 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Un-Kidnappable Robot: Acoustic Localization of Sneaking People
Oct 05, 2023



How easy is it to sneak up on a robot? We examine whether we can detect people using only the incidental sounds they produce as they move, even when they try to be quiet. We collect a robotic dataset of high-quality 4-channel audio paired with 360 degree RGB data of people moving in different indoor settings. We train models that predict if there is a moving person nearby and their location using only audio. We implement our method on a robot, allowing it to track a single person moving quietly with only passive audio sensing. For demonstration videos, see our project page: https://sites.google.com/view/unkidnappable-robot
Visual Contact Pressure Estimation for Grippers in the Wild
Mar 13, 2023



Sensing contact pressure applied by a gripper is useful for autonomous and teleoperated robotic manipulation, but adding tactile sensing to a gripper's surface can be difficult or impractical. If a gripper visibly deforms when forces are applied, contact pressure can be visually estimated using images from an external camera that observes the gripper. While researchers have demonstrated this capability in controlled laboratory settings, prior work has not addressed challenges associated with visual pressure estimation in the wild, where lighting, surfaces, and other factors vary widely. We present a deep learning model and associated methods that enable visual pressure estimation under widely varying conditions. Our model, Visual Pressure Estimation for Robots (ViPER), takes an image from an eye-in-hand camera as input and outputs an image representing the pressure applied by a soft gripper. Our key insight is that force/torque sensing can be used as a weak label to efficiently collect training data in settings where pressure measurements would be difficult to obtain. When trained on this weakly labeled data combined with fully labeled data containing pressure measurements, ViPER outperforms prior methods, enables precision manipulation in cluttered settings, and provides accurate estimates for unseen conditions relevant to in-home use.
Visual Estimation of Fingertip Pressure on Diverse Surfaces using Easily Captured Data
Jan 05, 2023


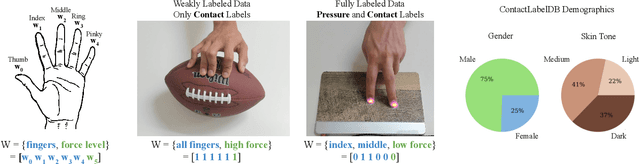
Prior research has shown that deep models can estimate the pressure applied by a hand to a surface based on a single RGB image. Training these models requires high-resolution pressure measurements that are difficult to obtain with physical sensors. Additionally, even experts cannot reliably annotate pressure from images. Thus, data collection is a critical barrier to generalization and improved performance. We present a novel approach that enables training data to be efficiently captured from unmodified surfaces with only an RGB camera and a cooperative participant. Our key insight is that people can be prompted to perform actions that correspond with categorical labels (contact labels) describing contact pressure, such as using a specific fingertip to make low-force contact. We present ContactLabelNet, which visually estimates pressure applied by fingertips. With the use of contact labels, ContactLabelNet achieves improved performance, generalizes to novel surfaces, and outperforms models from prior work.
Force/Torque Sensing for Soft Grippers using an External Camera
Sep 30, 2022

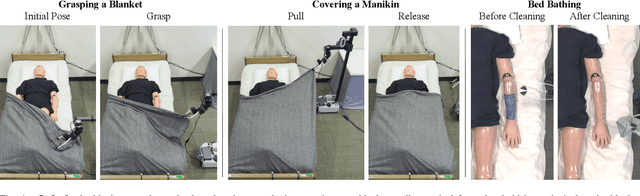
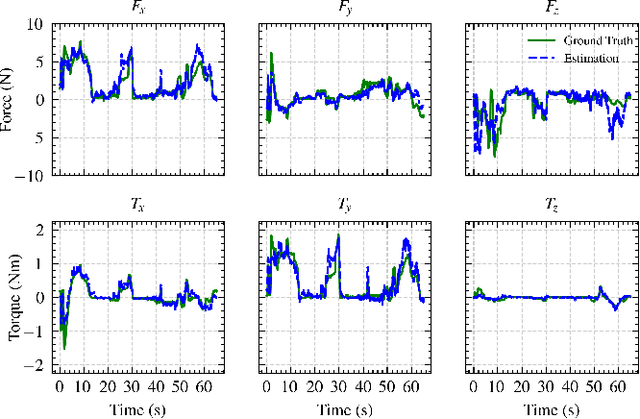
Robotic manipulation can benefit from wrist-mounted force/torque (F/T) sensors, but conventional F/T sensors can be expensive, difficult to install, and damaged by high loads. We present Visual Force/Torque Sensing (VFTS), a method that visually estimates the 6-axis F/T measurement that would be reported by a conventional F/T sensor. In contrast to approaches that sense loads using internal cameras placed behind soft exterior surfaces, our approach uses an external camera with a fisheye lens that observes a soft gripper. VFTS includes a deep learning model that takes a single RGB image as input and outputs a 6-axis F/T estimate. We trained the model with sensor data collected while teleoperating a robot (Stretch RE1 from Hello Robot Inc.) to perform manipulation tasks. VFTS outperformed F/T estimates based on motor currents, generalized to a novel home environment, and supported three autonomous tasks relevant to healthcare: grasping a blanket, pulling a blanket over a manikin, and cleaning a manikin's limbs. VFTS also performed well with a manually operated pneumatic gripper. Overall, our results suggest that an external camera observing a soft gripper can perform useful visual force/torque sensing for a variety of manipulation tasks.
Visual Pressure Estimation and Control for Soft Robotic Grippers
Apr 14, 2022



Soft robotic grippers facilitate contact-rich manipulation, including robust grasping of varied objects. Yet the beneficial compliance of a soft gripper also results in significant deformation that can make precision manipulation challenging. We present visual pressure estimation & control (VPEC), a method that uses a single RGB image of an unmodified soft gripper from an external camera to directly infer pressure applied to the world by the gripper. We present inference results for a pneumatic gripper and a tendon-actuated gripper making contact with a flat surface. We also show that VPEC enables precision manipulation via closed-loop control of inferred pressure. We present results for a mobile manipulator (Stretch RE1 from Hello Robot) using visual servoing to do the following: achieve target pressures when making contact; follow a spatial pressure trajectory; and grasp small objects, including a microSD card, a washer, a penny, and a pill. Overall, our results show that VPEC enables grippers with high compliance to perform precision manipulation.
PressureVision: Estimating Hand Pressure from a Single RGB Image
Mar 19, 2022

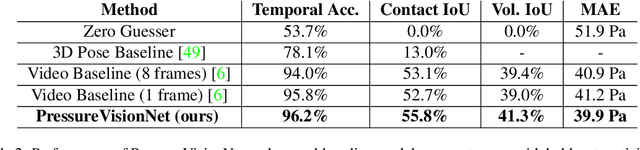

People often interact with their surroundings by applying pressure with their hands. Machine perception of hand pressure has been limited by the challenges of placing sensors between the hand and the contact surface. We explore the possibility of using a conventional RGB camera to infer hand pressure. The central insight is that the application of pressure by a hand results in informative appearance changes. Hands share biomechanical properties that result in similar observable phenomena, such as soft-tissue deformation, blood distribution, hand pose, and cast shadows. We collected videos of 36 participants with diverse skin tone applying pressure to an instrumented planar surface. We then trained a deep model (PressureVisionNet) to infer a pressure image from a single RGB image. Our model infers pressure for participants outside of the training data and outperforms baselines. We also show that the output of our model depends on the appearance of the hand and cast shadows near contact regions. Overall, our results suggest the appearance of a previously unobserved human hand can be used to accurately infer applied pressure.
BodyPressure -- Inferring Body Pose and Contact Pressure from a Depth Image
May 20, 2021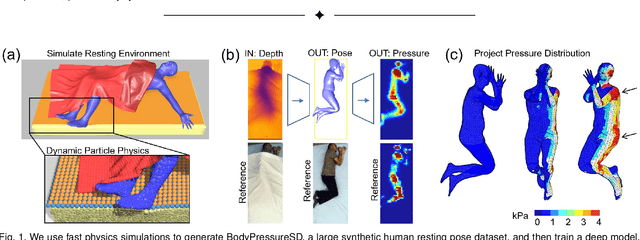
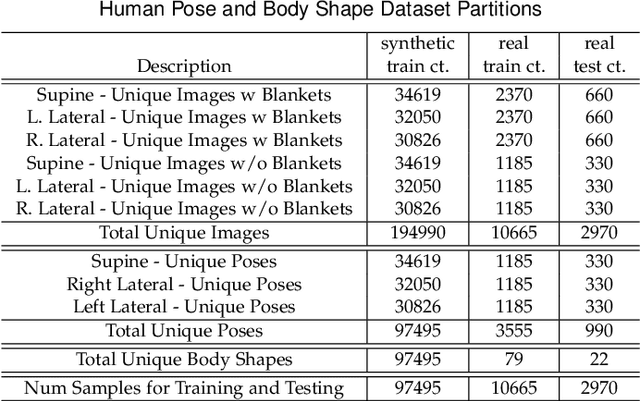

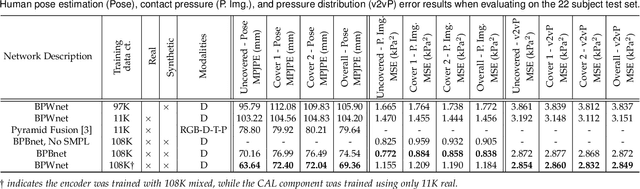
Contact pressure between the human body and its surroundings has important implications. For example, it plays a role in comfort, safety, posture, and health. We present a method that infers contact pressure between a human body and a mattress from a depth image. Specifically, we focus on using a depth image from a downward facing camera to infer pressure on a body at rest in bed occluded by bedding, which is directly applicable to the prevention of pressure injuries in healthcare. Our approach involves augmenting a real dataset with synthetic data generated via a soft-body physics simulation of a human body, a mattress, a pressure sensing mat, and a blanket. We introduce a novel deep network that we trained on an augmented dataset and evaluated with real data. The network contains an embedded human body mesh model and uses a white-box model of depth and pressure image generation. Our network successfully infers body pose, outperforming prior work. It also infers contact pressure across a 3D mesh model of the human body, which is a novel capability, and does so in the presence of occlusion from blankets.
ContactOpt: Optimizing Contact to Improve Grasps
Apr 15, 2021
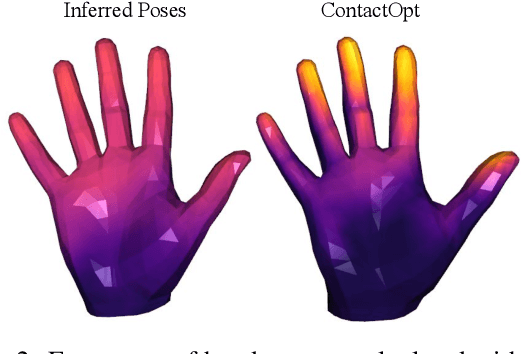
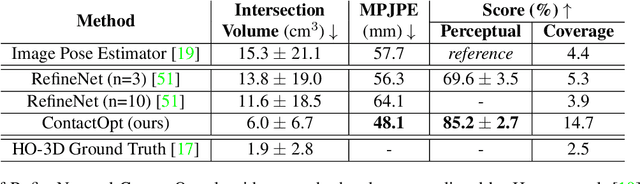

Physical contact between hands and objects plays a critical role in human grasps. We show that optimizing the pose of a hand to achieve expected contact with an object can improve hand poses inferred via image-based methods. Given a hand mesh and an object mesh, a deep model trained on ground truth contact data infers desirable contact across the surfaces of the meshes. Then, ContactOpt efficiently optimizes the pose of the hand to achieve desirable contact using a differentiable contact model. Notably, our contact model encourages mesh interpenetration to approximate deformable soft tissue in the hand. In our evaluations, our methods result in grasps that better match ground truth contact, have lower kinematic error, and are significantly preferred by human participants. Code and models are available online.