 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
Urban Radiance Fields
Nov 29, 2021
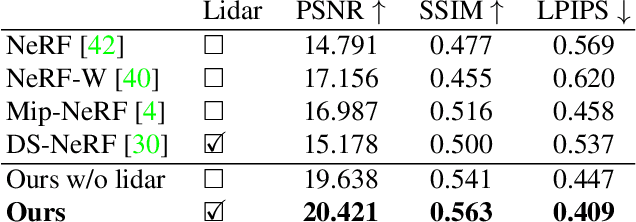


The goal of this work is to perform 3D reconstruction and novel view synthesis from data captured by scanning platforms commonly deployed for world mapping in urban outdoor environments (e.g., Street View). Given a sequence of posed RGB images and lidar sweeps acquired by cameras and scanners moving through an outdoor scene, we produce a model from which 3D surfaces can be extracted and novel RGB images can be synthesized. Our approach extends Neural Radiance Fields, which has been demonstrated to synthesize realistic novel images for small scenes in controlled settings, with new methods for leveraging asynchronously captured lidar data, for addressing exposure variation between captured images, and for leveraging predicted image segmentations to supervise densities on rays pointing at the sky. Each of these three extensions provides significant performance improvements in experiments on Street View data. Our system produces state-of-the-art 3D surface reconstructions and synthesizes higher quality novel views in comparison to both traditional methods (e.g.~COLMAP) and recent neural representations (e.g.~Mip-NeRF).
ShaRF: Shape-conditioned Radiance Fields from a Single View
Feb 17, 2021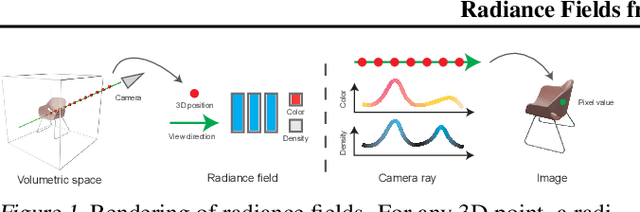
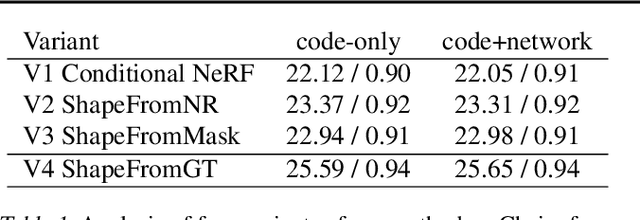
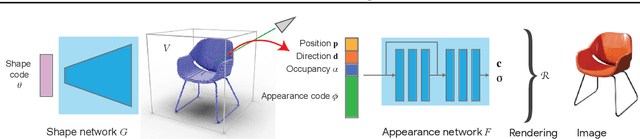

We present a method for estimating neural scenes representations of objects given only a single image. The core of our method is the estimation of a geometric scaffold for the object and its use as a guide for the reconstruction of the underlying radiance field. Our formulation is based on a generative process that first maps a latent code to a voxelized shape, and then renders it to an image, with the object appearance being controlled by a second latent code. During inference, we optimize both the latent codes and the networks to fit a test image of a new object. The explicit disentanglement of shape and appearance allows our model to be fine-tuned given a single image. We can then render new views in a geometrically consistent manner and they represent faithfully the input object. Additionally, our method is able to generalize to images outside of the training domain (more realistic renderings and even real photographs). Finally, the inferred geometric scaffold is itself an accurate estimate of the object's 3D shape. We demonstrate in several experiments the effectiveness of our approach in both synthetic and real images.
From Points to Multi-Object 3D Reconstruction
Dec 21, 2020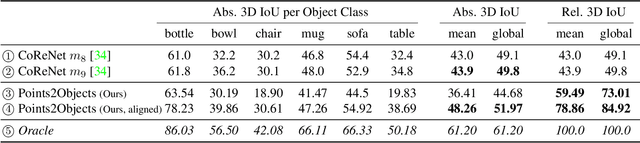
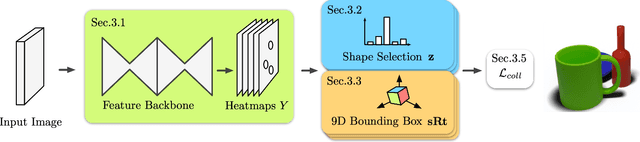

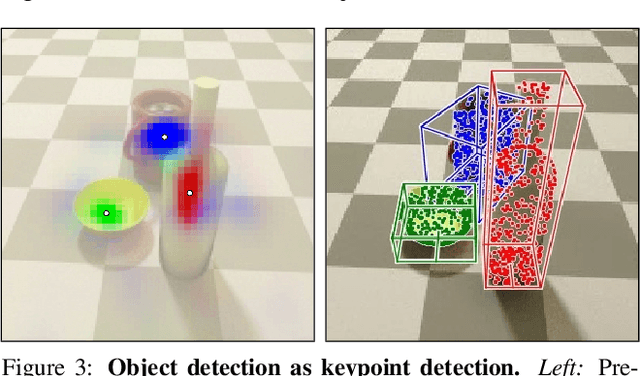
We propose a method to detect and reconstruct multiple 3D objects from a single RGB image. The key idea is to optimize for detection, alignment and shape jointly over all objects in the RGB image, while focusing on realistic and physically plausible reconstructions. To this end, we propose a keypoint detector that localizes objects as center points and directly predicts all object properties, including 9-DoF bounding boxes and 3D shapes -- all in a single forward pass. The proposed method formulates 3D shape reconstruction as a shape selection problem, i.e. it selects among exemplar shapes from a given database. This makes it agnostic to shape representations, which enables a lightweight reconstruction of realistic and visually-pleasing shapes based on CAD-models, while the training objective is formulated around point clouds and voxel representations. A collision-loss promotes non-intersecting objects, further increasing the reconstruction realism. Given the RGB image, the presented approach performs lightweight reconstruction in a single-stage, it is real-time capable, fully differentiable and end-to-end trainable. Our experiments compare multiple approaches for 9-DoF bounding box estimation, evaluate the novel shape-selection mechanism and compare to recent methods in terms of 3D bounding box estimation and 3D shape reconstruction quality.
Reconstructing NBA Players
Jul 27, 2020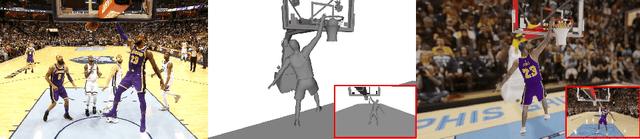

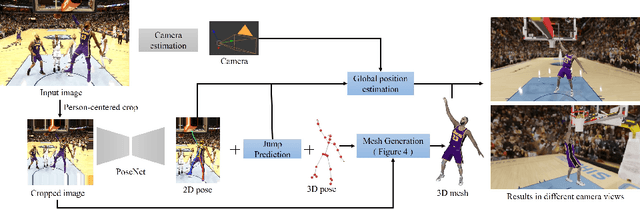

Great progress has been made in 3D body pose and shape estimation from a single photo. Yet, state-of-the-art results still suffer from errors due to challenging body poses, modeling clothing, and self occlusions. The domain of basketball games is particularly challenging, as it exhibits all of these challenges. In this paper, we introduce a new approach for reconstruction of basketball players that outperforms the state-of-the-art. Key to our approach is a new method for creating poseable, skinned models of NBA players, and a large database of meshes (derived from the NBA2K19 video game), that we are releasing to the research community. Based on these models, we introduce a new method that takes as input a single photo of a clothed player in any basketball pose and outputs a high resolution mesh and 3D pose for that player. We demonstrate substantial improvement over state-of-the-art, single-image methods for body shape reconstruction.
Neural Voxel Renderer: Learning an Accurate and Controllable Rendering Tool
Dec 10, 2019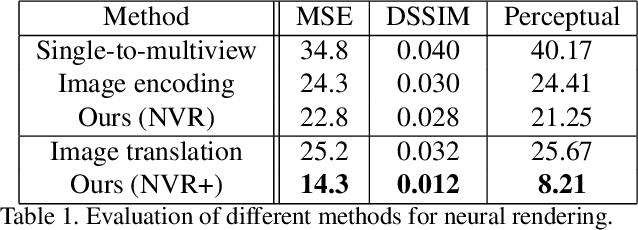
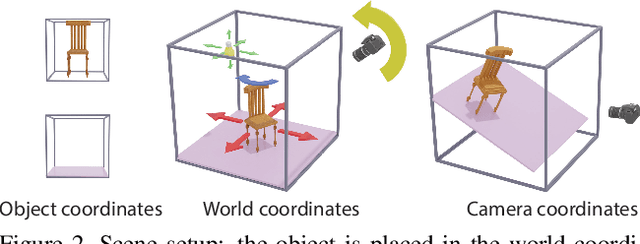

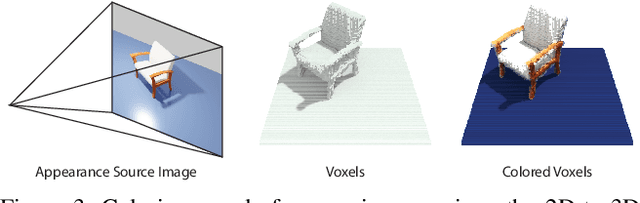
We present a neural rendering framework that maps a voxelized scene into a high quality image. Highly-textured objects and scene element interactions are realistically rendered by our method, despite having a rough representation as an input. Moreover, our approach allows controllable rendering: geometric and appearance modifications in the input are accurately propagated to the output. The user can move, rotate and scale an object, change its appearance and texture or modify the position of the light and all these edits are represented in the final rendering. We demonstrate the effectiveness of our approach by rendering scenes with varying appearance, from single color per object to complex, high-frequency textures. We show that our rerendering network can generate very detailed images that represent precisely the appearance of the input scene. Our experiments illustrate that our approach achieves more accurate image synthesis results compared to alternatives and can also handle low voxel grid resolutions. Finally, we show how our neural rendering framework can capture and faithfully render objects from real images and from a diverse set of classes.
PhotoShape: Photorealistic Materials for Large-Scale Shape Collections
Sep 26, 2018
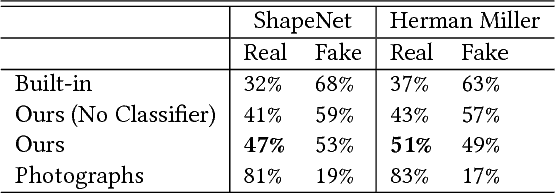


Existing online 3D shape repositories contain thousands of 3D models but lack photorealistic appearance. We present an approach to automatically assign high-quality, realistic appearance models to large scale 3D shape collections. The key idea is to jointly leverage three types of online data -- shape collections, material collections, and photo collections, using the photos as reference to guide assignment of materials to shapes. By generating a large number of synthetic renderings, we train a convolutional neural network to classify materials in real photos, and employ 3D-2D alignment techniques to transfer materials to different parts of each shape model. Our system produces photorealistic, relightable, 3D shapes (PhotoShapes).
Soccer on Your Tabletop
Jun 03, 2018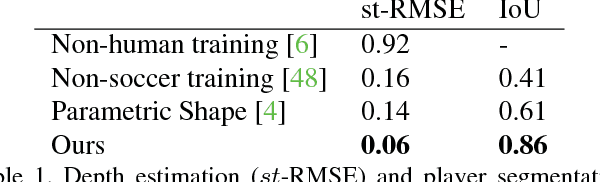


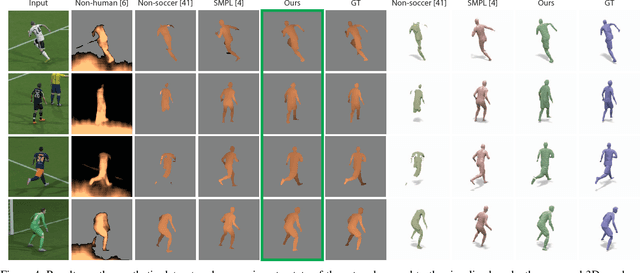
We present a system that transforms a monocular video of a soccer game into a moving 3D reconstruction, in which the players and field can be rendered interactively with a 3D viewer or through an Augmented Reality device. At the heart of our paper is an approach to estimate the depth map of each player, using a CNN that is trained on 3D player data extracted from soccer video games. We compare with state of the art body pose and depth estimation techniques, and show results on both synthetic ground truth benchmarks, and real YouTube soccer footage.
What Is Around The Camera?
Aug 01, 2017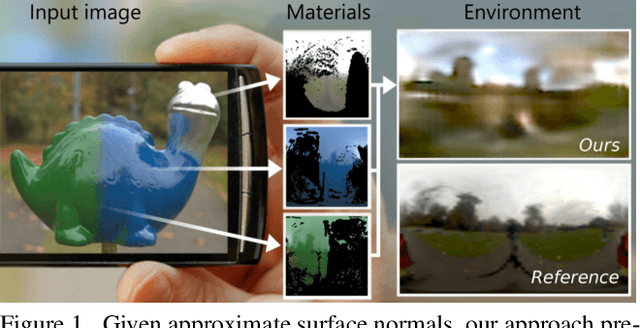
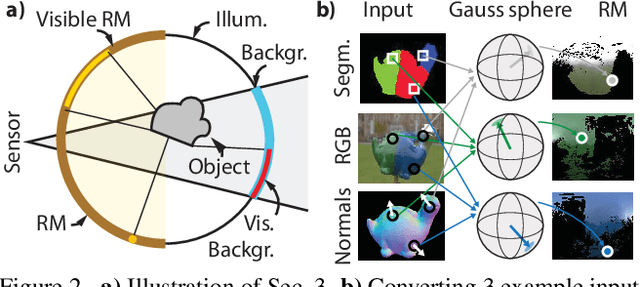

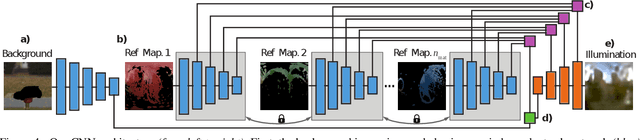
How much does a single image reveal about the environment it was taken in? In this paper, we investigate how much of that information can be retrieved from a foreground object, combined with the background (i.e. the visible part of the environment). Assuming it is not perfectly diffuse, the foreground object acts as a complexly shaped and far-from-perfect mirror. An additional challenge is that its appearance confounds the light coming from the environment with the unknown materials it is made of. We propose a learning-based approach to predict the environment from multiple reflectance maps that are computed from approximate surface normals. The proposed method allows us to jointly model the statistics of environments and material properties. We train our system from synthesized training data, but demonstrate its applicability to real-world data. Interestingly, our analysis shows that the information obtained from objects made out of multiple materials often is complementary and leads to better performance.
Novel Views of Objects from a Single Image
Aug 15, 2016



Taking an image of an object is at its core a lossy process. The rich information about the three-dimensional structure of the world is flattened to an image plane and decisions such as viewpoint and camera parameters are final and not easily revertible. As a consequence, possibilities of changing viewpoint are limited. Given a single image depicting an object, novel-view synthesis is the task of generating new images that render the object from a different viewpoint than the one given. The main difficulty is to synthesize the parts that are disoccluded; disocclusion occurs when parts of an object are hidden by the object itself under a specific viewpoint. In this work, we show how to improve novel-view synthesis by making use of the correlations observed in 3D models and applying them to new image instances. We propose a technique to use the structural information extracted from a 3D model that matches the image object in terms of viewpoint and shape. For the latter part, we propose an efficient 2D-to-3D alignment method that associates precisely the image appearance with the 3D model geometry with minimal user interaction. Our technique is able to simulate plausible viewpoint changes for a variety of object classes within seconds. Additionally, we show that our synthesized images can be used as additional training data that improves the performance of standard object detectors.