 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Neural Cellular Automata
Nov 02, 2022Recent extensions of Cellular Automata (CA) have incorporated key ideas from modern deep learning, dramatically extending their capabilities and catalyzing a new family of Neural Cellular Automata (NCA) techniques. Inspired by Transformer-based architectures, our work presents a new class of $\textit{attention-based}$ NCAs formed using a spatially localized$\unicode{x2014}$yet globally organized$\unicode{x2014}$self-attention scheme. We introduce an instance of this class named $\textit{Vision Transformer Cellular Automata}$ (ViTCA). We present quantitative and qualitative results on denoising autoencoding across six benchmark datasets, comparing ViTCA to a U-Net, a U-Net-based CA baseline (UNetCA), and a Vision Transformer (ViT). When comparing across architectures configured to similar parameter complexity, ViTCA architectures yield superior performance across all benchmarks and for nearly every evaluation metric. We present an ablation study on various architectural configurations of ViTCA, an analysis of its effect on cell states, and an investigation on its inductive biases. Finally, we examine its learned representations via linear probes on its converged cell state hidden representations, yielding, on average, superior results when compared to our U-Net, ViT, and UNetCA baselines.
Fourier-CPPNs for Image Synthesis
Sep 20, 2019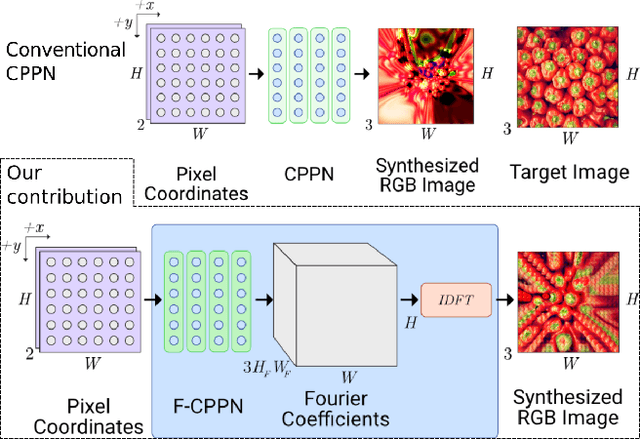



Compositional Pattern Producing Networks (CPPNs) are differentiable networks that independently map (x, y) pixel coordinates to (r, g, b) colour values. Recently, CPPNs have been used for creating interesting imagery for creative purposes, e.g., neural art. However their architecture biases generated images to be overly smooth, lacking high-frequency detail. In this work, we extend CPPNs to explicitly model the frequency information for each pixel output, capturing frequencies beyond the DC component. We show that our Fourier-CPPNs (F-CPPNs) provide improved visual detail for image synthesis.