 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Modeling with Orbit-Space Particle Flow Matching
May 04, 2026We present Orbit-Space Geometric Probability Paths (OGPP), a particle-native flow-matching framework for generative modeling of particle systems. OGPP is motivated by two insights: (i) particles are defined up to permutation symmetries, so anonymous indexing inflates per-index target variance and yields curved, hard-to-learn flows; and (ii) particles live in physical space, so the flow terminal velocity has physical meaning and can encode geometric attributes, e.g., surface normals. OGPP instantiates three key components: (1) orbit-space canonicalization of the probability-path terminal endpoint, (2) particle index embeddings for role specialization, and (3) geometric probability paths with arc-length-aware terminal velocities that generate normals as a byproduct of the flow. We evaluate OGPP on minimal-surface benchmarks, where it reduces metric error by up to two orders of magnitude in a single inference step; on ShapeNet, where it matches the state of the art with 5x fewer steps and reaches airplane EMD comparable to DiT-3D with 26x fewer parameters and 5x fewer steps; and on single-shape encoding, where it produces normals and reconstructions competitive with 6D generators while operating entirely in 3D.
Functional Mean Flow in Hilbert Space
Nov 17, 2025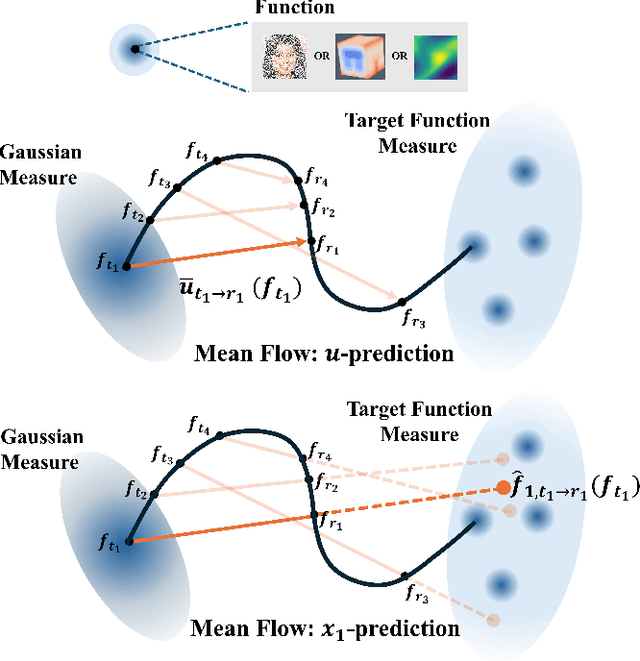
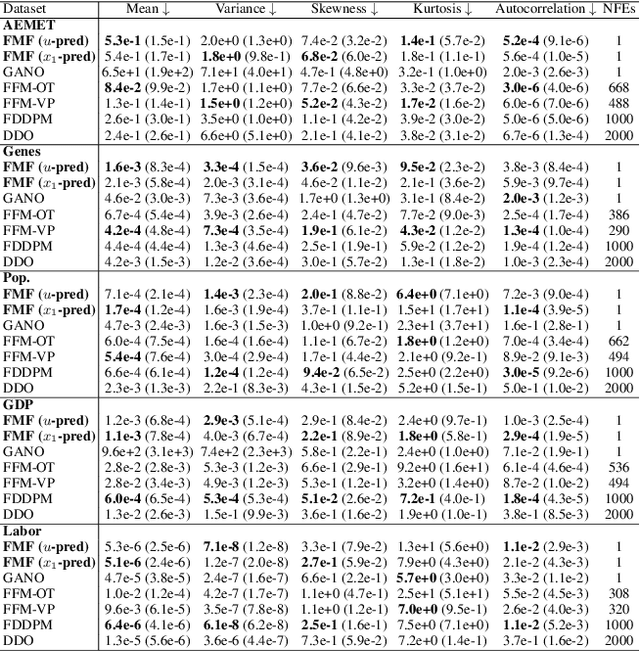

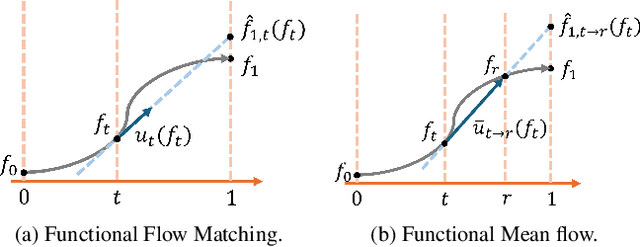
We present Functional Mean Flow (FMF) as a one-step generative model defined in infinite-dimensional Hilbert space. FMF extends the one-step Mean Flow framework to functional domains by providing a theoretical formulation for Functional Flow Matching and a practical implementation for efficient training and sampling. We also introduce an $x_1$-prediction variant that improves stability over the original $u$-prediction form. The resulting framework is a practical one-step Flow Matching method applicable to a wide range of functional data generation tasks such as time series, images, PDEs, and 3D geometry.
Understanding Expectations for a Robotic Guide Dog for Visually Impaired People
Jan 08, 2025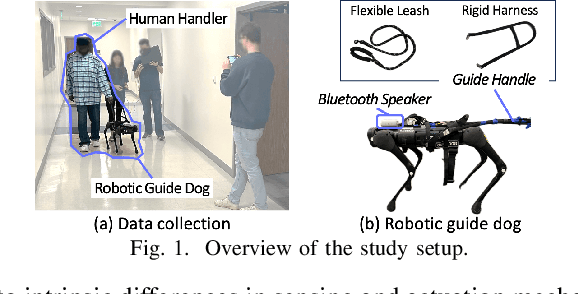
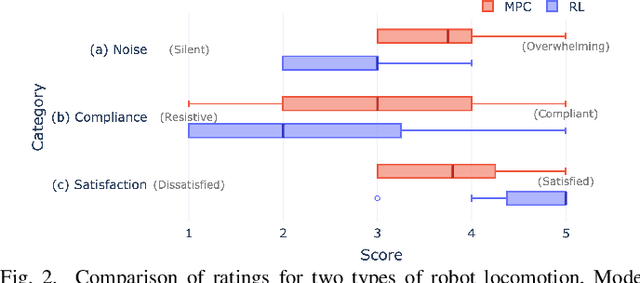
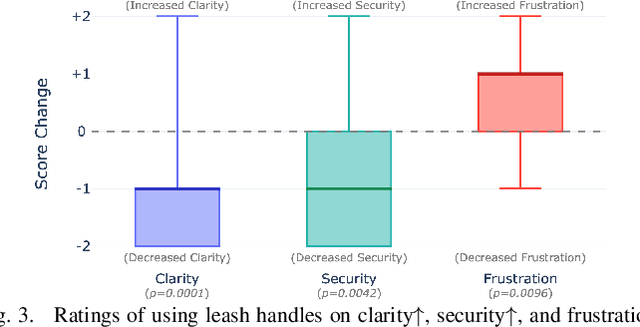
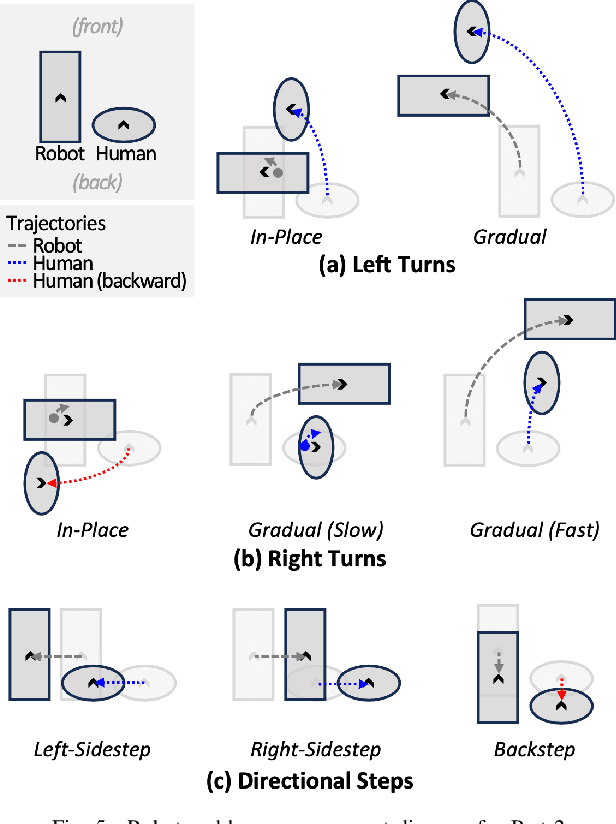
Robotic guide dogs hold significant potential to enhance the autonomy and mobility of blind or visually impaired (BVI) individuals by offering universal assistance over unstructured terrains at affordable costs. However, the design of robotic guide dogs remains underexplored, particularly in systematic aspects such as gait controllers, navigation behaviors, interaction methods, and verbal explanations. Our study addresses this gap by conducting user studies with 18 BVI participants, comprising 15 cane users and three guide dog users. Participants interacted with a quadrupedal robot and provided both quantitative and qualitative feedback. Our study revealed several design implications, such as a preference for a learning-based controller and a rigid handle, gradual turns with asymmetric speeds, semantic communication methods, and explainability. The study also highlighted the importance of customization to support users with diverse backgrounds and preferences, along with practical concerns such as battery life, maintenance, and weather issues. These findings offer valuable insights and design implications for future research and development of robotic guide dogs.
Annotated Hands for Generative Models
Jan 26, 2024Generative models such as GANs and diffusion models have demonstrated impressive image generation capabilities. Despite these successes, these systems are surprisingly poor at creating images with hands. We propose a novel training framework for generative models that substantially improves the ability of such systems to create hand images. Our approach is to augment the training images with three additional channels that provide annotations to hands in the image. These annotations provide additional structure that coax the generative model to produce higher quality hand images. We demonstrate this approach on two different generative models: a generative adversarial network and a diffusion model. We demonstrate our method both on a new synthetic dataset of hand images and also on real photographs that contain hands. We measure the improved quality of the generated hands through higher confidence in finger joint identification using an off-the-shelf hand detector.
Transforming a Quadruped into a Guide Robot for the Visually Impaired: Formalizing Wayfinding, Interaction Modeling, and Safety Mechanism
Jun 24, 2023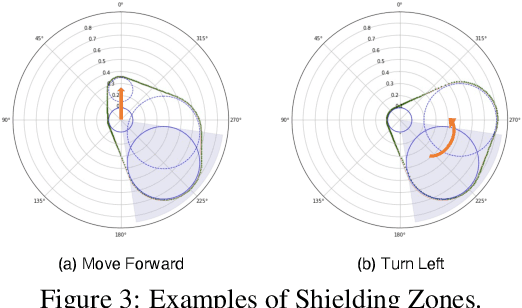
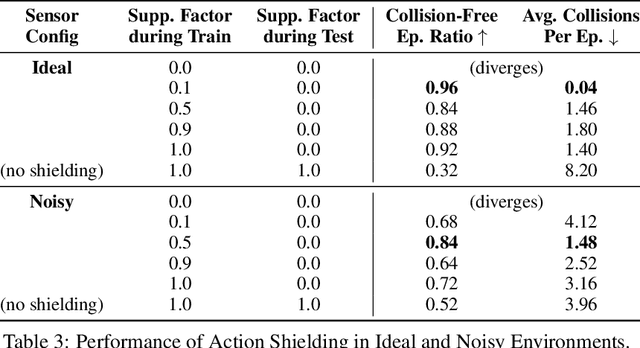
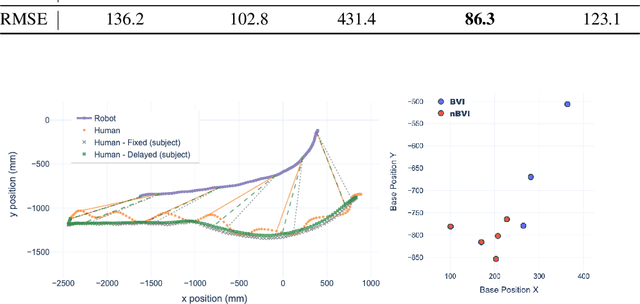

This paper explores the principles for transforming a quadrupedal robot into a guide robot for individuals with visual impairments. A guide robot has great potential to resolve the limited availability of guide animals that are accessible to only two to three percent of the potential blind or visually impaired (BVI) users. To build a successful guide robot, our paper explores three key topics: (1) formalizing the navigation mechanism of a guide dog and a human, (2) developing a data-driven model of their interaction, and (3) improving user safety. First, we formalize the wayfinding task of the human-guide robot team using Markov Decision Processes based on the literature and interviews. Then we collect real human-robot interaction data from three visually impaired and six sighted people and develop an interaction model called the ``Delayed Harness'' to effectively simulate the navigation behaviors of the team. Additionally, we introduce an action shielding mechanism to enhance user safety by predicting and filtering out dangerous actions. We evaluate the developed interaction model and the safety mechanism in simulation, which greatly reduce the prediction errors and the number of collisions, respectively. We also demonstrate the integrated system on a quadrupedal robot with a rigid harness, by guiding users over $100+$~m trajectories.
Simulation and Retargeting of Complex Multi-Character Interactions
May 31, 2023We present a method for reproducing complex multi-character interactions for physically simulated humanoid characters using deep reinforcement learning. Our method learns control policies for characters that imitate not only individual motions, but also the interactions between characters, while maintaining balance and matching the complexity of reference data. Our approach uses a novel reward formulation based on an interaction graph that measures distances between pairs of interaction landmarks. This reward encourages control policies to efficiently imitate the character's motion while preserving the spatial relationships of the interactions in the reference motion. We evaluate our method on a variety of activities, from simple interactions such as a high-five greeting to more complex interactions such as gymnastic exercises, Salsa dancing, and box carrying and throwing. This approach can be used to ``clean-up'' existing motion capture data to produce physically plausible interactions or to retarget motion to new characters with different sizes, kinematics or morphologies while maintaining the interactions in the original data.
Learning to Transfer In-Hand Manipulations Using a Greedy Shape Curriculum
Mar 14, 2023In-hand object manipulation is challenging to simulate due to complex contact dynamics, non-repetitive finger gaits, and the need to indirectly control unactuated objects. Further adapting a successful manipulation skill to new objects with different shapes and physical properties is a similarly challenging problem. In this work, we show that natural and robust in-hand manipulation of simple objects in a dynamic simulation can be learned from a high quality motion capture example via deep reinforcement learning with careful designs of the imitation learning problem. We apply our approach on both single-handed and two-handed dexterous manipulations of diverse object shapes and motions. We then demonstrate further adaptation of the example motion to a more complex shape through curriculum learning on intermediate shapes morphed between the source and target object. While a naive curriculum of progressive morphs often falls short, we propose a simple greedy curriculum search algorithm that can successfully apply to a range of objects such as a teapot, bunny, bottle, train, and elephant.
Auditing Gender Presentation Differences in Text-to-Image Models
Feb 08, 2023Text-to-image models, which can generate high-quality images based on textual input, have recently enabled various content-creation tools. Despite significantly affecting a wide range of downstream applications, the distributions of these generated images are still not fully understood, especially when it comes to the potential stereotypical attributes of different genders. In this work, we propose a paradigm (Gender Presentation Differences) that utilizes fine-grained self-presentation attributes to study how gender is presented differently in text-to-image models. By probing gender indicators in the input text (e.g., "a woman" or "a man"), we quantify the frequency differences of presentation-centric attributes (e.g., "a shirt" and "a dress") through human annotation and introduce a novel metric: GEP. Furthermore, we propose an automatic method to estimate such differences. The automatic GEP metric based on our approach yields a higher correlation with human annotations than that based on existing CLIP scores, consistently across three state-of-the-art text-to-image models. Finally, we demonstrate the generalization ability of our metrics in the context of gender stereotypes related to occupations.
Robot Learning from Randomized Simulations: A Review
Nov 01, 2021


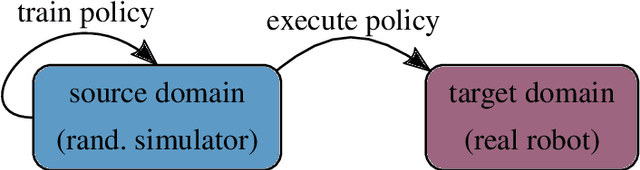
The rise of deep learning has caused a paradigm shift in robotics research, favoring methods that require large amounts of data. It is prohibitively expensive to generate such data sets on a physical platform. Therefore, state-of-the-art approaches learn in simulation where data generation is fast as well as inexpensive and subsequently transfer the knowledge to the real robot (sim-to-real). Despite becoming increasingly realistic, all simulators are by construction based on models, hence inevitably imperfect. This raises the question of how simulators can be modified to facilitate learning robot control policies and overcome the mismatch between simulation and reality, often called the 'reality gap'. We provide a comprehensive review of sim-to-real research for robotics, focusing on a technique named 'domain randomization' which is a method for learning from randomized simulations.
Characterizing Multidimensional Capacitive Servoing for Physical Human-Robot Interaction
May 25, 2021

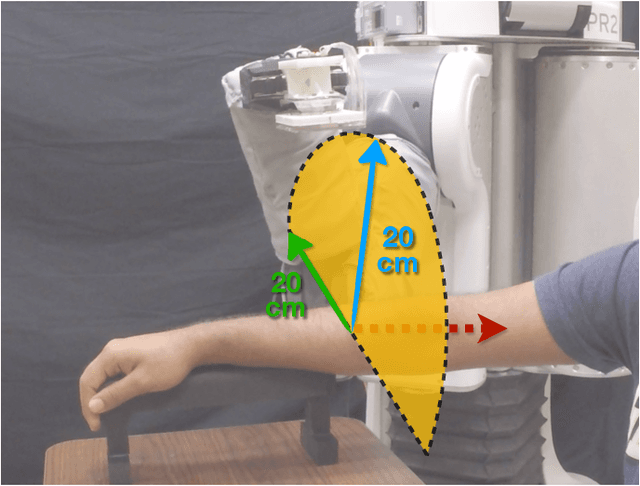
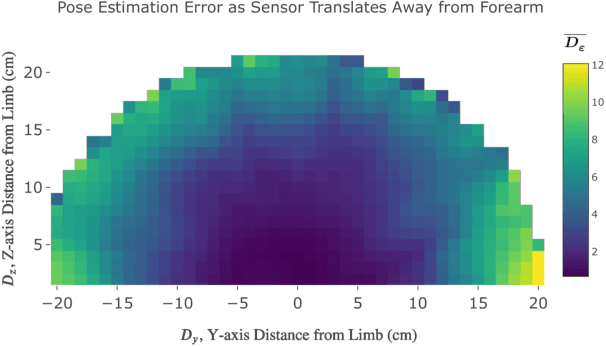
Towards the goal of robots performing robust and intelligent physical interactions with people, it is crucial that robots are able to accurately sense the human body, follow trajectories around the body, and track human motion. This study introduces a capacitive servoing control scheme that allows a robot to sense and navigate around human limbs during close physical interactions. Capacitive servoing leverages temporal measurements from a multi-electrode capacitive sensor array mounted on a robot's end effector to estimate the relative position and orientation (pose) of a nearby human limb. Capacitive servoing then uses these human pose estimates from a data-driven pose estimator within a feedback control loop in order to maneuver the robot's end effector around the surface of a human limb. We provide a design overview of capacitive sensors for human-robot interaction and then investigate the performance and generalization of capacitive servoing through an experiment with 12 human participants. The results indicate that multidimensional capacitive servoing enables a robot's end effector to move proximally or distally along human limbs while adapting to human pose. Using a cross-validation experiment, results further show that capacitive servoing generalizes well across people with different body size.