 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemorize Theorems, Not Instances: Probing SFT Generalization through Mathematical Reasoning
May 10, 2026Supervised Fine-Tuning (SFT) is widely used for task-specific adaptation, yet recent work shows it systematically undermines reasoning generalization. We argue the root cause is not memorization itself, but its target: vanilla SFT drives models to exploit and memorize spurious surface correlations in problem-solution pairs, leaving them brittle to superficial input variations. To address this, we propose Theorem-SFT, which reorients supervision toward explicit theorem application by teaching models how rules are invoked rather than what answers look like. Theorem-SFT yields consistent gains across benchmarks and model families: +8.8% on MATH (LLaMA3.2-3B-Instruct) and +20.27% on GeoQA (Qwen2.5-VL-7B-Instruct) without modality-specific re-training. Fine-tuning MLP layers alone matches full-layers performance, implicating feed-forward components as the primary locus of reasoning rules. Our findings reframe the debate: Generalization failures stem not from memorization as a mechanism, but from memorizing the wrong inductive targets.
Large Vision-Language Models Get Lost in Attention
May 07, 2026Despite the rapid evolution of training paradigms, the decoder backbone of large vision--language models (LVLMs) remains fundamentally rooted in the residual-connection Transformer architecture. Therefore, deciphering the distinct roles of internal modules is critical for understanding model mechanics and guiding architectural optimization. While prior statistical approaches have provided valuable attribution-based insights, they often lack a unified theoretical basis. To bridge this gap, we propose a unified framework grounded in information theory and geometry to quantify the geometric and entropic nature of residual updates. Applying this unified framework reveals a fundamental functional decoupling: Attention acts as a subspace-preserving operator focused on reconfiguration, whereas FFNs serve as subspace-expanding operators driving semantic innovation. Strikingly, further experiments demonstrate that replacing learned attention weights with predefined values (e.g., Gaussian noise) yields comparable or even superior performance across a majority of datasets relative to vanilla models. These results expose severe misallocation and redundancy in current mechanisms, suggesting that state-of-the-art LVLMs effectively ``get lost in attention'' rather than efficiently leveraging visual context.
CoPHo: Classifier-guided Conditional Topology Generation with Persistent Homology
Dec 17, 2025The structure of topology underpins much of the research on performance and robustness, yet available topology data are typically scarce, necessitating the generation of synthetic graphs with desired properties for testing or release. Prior diffusion-based approaches either embed conditions into the diffusion model, requiring retraining for each attribute and hindering real-time applicability, or use classifier-based guidance post-training, which does not account for topology scale and practical constraints. In this paper, we show from a discrete perspective that gradients from a pre-trained graph-level classifier can be incorporated into the discrete reverse diffusion posterior to steer generation toward specified structural properties. Based on this insight, we propose Classifier-guided Conditional Topology Generation with Persistent Homology (CoPHo), which builds a persistent homology filtration over intermediate graphs and interprets features as guidance signals that steer generation toward the desired properties at each denoising step. Experiments on four generic/network datasets demonstrate that CoPHo outperforms existing methods at matching target metrics, and we further validate its transferability on the QM9 molecular dataset.
GEN3D: Generating Domain-Free 3D Scenes from a Single Image
Nov 18, 2025Despite recent advancements in neural 3D reconstruction, the dependence on dense multi-view captures restricts their broader applicability. Additionally, 3D scene generation is vital for advancing embodied AI and world models, which depend on diverse, high-quality scenes for learning and evaluation. In this work, we propose Gen3d, a novel method for generation of high-quality, wide-scope, and generic 3D scenes from a single image. After the initial point cloud is created by lifting the RGBD image, Gen3d maintains and expands its world model. The 3D scene is finalized through optimizing a Gaussian splatting representation. Extensive experiments on diverse datasets demonstrate the strong generalization capability and superior performance of our method in generating a world model and Synthesizing high-fidelity and consistent novel views.
Clink! Chop! Thud! -- Learning Object Sounds from Real-World Interactions
Oct 02, 2025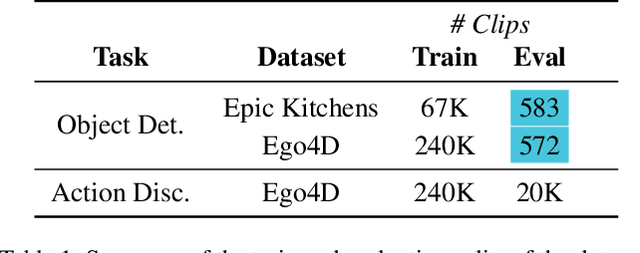

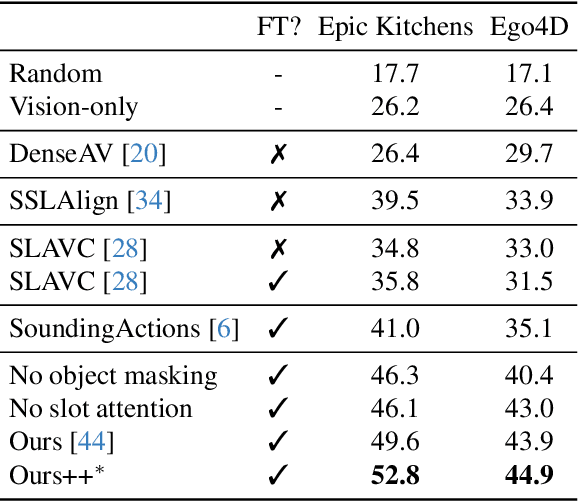
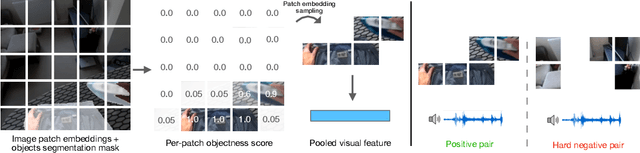
Can a model distinguish between the sound of a spoon hitting a hardwood floor versus a carpeted one? Everyday object interactions produce sounds unique to the objects involved. We introduce the sounding object detection task to evaluate a model's ability to link these sounds to the objects directly involved. Inspired by human perception, our multimodal object-aware framework learns from in-the-wild egocentric videos. To encourage an object-centric approach, we first develop an automatic pipeline to compute segmentation masks of the objects involved to guide the model's focus during training towards the most informative regions of the interaction. A slot attention visual encoder is used to further enforce an object prior. We demonstrate state of the art performance on our new task along with existing multimodal action understanding tasks.
SDP: Spiking Diffusion Policy for Robotic Manipulation with Learnable Channel-Wise Membrane Thresholds
Sep 17, 2024



This paper introduces a Spiking Diffusion Policy (SDP) learning method for robotic manipulation by integrating Spiking Neurons and Learnable Channel-wise Membrane Thresholds (LCMT) into the diffusion policy model, thereby enhancing computational efficiency and achieving high performance in evaluated tasks. Specifically, the proposed SDP model employs the U-Net architecture as the backbone for diffusion learning within the Spiking Neural Network (SNN). It strategically places residual connections between the spike convolution operations and the Leaky Integrate-and-Fire (LIF) nodes, thereby preventing disruptions to the spiking states. Additionally, we introduce a temporal encoding block and a temporal decoding block to transform static and dynamic data with timestep $T_S$ into each other, enabling the transmission of data within the SNN in spike format. Furthermore, we propose LCMT to enable the adaptive acquisition of membrane potential thresholds, thereby matching the conditions of varying membrane potentials and firing rates across channels and avoiding the cumbersome process of manually setting and tuning hyperparameters. Evaluating the SDP model on seven distinct tasks with SNN timestep $T_S=4$, we achieve results comparable to those of the ANN counterparts, along with faster convergence speeds than the baseline SNN method. This improvement is accompanied by a reduction of 94.3\% in dynamic energy consumption estimated on 45nm hardware.
AdaViPro: Region-based Adaptive Visual Prompt for Large-Scale Models Adapting
Mar 20, 2024



Recently, prompt-based methods have emerged as a new alternative `parameter-efficient fine-tuning' paradigm, which only fine-tunes a small number of additional parameters while keeping the original model frozen. However, despite achieving notable results, existing prompt methods mainly focus on `what to add', while overlooking the equally important aspect of `where to add', typically relying on the manually crafted placement. To this end, we propose a region-based Adaptive Visual Prompt, named AdaViPro, which integrates the `where to add' optimization of the prompt into the learning process. Specifically, we reconceptualize the `where to add' optimization as a problem of regional decision-making. During inference, AdaViPro generates a regionalized mask map for the whole image, which is composed of 0 and 1, to designate whether to apply or discard the prompt in each specific area. Therefore, we employ Gumbel-Softmax sampling to enable AdaViPro's end-to-end learning through standard back-propagation. Extensive experiments demonstrate that our AdaViPro yields new efficiency and accuracy trade-offs for adapting pre-trained models.
The Un-Kidnappable Robot: Acoustic Localization of Sneaking People
Oct 05, 2023



How easy is it to sneak up on a robot? We examine whether we can detect people using only the incidental sounds they produce as they move, even when they try to be quiet. We collect a robotic dataset of high-quality 4-channel audio paired with 360 degree RGB data of people moving in different indoor settings. We train models that predict if there is a moving person nearby and their location using only audio. We implement our method on a robot, allowing it to track a single person moving quietly with only passive audio sensing. For demonstration videos, see our project page: https://sites.google.com/view/unkidnappable-robot
View while Moving: Efficient Video Recognition in Long-untrimmed Videos
Aug 09, 2023



Recent adaptive methods for efficient video recognition mostly follow the two-stage paradigm of "preview-then-recognition" and have achieved great success on multiple video benchmarks. However, this two-stage paradigm involves two visits of raw frames from coarse-grained to fine-grained during inference (cannot be parallelized), and the captured spatiotemporal features cannot be reused in the second stage (due to varying granularity), being not friendly to efficiency and computation optimization. To this end, inspired by human cognition, we propose a novel recognition paradigm of "View while Moving" for efficient long-untrimmed video recognition. In contrast to the two-stage paradigm, our paradigm only needs to access the raw frame once. The two phases of coarse-grained sampling and fine-grained recognition are combined into unified spatiotemporal modeling, showing great performance. Moreover, we investigate the properties of semantic units in video and propose a hierarchical mechanism to efficiently capture and reason about the unit-level and video-level temporal semantics in long-untrimmed videos respectively. Extensive experiments on both long-untrimmed and short-trimmed videos demonstrate that our approach outperforms state-of-the-art methods in terms of accuracy as well as efficiency, yielding new efficiency and accuracy trade-offs for video spatiotemporal modeling.
Improving Social Media Popularity Prediction with Multiple Post Dependencies
Jul 28, 2023



Social Media Popularity Prediction has drawn a lot of attention because of its profound impact on many different applications, such as recommendation systems and multimedia advertising. Despite recent efforts to leverage the content of social media posts to improve prediction accuracy, many existing models fail to fully exploit the multiple dependencies between posts, which are important to comprehensively extract content information from posts. To tackle this problem, we propose a novel prediction framework named Dependency-aware Sequence Network (DSN) that exploits both intra- and inter-post dependencies. For intra-post dependency, DSN adopts a multimodal feature extractor with an efficient fine-tuning strategy to obtain task-specific representations from images and textual information of posts. For inter-post dependency, DSN uses a hierarchical information propagation method to learn category representations that could better describe the difference between posts. DSN also exploits recurrent networks with a series of gating layers for more flexible local temporal processing abilities and multi-head attention for long-term dependencies. The experimental results on the Social Media Popularity Dataset demonstrate the superiority of our method compared to existing state-of-the-art models.