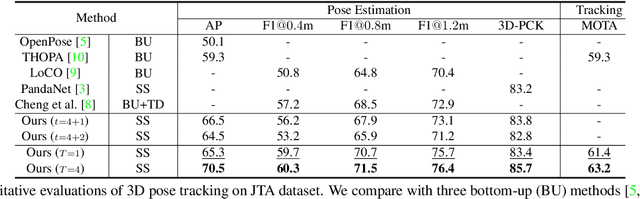
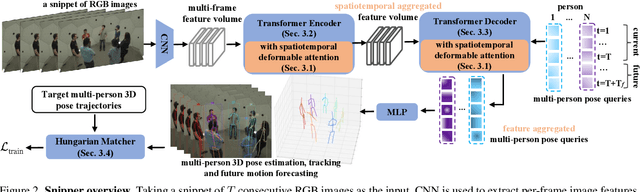
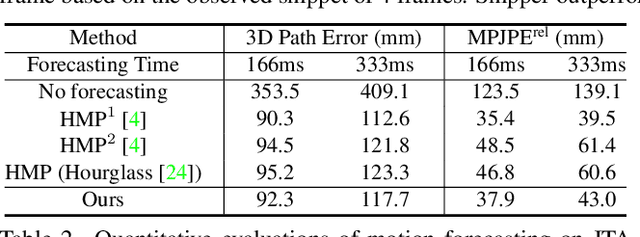
Multi-person pose understanding from RGB videos includes three complex tasks: pose estimation, tracking and motion forecasting. Among these three tasks, pose estimation and tracking are correlated, and tracking is crucial to motion forecasting. Most existing works either focus on a single task or employ cascaded methods to solve each individual task separately. In this paper, we propose Snipper, a framework to perform multi-person 3D pose estimation, tracking and motion forecasting simultaneously in a single inference. Specifically, we first propose a deformable attention mechanism to aggregate spatiotemporal information from video snippets. Building upon this deformable attention, a visual transformer is learned to encode the spatiotemporal features from multi-frame images and to decode informative pose features to update multi-person pose queries. Last, these queries are regressed to predict multi-person pose trajectories and future motions in one forward pass. In the experiments, we show the effectiveness of Snipper on three challenging public datasets where a generic model rivals specialized state-of-art baselines for pose estimation, tracking, and forecasting. Code is available at https://github.com/JimmyZou/Snipper
TAVA: Template-free Animatable Volumetric Actors
Jun 21, 2022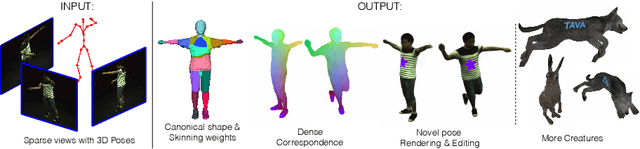

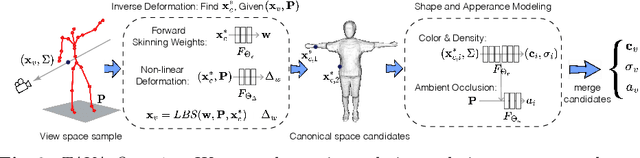
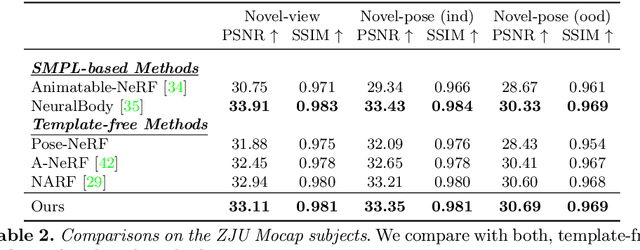
Coordinate-based volumetric representations have the potential to generate photo-realistic virtual avatars from images. However, virtual avatars also need to be controllable even to a novel pose that may not have been observed. Traditional techniques, such as LBS, provide such a function; yet it usually requires a hand-designed body template, 3D scan data, and limited appearance models. On the other hand, neural representation has been shown to be powerful in representing visual details, but are under explored on deforming dynamic articulated actors. In this paper, we propose TAVA, a method to create T emplate-free Animatable Volumetric Actors, based on neural representations. We rely solely on multi-view data and a tracked skeleton to create a volumetric model of an actor, which can be animated at the test time given novel pose. Since TAVA does not require a body template, it is applicable to humans as well as other creatures such as animals. Furthermore, TAVA is designed such that it can recover accurate dense correspondences, making it amenable to content-creation and editing tasks. Through extensive experiments, we demonstrate that the proposed method generalizes well to novel poses as well as unseen views and showcase basic editing capabilities.
LISA: Learning Implicit Shape and Appearance of Hands
Apr 04, 2022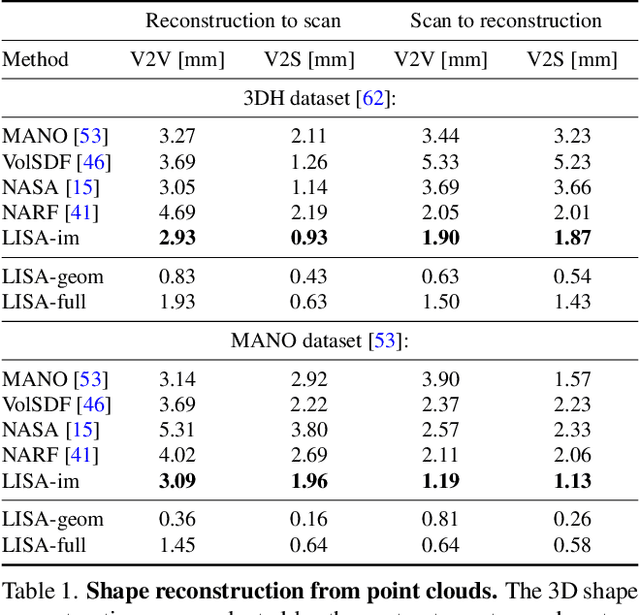
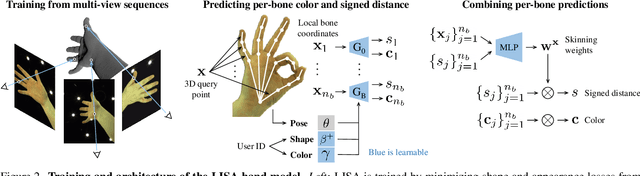
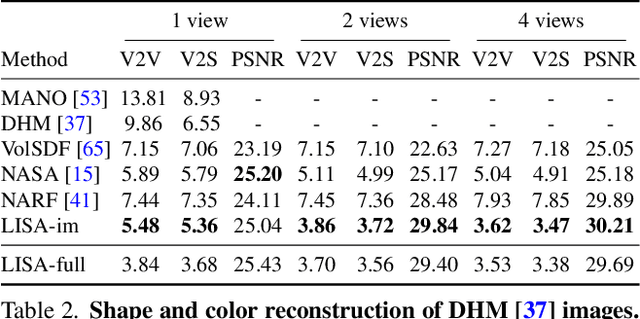

This paper proposes a do-it-all neural model of human hands, named LISA. The model can capture accurate hand shape and appearance, generalize to arbitrary hand subjects, provide dense surface correspondences, be reconstructed from images in the wild and easily animated. We train LISA by minimizing the shape and appearance losses on a large set of multi-view RGB image sequences annotated with coarse 3D poses of the hand skeleton. For a 3D point in the hand local coordinate, our model predicts the color and the signed distance with respect to each hand bone independently, and then combines the per-bone predictions using predicted skinning weights. The shape, color and pose representations are disentangled by design, allowing to estimate or animate only selected parameters. We experimentally demonstrate that LISA can accurately reconstruct a dynamic hand from monocular or multi-view sequences, achieving a noticeably higher quality of reconstructed hand shapes compared to baseline approaches. Project page: https://www.iri.upc.edu/people/ecorona/lisa/.
BANMo: Building Animatable 3D Neural Models from Many Casual Videos
Dec 24, 2021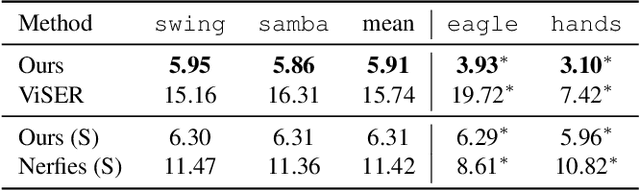
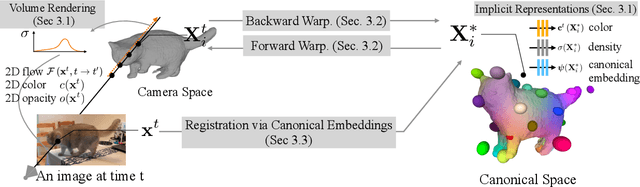

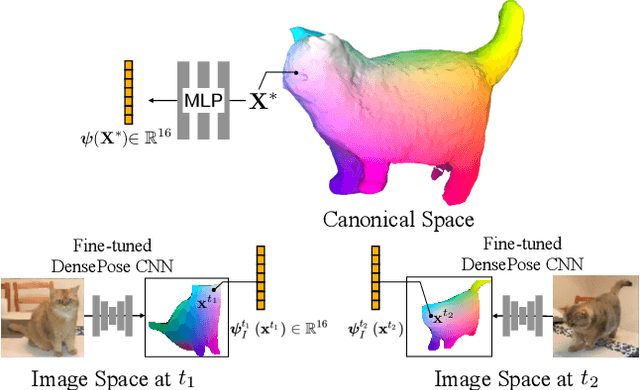
Prior work for articulated 3D shape reconstruction often relies on specialized sensors (e.g., synchronized multi-camera systems), or pre-built 3D deformable models (e.g., SMAL or SMPL). Such methods are not able to scale to diverse sets of objects in the wild. We present BANMo, a method that requires neither a specialized sensor nor a pre-defined template shape. BANMo builds high-fidelity, articulated 3D models (including shape and animatable skinning weights) from many monocular casual videos in a differentiable rendering framework. While the use of many videos provides more coverage of camera views and object articulations, they introduce significant challenges in establishing correspondence across scenes with different backgrounds, illumination conditions, etc. Our key insight is to merge three schools of thought; (1) classic deformable shape models that make use of articulated bones and blend skinning, (2) volumetric neural radiance fields (NeRFs) that are amenable to gradient-based optimization, and (3) canonical embeddings that generate correspondences between pixels and an articulated model. We introduce neural blend skinning models that allow for differentiable and invertible articulated deformations. When combined with canonical embeddings, such models allow us to establish dense correspondences across videos that can be self-supervised with cycle consistency. On real and synthetic datasets, BANMo shows higher-fidelity 3D reconstructions than prior works for humans and animals, with the ability to render realistic images from novel viewpoints and poses. Project webpage: banmo-www.github.io .
Ego4D: Around the World in 3,000 Hours of Egocentric Video
Oct 13, 2021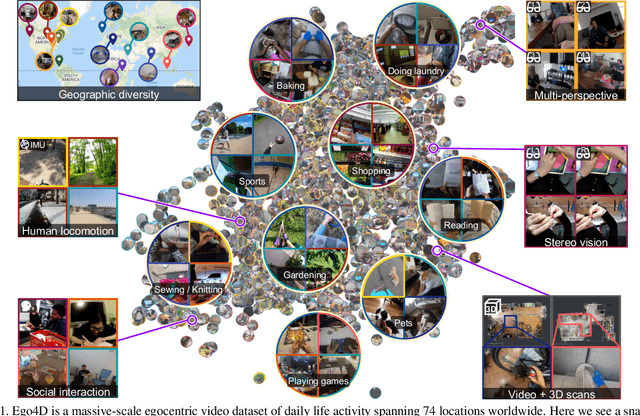
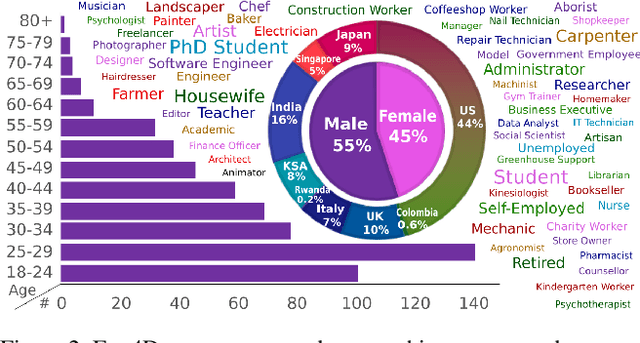

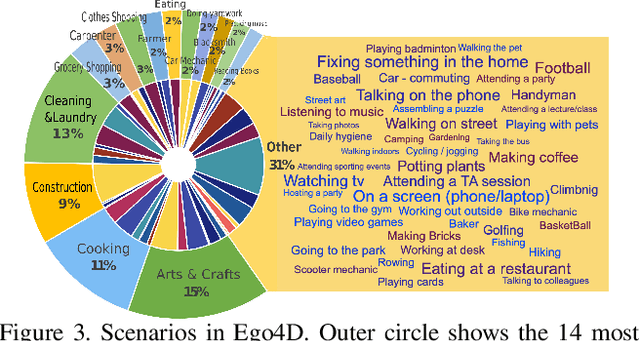
We introduce Ego4D, a massive-scale egocentric video dataset and benchmark suite. It offers 3,025 hours of daily-life activity video spanning hundreds of scenarios (household, outdoor, workplace, leisure, etc.) captured by 855 unique camera wearers from 74 worldwide locations and 9 different countries. The approach to collection is designed to uphold rigorous privacy and ethics standards with consenting participants and robust de-identification procedures where relevant. Ego4D dramatically expands the volume of diverse egocentric video footage publicly available to the research community. Portions of the video are accompanied by audio, 3D meshes of the environment, eye gaze, stereo, and/or synchronized videos from multiple egocentric cameras at the same event. Furthermore, we present a host of new benchmark challenges centered around understanding the first-person visual experience in the past (querying an episodic memory), present (analyzing hand-object manipulation, audio-visual conversation, and social interactions), and future (forecasting activities). By publicly sharing this massive annotated dataset and benchmark suite, we aim to push the frontier of first-person perception. Project page: https://ego4d-data.org/
ODAM: Object Detection, Association, and Mapping using Posed RGB Video
Aug 23, 2021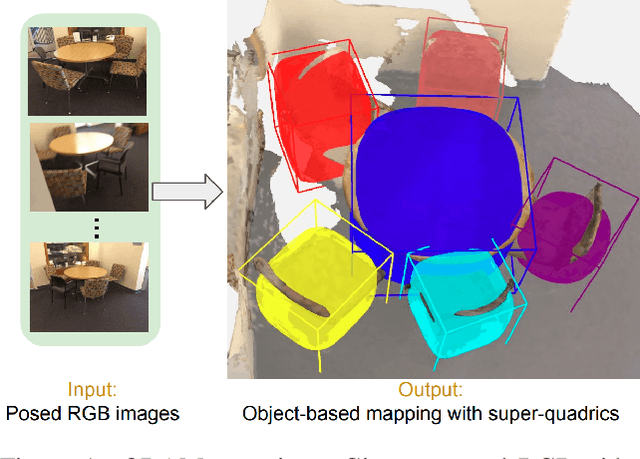

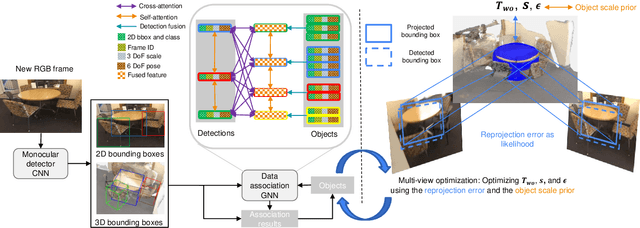
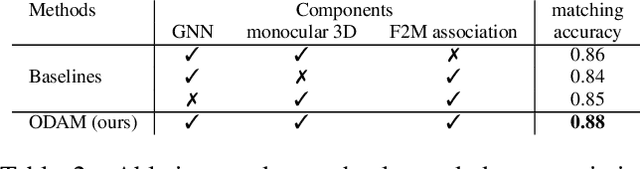
Localizing objects and estimating their extent in 3D is an important step towards high-level 3D scene understanding, which has many applications in Augmented Reality and Robotics. We present ODAM, a system for 3D Object Detection, Association, and Mapping using posed RGB videos. The proposed system relies on a deep learning front-end to detect 3D objects from a given RGB frame and associate them to a global object-based map using a graph neural network (GNN). Based on these frame-to-model associations, our back-end optimizes object bounding volumes, represented as super-quadrics, under multi-view geometry constraints and the object scale prior. We validate the proposed system on ScanNet where we show a significant improvement over existing RGB-only methods.
ContactOpt: Optimizing Contact to Improve Grasps
Apr 15, 2021
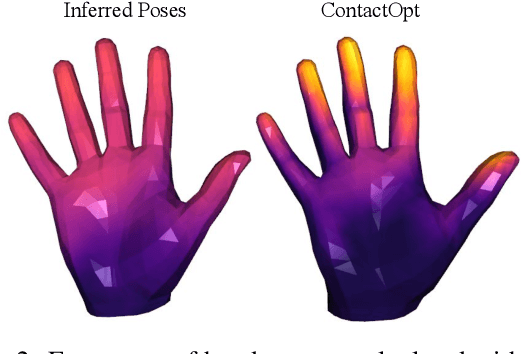
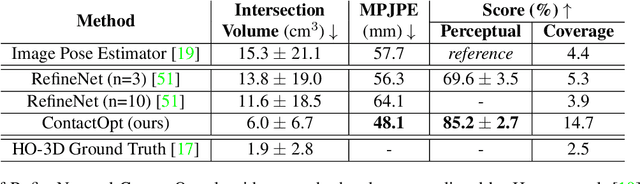

Physical contact between hands and objects plays a critical role in human grasps. We show that optimizing the pose of a hand to achieve expected contact with an object can improve hand poses inferred via image-based methods. Given a hand mesh and an object mesh, a deep model trained on ground truth contact data infers desirable contact across the surfaces of the meshes. Then, ContactOpt efficiently optimizes the pose of the hand to achieve desirable contact using a differentiable contact model. Notably, our contact model encourages mesh interpenetration to approximate deformable soft tissue in the hand. In our evaluations, our methods result in grasps that better match ground truth contact, have lower kinematic error, and are significantly preferred by human participants. Code and models are available online.
ANR: Articulated Neural Rendering for Virtual Avatars
Dec 23, 2020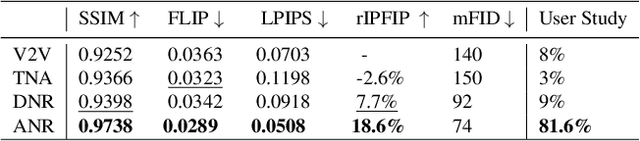
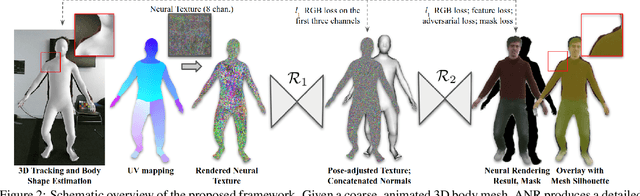
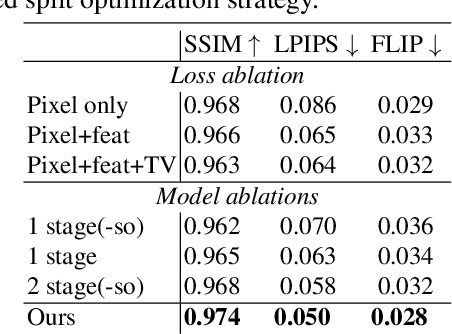
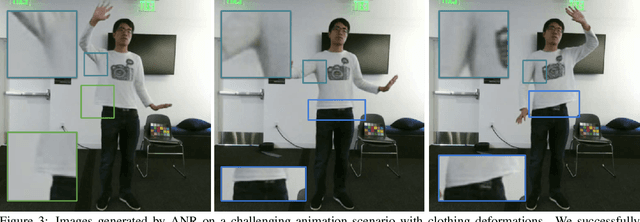
The combination of traditional rendering with neural networks in Deferred Neural Rendering (DNR) provides a compelling balance between computational complexity and realism of the resulting images. Using skinned meshes for rendering articulating objects is a natural extension for the DNR framework and would open it up to a plethora of applications. However, in this case the neural shading step must account for deformations that are possibly not captured in the mesh, as well as alignment inaccuracies and dynamics -- which can confound the DNR pipeline. We present Articulated Neural Rendering (ANR), a novel framework based on DNR which explicitly addresses its limitations for virtual human avatars. We show the superiority of ANR not only with respect to DNR but also with methods specialized for avatar creation and animation. In two user studies, we observe a clear preference for our avatar model and we demonstrate state-of-the-art performance on quantitative evaluation metrics. Perceptually, we observe better temporal stability, level of detail and plausibility.
TexMesh: Reconstructing Detailed Human Texture and Geometry from RGB-D Video
Aug 29, 2020
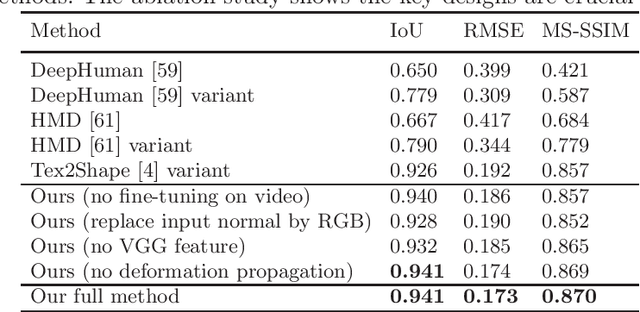
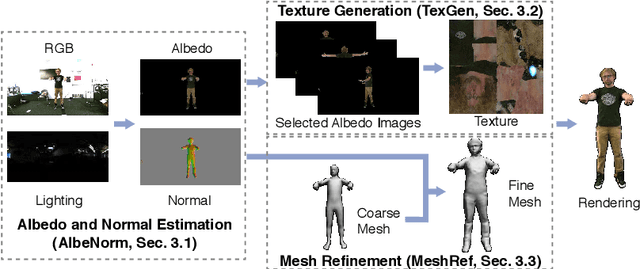

We present TexMesh, a novel approach to reconstruct detailed human meshes with high-resolution full-body texture from RGB-D video. TexMesh enables high quality free-viewpoint rendering of humans. Given the RGB frames, the captured environment map, and the coarse per-frame human mesh from RGB-D tracking, our method reconstructs spatiotemporally consistent and detailed per-frame meshes along with a high-resolution albedo texture. By using the incident illumination we are able to accurately estimate local surface geometry and albedo, which allows us to further use photometric constraints to adapt a synthetically trained model to real-world sequences in a self-supervised manner for detailed surface geometry and high-resolution texture estimation. In practice, we train our models on a short example sequence for self-adaptation and the model runs at interactive framerate afterwards. We validate TexMesh on synthetic and real-world data, and show it outperforms the state of art quantitatively and qualitatively.