 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Invisible Hand of Physics: When Video Diffusion Models Know More Than They Show
Jun 03, 2026Modern video diffusion models generate increasingly realistic and temporally coherent videos, motivating their use as candidate world simulators. Yet it remains unclear whether these models internally encode physical structure, or merely reproduce motion patterns seen during training. We study this question by probing video diffusion models along latent trajectories corresponding to real videos with known physical plausibility. To obtain such trajectories, we approximately invert the deterministic sampling process by integrating the learned velocity field backward from a clean video latent to noise, giving access to the model's intermediate states and attention maps. Using these recovered trajectories, we show that physical plausibility is linearly decodable from diffusion transformer states across IntPhys and InfLevel, reaching around 81.27% average accuracy and outperforming dedicated representation-learning baselines such as V-JEPA and VideoMAE. Surprisingly, this signal is absent from the VAE latent input and emerges inside the denoising transformer itself, despite the model not being trained with a self-supervised predictive objective. These findings suggest that physically meaningful representations can arise as a byproduct of generative denoising.
Modelling Customer Trajectories with Reinforcement Learning for Practical Retail Insights
May 18, 2026Understanding customer movement within retail spaces is essential for optimizing store layouts. Real-world trajectory data can provide highly accurate insights, but collecting it is costly and often infeasible for many retailers. Heuristics such as Travelling Salesman Problem (TSP) and Probabilistic Nearest Neighbours (PNN) are commonly used as inexpensive approximations, but actual customer trajectories deviate by an average of 28% from shortest paths, highlighting a tradeoff between accuracy and practicality. We propose an agent-based modelling framework that casts customer trajectory prediction as a maximum entropy reinforcement learning (RL) problem, balancing reward maximization with stochasticity to better reflect customers with bounded rationality. Using real-world trajectory data from a convenience store, we show that RL-generated trajectories align more closely with customer behaviour than TSP and PNN, providing more accurate estimates of impulse purchase rates and shelf traffic densities. Furthermore, only RL-based predictions yield repositioning decisions for impulse products that align with those derived from actual trajectory data, resulting in comparable estimated profit gains. Our work demonstrates that RL provides a practical, behaviourally grounded alternative that bridges the gap between oversimplified heuristics and data-intensive approaches, making accurate layout optimization more accessible. To encourage further research, the source code is available on GitHub.
Reinforcement Learning for Sequence Design Leveraging Protein Language Models
Jul 03, 2024



Protein sequence design, determined by amino acid sequences, are essential to protein engineering problems in drug discovery. Prior approaches have resorted to evolutionary strategies or Monte-Carlo methods for protein design, but often fail to exploit the structure of the combinatorial search space, to generalize to unseen sequences. In the context of discrete black box optimization over large search spaces, learning a mutation policy to generate novel sequences with reinforcement learning is appealing. Recent advances in protein language models (PLMs) trained on large corpora of protein sequences offer a potential solution to this problem by scoring proteins according to their biological plausibility (such as the TM-score). In this work, we propose to use PLMs as a reward function to generate new sequences. Yet the PLM can be computationally expensive to query due to its large size. To this end, we propose an alternative paradigm where optimization can be performed on scores from a smaller proxy model that is periodically finetuned, jointly while learning the mutation policy. We perform extensive experiments on various sequence lengths to benchmark RL-based approaches, and provide comprehensive evaluations along biological plausibility and diversity of the protein. Our experimental results include favorable evaluations of the proposed sequences, along with high diversity scores, demonstrating that RL is a strong candidate for biological sequence design. Finally, we provide a modular open source implementation can be easily integrated in most RL training loops, with support for replacing the reward model with other PLMs, to spur further research in this domain. The code for all experiments is provided in the supplementary material.
Minimax Exploiter: A Data Efficient Approach for Competitive Self-Play
Nov 28, 2023Recent advances in Competitive Self-Play (CSP) have achieved, or even surpassed, human level performance in complex game environments such as Dota 2 and StarCraft II using Distributed Multi-Agent Reinforcement Learning (MARL). One core component of these methods relies on creating a pool of learning agents -- consisting of the Main Agent, past versions of this agent, and Exploiter Agents -- where Exploiter Agents learn counter-strategies to the Main Agents. A key drawback of these approaches is the large computational cost and physical time that is required to train the system, making them impractical to deploy in highly iterative real-life settings such as video game productions. In this paper, we propose the Minimax Exploiter, a game theoretic approach to exploiting Main Agents that leverages knowledge of its opponents, leading to significant increases in data efficiency. We validate our approach in a diversity of settings, including simple turn based games, the arcade learning environment, and For Honor, a modern video game. The Minimax Exploiter consistently outperforms strong baselines, demonstrating improved stability and data efficiency, leading to a robust CSP-MARL method that is both flexible and easy to deploy.
Differentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
STAMP: Differentiable Task and Motion Planning via Stein Variational Gradient Descent
Oct 03, 2023



Planning for many manipulation tasks, such as using tools or assembling parts, often requires both symbolic and geometric reasoning. Task and Motion Planning (TAMP) algorithms typically solve these problems by conducting a tree search over high-level task sequences while checking for kinematic and dynamic feasibility. While performant, most existing algorithms are highly inefficient as their time complexity grows exponentially with the number of possible actions and objects. Additionally, they only find a single solution to problems in which many feasible plans may exist. To address these limitations, we propose a novel algorithm called Stein Task and Motion Planning (STAMP) that leverages parallelization and differentiable simulation to efficiently search for multiple diverse plans. STAMP relaxes discrete-and-continuous TAMP problems into continuous optimization problems that can be solved using variational inference. Our algorithm builds upon Stein Variational Gradient Descent, a gradient-based variational inference algorithm, and parallelized differentiable physics simulators on the GPU to efficiently obtain gradients for inference. Further, we employ imitation learning to introduce action abstractions that reduce the inference problem to lower dimensions. We demonstrate our method on two TAMP problems and empirically show that STAMP is able to: 1) produce multiple diverse plans in parallel; and 2) search for plans more efficiently compared to existing TAMP baselines.
Efficient Graphics Representation with Differentiable Indirection
Sep 12, 2023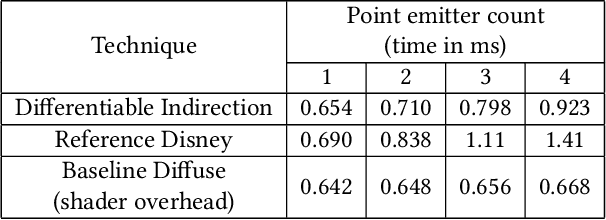
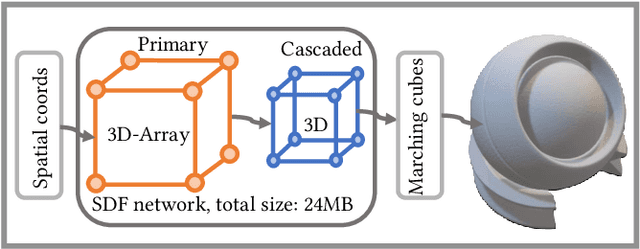
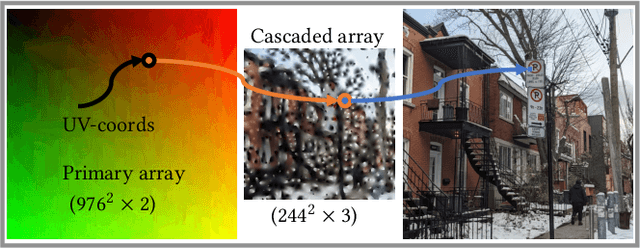

We introduce differentiable indirection -- a novel learned primitive that employs differentiable multi-scale lookup tables as an effective substitute for traditional compute and data operations across the graphics pipeline. We demonstrate its flexibility on a number of graphics tasks, i.e., geometric and image representation, texture mapping, shading, and radiance field representation. In all cases, differentiable indirection seamlessly integrates into existing architectures, trains rapidly, and yields both versatile and efficient results.
* Project website: https://sayan1an.github.io/din.html
A Model-Based Solution to the Offline Multi-Agent Reinforcement Learning Coordination Problem
May 26, 2023



Training multiple agents to coordinate is an important problem with applications in robotics, game theory, economics, and social sciences. However, most existing Multi-Agent Reinforcement Learning (MARL) methods are online and thus impractical for real-world applications in which collecting new interactions is costly or dangerous. While these algorithms should leverage offline data when available, doing so gives rise to the offline coordination problem. Specifically, we identify and formalize the strategy agreement (SA) and the strategy fine-tuning (SFT) challenges, two coordination issues at which current offline MARL algorithms fail. To address this setback, we propose a simple model-based approach that generates synthetic interaction data and enables agents to converge on a strategy while fine-tuning their policies accordingly. Our resulting method, Model-based Offline Multi-Agent Proximal Policy Optimization (MOMA-PPO), outperforms the prevalent learning methods in challenging offline multi-agent MuJoCo tasks even under severe partial observability and with learned world models.
MeshDiffusion: Score-based Generative 3D Mesh Modeling
Mar 14, 2023



We consider the task of generating realistic 3D shapes, which is useful for a variety of applications such as automatic scene generation and physical simulation. Compared to other 3D representations like voxels and point clouds, meshes are more desirable in practice, because (1) they enable easy and arbitrary manipulation of shapes for relighting and simulation, and (2) they can fully leverage the power of modern graphics pipelines which are mostly optimized for meshes. Previous scalable methods for generating meshes typically rely on sub-optimal post-processing, and they tend to produce overly-smooth or noisy surfaces without fine-grained geometric details. To overcome these shortcomings, we take advantage of the graph structure of meshes and use a simple yet very effective generative modeling method to generate 3D meshes. Specifically, we represent meshes with deformable tetrahedral grids, and then train a diffusion model on this direct parametrization. We demonstrate the effectiveness of our model on multiple generative tasks.
Visual Question Answering From Another Perspective: CLEVR Mental Rotation Tests
Dec 03, 2022



Different types of mental rotation tests have been used extensively in psychology to understand human visual reasoning and perception. Understanding what an object or visual scene would look like from another viewpoint is a challenging problem that is made even harder if it must be performed from a single image. We explore a controlled setting whereby questions are posed about the properties of a scene if that scene was observed from another viewpoint. To do this we have created a new version of the CLEVR dataset that we call CLEVR Mental Rotation Tests (CLEVR-MRT). Using CLEVR-MRT we examine standard methods, show how they fall short, then explore novel neural architectures that involve inferring volumetric representations of a scene. These volumes can be manipulated via camera-conditioned transformations to answer the question. We examine the efficacy of different model variants through rigorous ablations and demonstrate the efficacy of volumetric representations.