 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBodyMAP -- Jointly Predicting Body Mesh and 3D Applied Pressure Map for People in Bed
Apr 04, 2024



Accurately predicting the 3D human posture and the pressure exerted on the body for people resting in bed, visualized as a body mesh (3D pose & shape) with a 3D pressure map, holds significant promise for healthcare applications, particularly, in the prevention of pressure ulcers. Current methods focus on singular facets of the problem -- predicting only 2D/3D poses, generating 2D pressure images, predicting pressure only for certain body regions instead of the full body, or forming indirect approximations to the 3D pressure map. In contrast, we introduce BodyMAP, which jointly predicts the human body mesh and 3D applied pressure map across the entire human body. Our network leverages multiple visual modalities, incorporating both a depth image of a person in bed and its corresponding 2D pressure image acquired from a pressure-sensing mattress. The 3D pressure map is represented as a pressure value at each mesh vertex and thus allows for precise localization of high-pressure regions on the body. Additionally, we present BodyMAP-WS, a new formulation of pressure prediction in which we implicitly learn pressure in 3D by aligning sensed 2D pressure images with a differentiable 2D projection of the predicted 3D pressure maps. In evaluations with real-world human data, our method outperforms the current state-of-the-art technique by 25% on both body mesh and 3D applied pressure map prediction tasks for people in bed.
Assistive Tele-op: Leveraging Transformers to Collect Robotic Task Demonstrations
Dec 09, 2021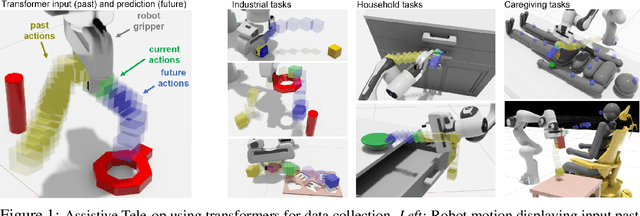
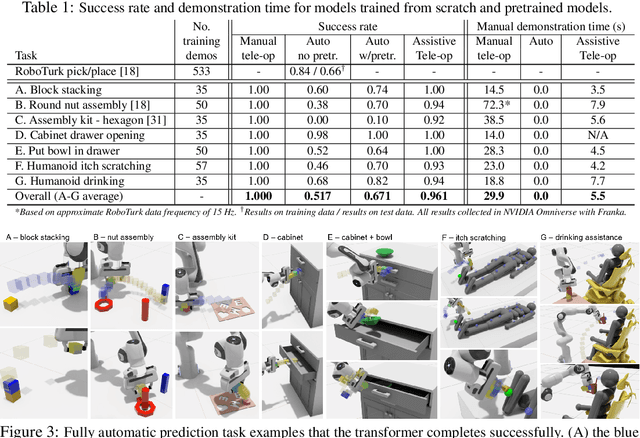
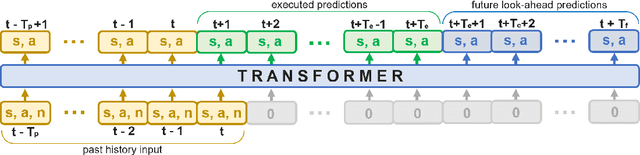
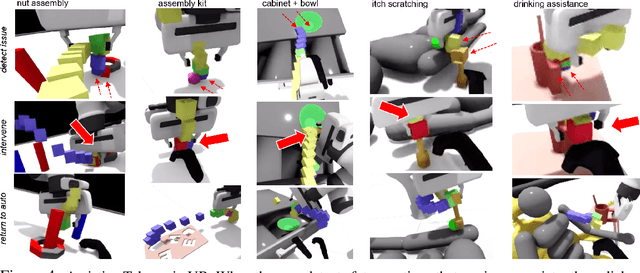
Sharing autonomy between robots and human operators could facilitate data collection of robotic task demonstrations to continuously improve learned models. Yet, the means to communicate intent and reason about the future are disparate between humans and robots. We present Assistive Tele-op, a virtual reality (VR) system for collecting robot task demonstrations that displays an autonomous trajectory forecast to communicate the robot's intent. As the robot moves, the user can switch between autonomous and manual control when desired. This allows users to collect task demonstrations with both a high success rate and with greater ease than manual teleoperation systems. Our system is powered by transformers, which can provide a window of potential states and actions far into the future -- with almost no added computation time. A key insight is that human intent can be injected at any location within the transformer sequence if the user decides that the model-predicted actions are inappropriate. At every time step, the user can (1) do nothing and allow autonomous operation to continue while observing the robot's future plan sequence, or (2) take over and momentarily prescribe a different set of actions to nudge the model back on track. We host the videos and other supplementary material at https://sites.google.com/view/assistive-teleop.
The Design of Stretch: A Compact, Lightweight Mobile Manipulator for Indoor Human Environments
Sep 22, 2021


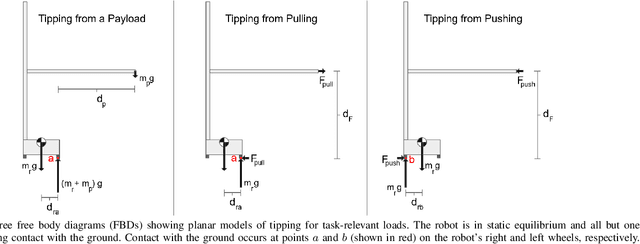
Mobile manipulators for indoor human environments can serve as versatile devices that perform a variety of tasks, yet adoption of this technology has been limited. Reducing size, weight, and cost could facilitate adoption, but risks restricting capabilities. We present a novel design that reduces size, weight, and cost, while still performing a variety of tasks. The core design consists of a two-wheeled differential-drive mobile base, a lift, and a telescoping arm configured to achieve Cartesian motion at the end of the arm. Design extensions include a 1 degree-of-freedom (DOF) wrist to stow a tool, a 2-DOF dexterous wrist to pitch and roll a tool, and a compliant gripper. We justify our design with mathematical models of static stability that relate the robot's size and weight to its workspace, payload, and applied forces. We also provide empirical support by teleoperating and autonomously controlling a commercial robot based on our design (the Stretch RE1 from Hello Robot Inc.) to perform tasks in real homes.
Characterizing Multidimensional Capacitive Servoing for Physical Human-Robot Interaction
May 25, 2021

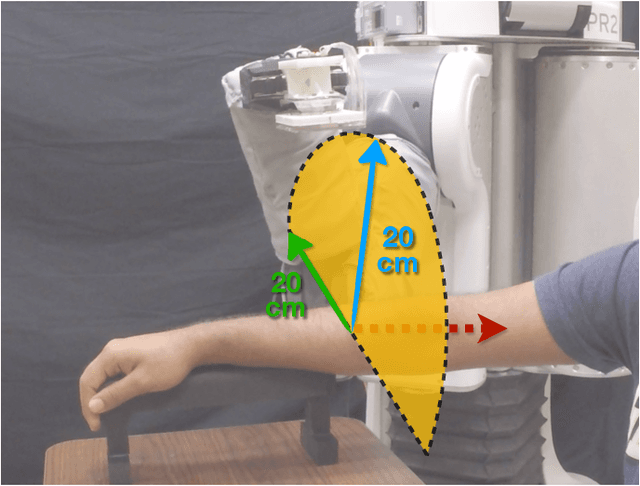
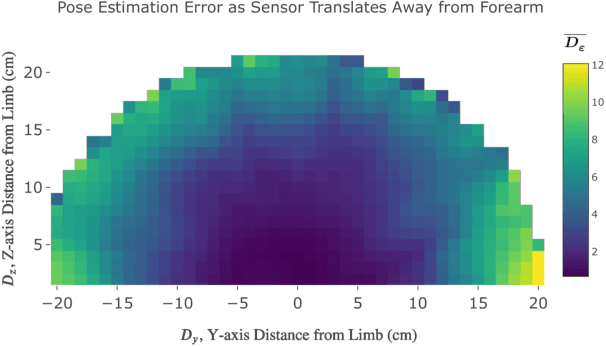
Towards the goal of robots performing robust and intelligent physical interactions with people, it is crucial that robots are able to accurately sense the human body, follow trajectories around the body, and track human motion. This study introduces a capacitive servoing control scheme that allows a robot to sense and navigate around human limbs during close physical interactions. Capacitive servoing leverages temporal measurements from a multi-electrode capacitive sensor array mounted on a robot's end effector to estimate the relative position and orientation (pose) of a nearby human limb. Capacitive servoing then uses these human pose estimates from a data-driven pose estimator within a feedback control loop in order to maneuver the robot's end effector around the surface of a human limb. We provide a design overview of capacitive sensors for human-robot interaction and then investigate the performance and generalization of capacitive servoing through an experiment with 12 human participants. The results indicate that multidimensional capacitive servoing enables a robot's end effector to move proximally or distally along human limbs while adapting to human pose. Using a cross-validation experiment, results further show that capacitive servoing generalizes well across people with different body size.
BodyPressure -- Inferring Body Pose and Contact Pressure from a Depth Image
May 20, 2021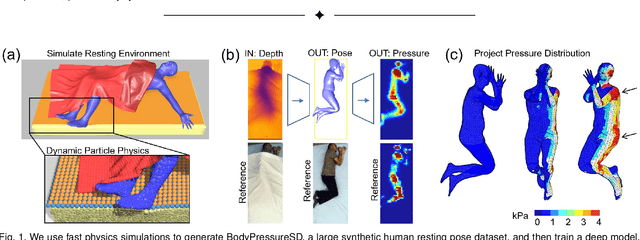
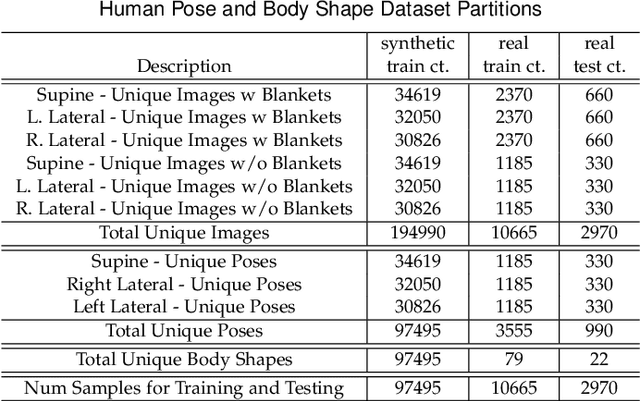

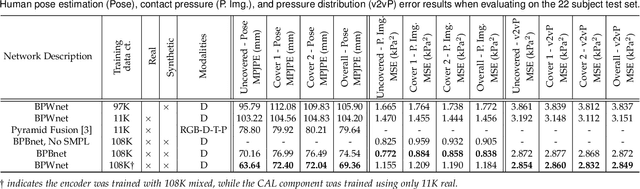
Contact pressure between the human body and its surroundings has important implications. For example, it plays a role in comfort, safety, posture, and health. We present a method that infers contact pressure between a human body and a mattress from a depth image. Specifically, we focus on using a depth image from a downward facing camera to infer pressure on a body at rest in bed occluded by bedding, which is directly applicable to the prevention of pressure injuries in healthcare. Our approach involves augmenting a real dataset with synthetic data generated via a soft-body physics simulation of a human body, a mattress, a pressure sensing mat, and a blanket. We introduce a novel deep network that we trained on an augmented dataset and evaluated with real data. The network contains an embedded human body mesh model and uses a white-box model of depth and pressure image generation. Our network successfully infers body pose, outperforming prior work. It also infers contact pressure across a 3D mesh model of the human body, which is a novel capability, and does so in the presence of occlusion from blankets.
Material Recognition via Heat Transfer Given Ambiguous Initial Conditions
Dec 03, 2020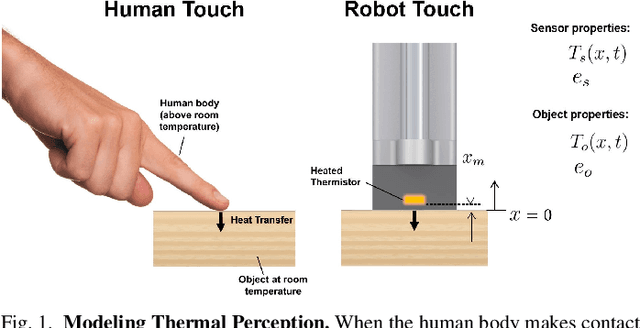
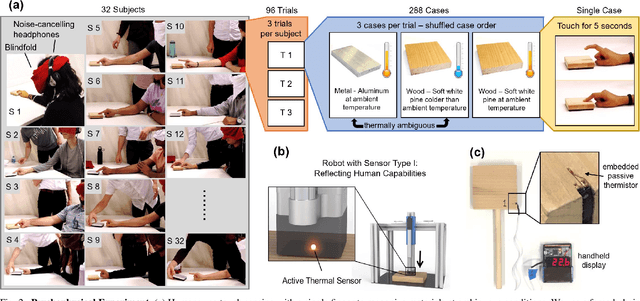
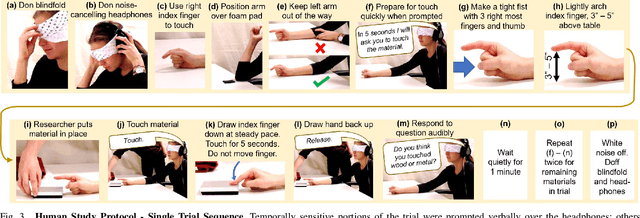
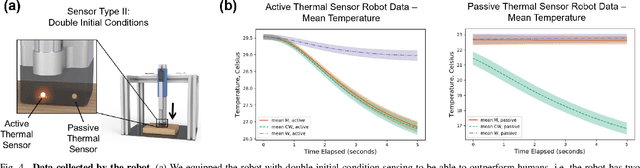
Humans and robots can recognize materials with distinct thermal effusivities by making physical contact and observing temperatures during heat transfer. This works well with room temperature materials and humans and robots at human body temperatures. Past research has shown that cooling or heating a material can result in temperatures that are similar to contact with another material. To thoroughly investigate this perceptual ambiguity, we designed a psychophysical experiment in which a participant discriminates between two materials given ambiguous initial conditions. We conducted a study with 32 human participants and a robot. Humans and the robot confused the materials. We also found that robots can overcome this ambiguity using two temperature sensors with different temperatures prior to contact. We support this conclusion based on a mathematical proof using a heat transfer model and empirical results in which a robot achieved 100% accuracy compared to 5% human accuracy. Our results also indicate that robots can use subtle cues to distinguish thermally ambiguous materials with a single temperature sensor. Overall, our work provides insights into challenging conditions for material recognition via heat transfer, and suggests methods by which robots can overcome these challenges to outperform humans.
Bodies at Rest: 3D Human Pose and Shape Estimation from a Pressure Image using Synthetic Data
Apr 02, 2020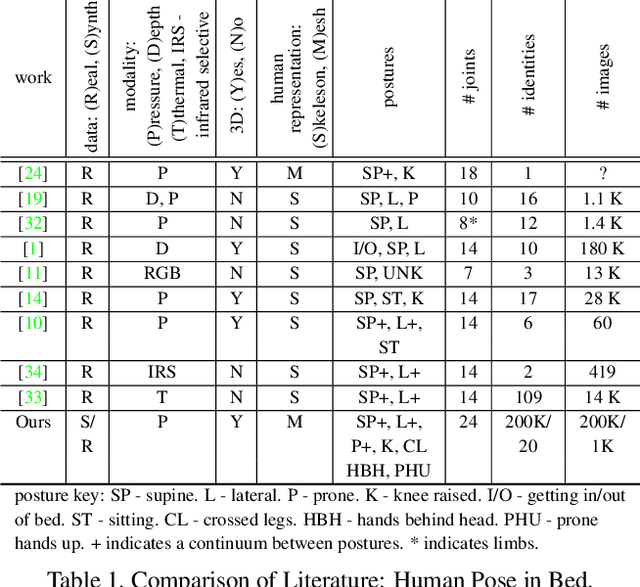

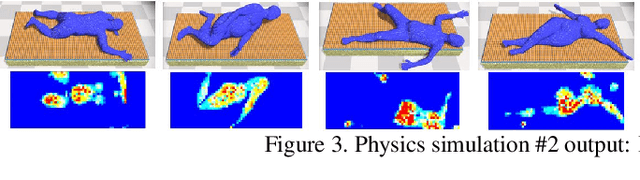
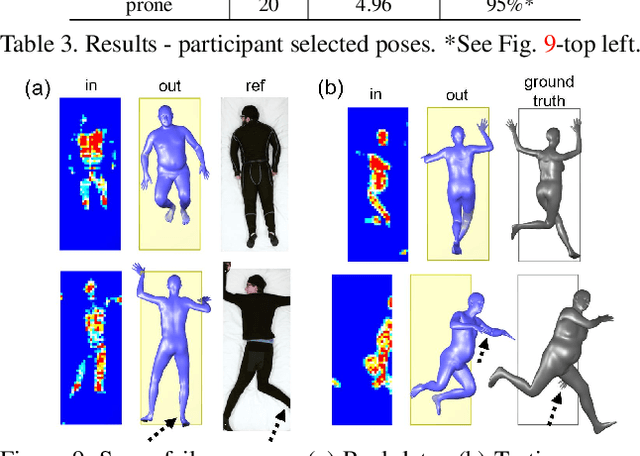
People spend a substantial part of their lives at rest in bed. 3D human pose and shape estimation for this activity would have numerous beneficial applications, yet line-of-sight perception is complicated by occlusion from bedding. Pressure sensing mats are a promising alternative, but training data is challenging to collect at scale. We describe a physics-based method that simulates human bodies at rest in a bed with a pressure sensing mat, and present PressurePose, a synthetic dataset with 206K pressure images with 3D human poses and shapes. We also present PressureNet, a deep learning model that estimates human pose and shape given a pressure image and gender. PressureNet incorporates a pressure map reconstruction (PMR) network that models pressure image generation to promote consistency between estimated 3D body models and pressure image input. In our evaluations, PressureNet performed well with real data from participants in diverse poses, even though it had only been trained with synthetic data. When we ablated the PMR network, performance dropped substantially.
Multidimensional Capacitive Sensing for Robot-Assisted Dressing and Bathing
Apr 03, 2019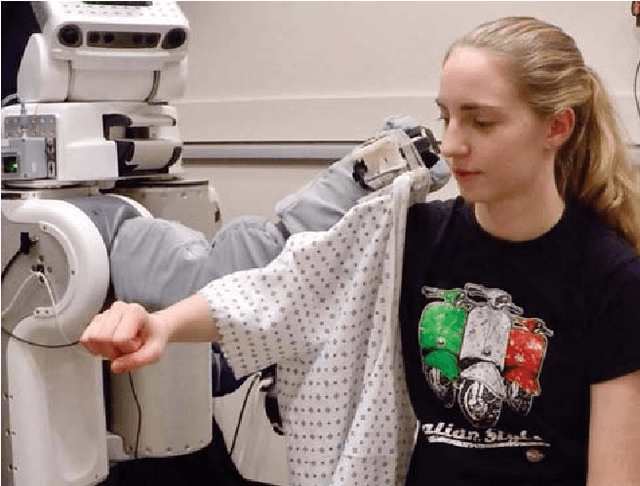
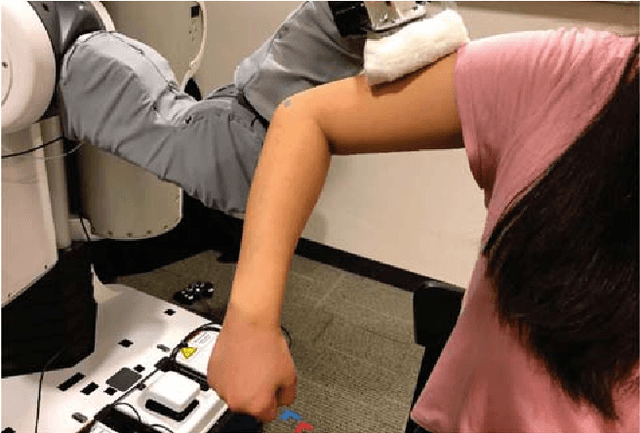
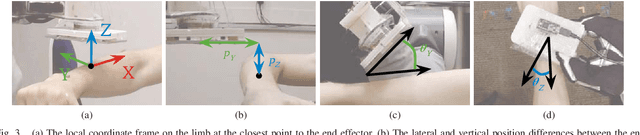

Robotic assistance presents an opportunity to benefit the lives of many adults with physical disabilities, yet accurately sensing the human body and tracking human motion remain difficult for robots. We present a multidimensional capacitive sensing technique capable of sensing the local pose of a human limb in real time. This sensing approach is unaffected by many visual occlusions that obscure sight of a person's body during robotic assistance, while also allowing a robot to sense the human body through some conductive materials, such as wet cloth. Given measurements from this capacitive sensor, we train a neural network model to estimate the relative vertical and lateral position to the closest point on a person's limb, as well as the pitch and yaw orientation between a robot's end effector and the central axis of the limb. We demonstrate that a PR2 robot can use this sensing approach to assist with two activities of daily living-dressing and bathing. Our robot pulled the sleeve of a hospital gown onto participants' right arms, while using capacitive sensing with feedback control to track human motion. When assisting with bathing, the robot used capacitive sensing with a soft wet washcloth to follow the contours of a participant's limbs and clean the surface of the body. Overall, we find that multidimensional capacitive sensing presents a promising approach for robots to sense and track the human body during assistive tasks that require physical human-robot interaction.
3D Human Pose Estimation on a Configurable Bed from a Pressure Image
Aug 29, 2018
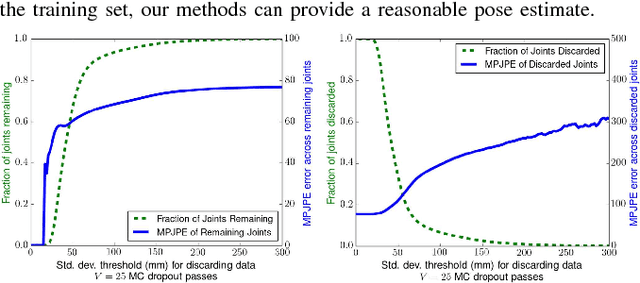
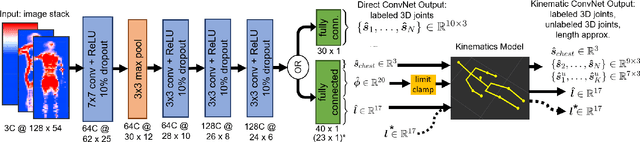
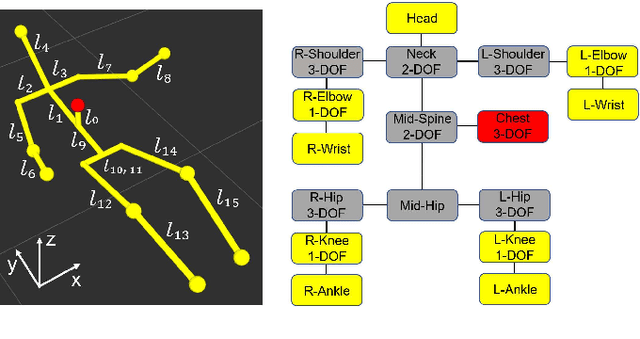
Robots have the potential to assist people in bed, such as in healthcare settings, yet bedding materials like sheets and blankets can make observation of the human body difficult for robots. A pressure-sensing mat on a bed can provide pressure images that are relatively insensitive to bedding materials. However, prior work on estimating human pose from pressure images has been restricted to 2D pose estimates and flat beds. In this work, we present two convolutional neural networks to estimate the 3D joint positions of a person in a configurable bed from a single pressure image. The first network directly outputs 3D joint positions, while the second outputs a kinematic model that includes estimated joint angles and limb lengths. We evaluated our networks on data from 17 human participants with two bed configurations: supine and seated. Our networks achieved a mean joint position error of 77 mm when tested with data from people outside the training set, outperforming several baselines. We also present a simple mechanical model that provides insight into ambiguity associated with limbs raised off of the pressure mat, and demonstrate that Monte Carlo dropout can be used to estimate pose confidence in these situations. Finally, we provide a demonstration in which a mobile manipulator uses our network's estimated kinematic model to reach a location on a person's body in spite of the person being seated in a bed and covered by a blanket.
Deep Haptic Model Predictive Control for Robot-Assisted Dressing
Oct 27, 2017



Robot-assisted dressing offers an opportunity to benefit the lives of many people with disabilities, such as some older adults. However, robots currently lack common sense about the physical implications of their actions on people. The physical implications of dressing are complicated by non-rigid garments, which can result in a robot indirectly applying high forces to a person's body. We present a deep recurrent model that, when given a proposed action by the robot, predicts the forces a garment will apply to a person's body. We also show that a robot can provide better dressing assistance by using this model with model predictive control. The predictions made by our model only use haptic and kinematic observations from the robot's end effector, which are readily attainable. Collecting training data from real world physical human-robot interaction can be time consuming, costly, and put people at risk. Instead, we train our predictive model using data collected in an entirely self-supervised fashion from a physics-based simulation. We evaluated our approach with a PR2 robot that attempted to pull a hospital gown onto the arms of 10 human participants. With a 0.2s prediction horizon, our controller succeeded at high rates and lowered applied force while navigating the garment around a persons fist and elbow without getting caught. Shorter prediction horizons resulted in significantly reduced performance with the sleeve catching on the participants' fists and elbows, demonstrating the value of our model's predictions. These behaviors of mitigating catches emerged from our deep predictive model and the controller objective function, which primarily penalizes high forces.