 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMask-Guided Discovery of Semantic Manifolds in Generative Models
May 15, 2021



Advances in the realm of Generative Adversarial Networks (GANs) have led to architectures capable of producing amazingly realistic images such as StyleGAN2, which, when trained on the FFHQ dataset, generates images of human faces from random vectors in a lower-dimensional latent space. Unfortunately, this space is entangled - translating a latent vector along its axes does not correspond to a meaningful transformation in the output space (e.g., smiling mouth, squinting eyes). The model behaves as a black box, providing neither control over its output nor insight into the structures it has learned from the data. We present a method to explore the manifolds of changes of spatially localized regions of the face. Our method discovers smoothly varying sequences of latent vectors along these manifolds suitable for creating animations. Unlike existing disentanglement methods that either require labelled data or explicitly alter internal model parameters, our method is an optimization-based approach guided by a custom loss function and manually defined region of change. Our code is open-sourced, which can be found, along with supplementary results, on our project page: https://github.com/bmolab/masked-gan-manifold
Fourier-CPPNs for Image Synthesis
Sep 20, 2019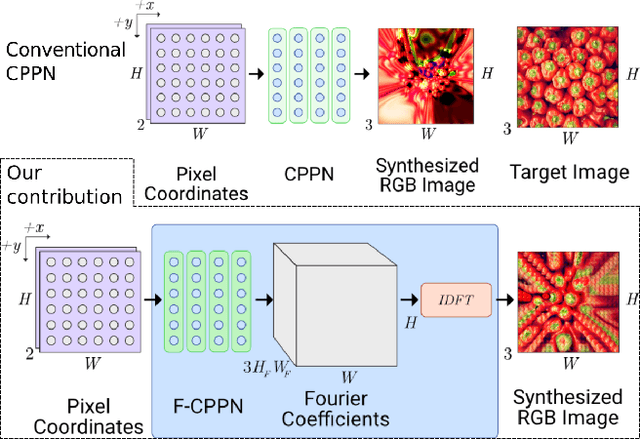



Compositional Pattern Producing Networks (CPPNs) are differentiable networks that independently map (x, y) pixel coordinates to (r, g, b) colour values. Recently, CPPNs have been used for creating interesting imagery for creative purposes, e.g., neural art. However their architecture biases generated images to be overly smooth, lacking high-frequency detail. In this work, we extend CPPNs to explicitly model the frequency information for each pixel output, capturing frequencies beyond the DC component. We show that our Fourier-CPPNs (F-CPPNs) provide improved visual detail for image synthesis.