 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of the Room: Generalizing Event-Based Dynamic Motion Segmentation for Complex Scenes
Mar 07, 2024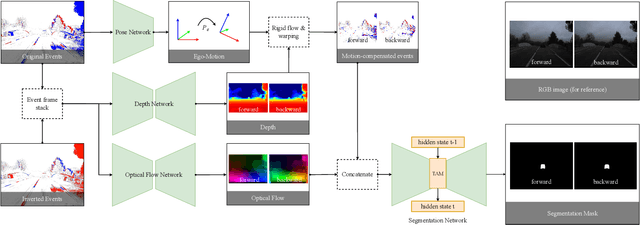
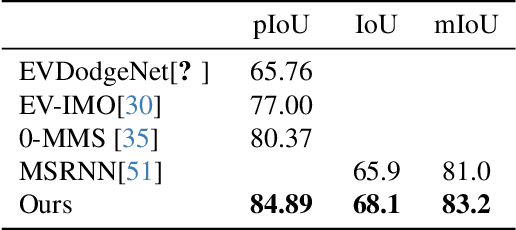
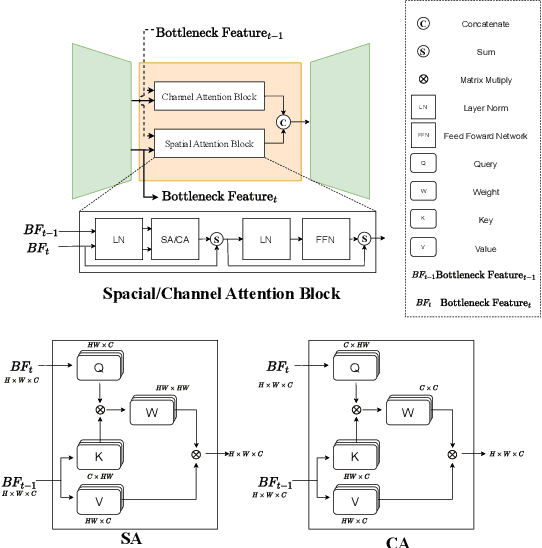
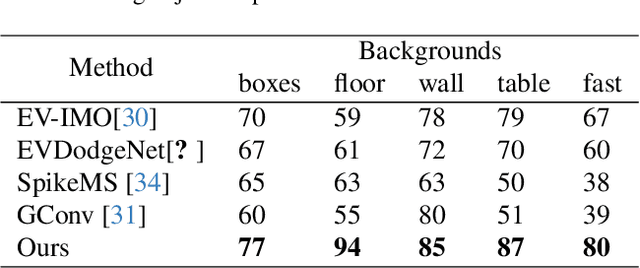
Rapid and reliable identification of dynamic scene parts, also known as motion segmentation, is a key challenge for mobile sensors. Contemporary RGB camera-based methods rely on modeling camera and scene properties however, are often under-constrained and fall short in unknown categories. Event cameras have the potential to overcome these limitations, but corresponding methods have only been demonstrated in smaller-scale indoor environments with simplified dynamic objects. This work presents an event-based method for class-agnostic motion segmentation that can successfully be deployed across complex large-scale outdoor environments too. To this end, we introduce a novel divide-and-conquer pipeline that combines: (a) ego-motion compensated events, computed via a scene understanding module that predicts monocular depth and camera pose as auxiliary tasks, and (b) optical flow from a dedicated optical flow module. These intermediate representations are then fed into a segmentation module that predicts motion segmentation masks. A novel transformer-based temporal attention module in the segmentation module builds correlations across adjacent 'frames' to get temporally consistent segmentation masks. Our method sets the new state-of-the-art on the classic EV-IMO benchmark (indoors), where we achieve improvements of 2.19 moving object IoU (2.22 mIoU) and 4.52 point IoU respectively, as well as on a newly-generated motion segmentation and tracking benchmark (outdoors) based on the DSEC event dataset, termed DSEC-MOTS, where we show improvement of 12.91 moving object IoU.
Event-based Image Deblurring with Dynamic Motion Awareness
Aug 24, 2022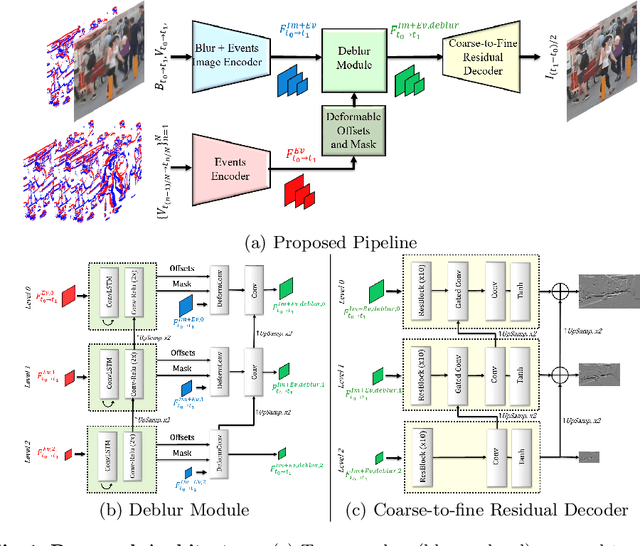

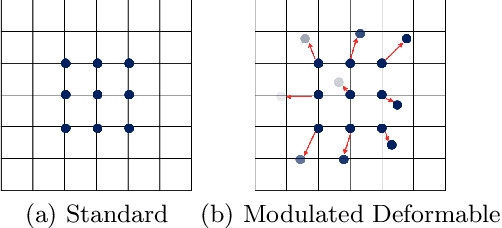

Non-uniform image deblurring is a challenging task due to the lack of temporal and textural information in the blurry image itself. Complementary information from auxiliary sensors such event sensors are being explored to address these limitations. The latter can record changes in a logarithmic intensity asynchronously, called events, with high temporal resolution and high dynamic range. Current event-based deblurring methods combine the blurry image with events to jointly estimate per-pixel motion and the deblur operator. In this paper, we argue that a divide-and-conquer approach is more suitable for this task. To this end, we propose to use modulated deformable convolutions, whose kernel offsets and modulation masks are dynamically estimated from events to encode the motion in the scene, while the deblur operator is learned from the combination of blurry image and corresponding events. Furthermore, we employ a coarse-to-fine multi-scale reconstruction approach to cope with the inherent sparsity of events in low contrast regions. Importantly, we introduce the first dataset containing pairs of real RGB blur images and related events during the exposure time. Our results show better overall robustness when using events, with improvements in PSNR by up to 1.57dB on synthetic data and 1.08 dB on real event data.
FoV-Net: Field-of-View Extrapolation Using Self-Attention and Uncertainty
Apr 04, 2022

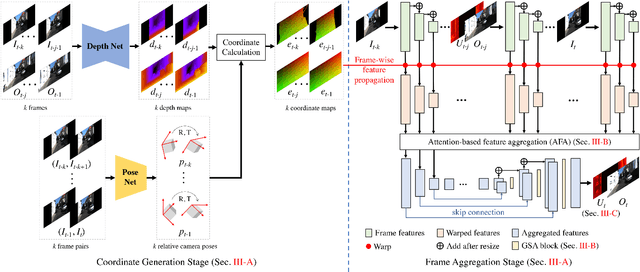
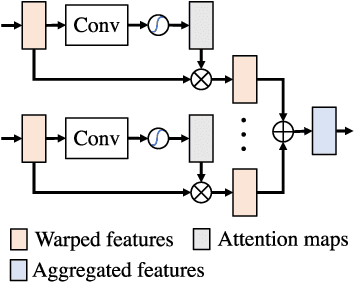
The ability to make educated predictions about their surroundings, and associate them with certain confidence, is important for intelligent systems, like autonomous vehicles and robots. It allows them to plan early and decide accordingly. Motivated by this observation, in this paper we utilize information from a video sequence with a narrow field-of-view to infer the scene at a wider field-of-view. To this end, we propose a temporally consistent field-of-view extrapolation framework, namely FoV-Net, that: (1) leverages 3D information to propagate the observed scene parts from past frames; (2) aggregates the propagated multi-frame information using an attention-based feature aggregation module and a gated self-attention module, simultaneously hallucinating any unobserved scene parts; and (3) assigns an interpretable uncertainty value at each pixel. Extensive experiments show that FoV-Net does not only extrapolate the temporally consistent wide field-of-view scene better than existing alternatives, but also provides the associated uncertainty which may benefit critical decision-making downstream applications. Project page is at http://charliememory.github.io/RAL21_FoV.
Time Lens++: Event-based Frame Interpolation with Parametric Non-linear Flow and Multi-scale Fusion
Mar 31, 2022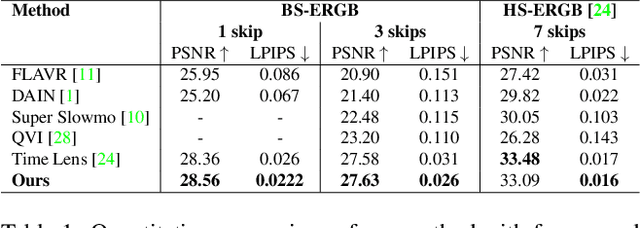
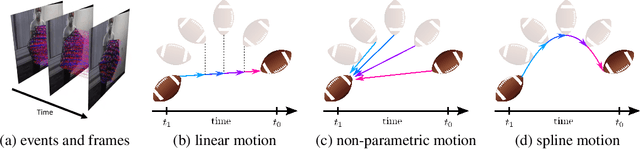
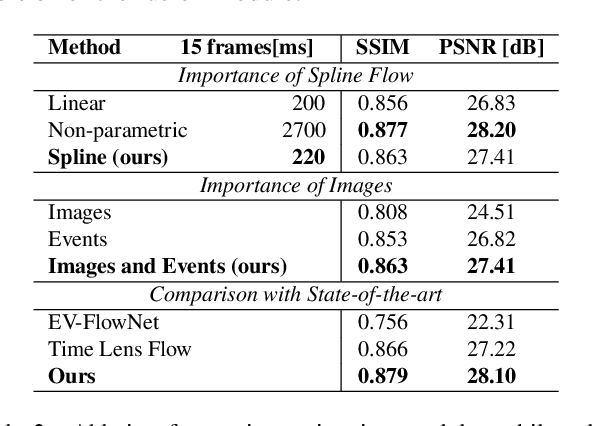
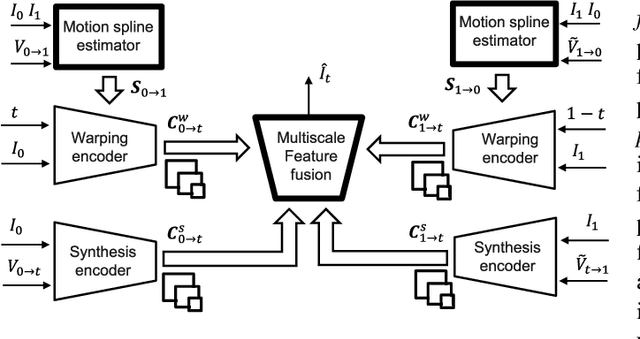
Recently, video frame interpolation using a combination of frame- and event-based cameras has surpassed traditional image-based methods both in terms of performance and memory efficiency. However, current methods still suffer from (i) brittle image-level fusion of complementary interpolation results, that fails in the presence of artifacts in the fused image, (ii) potentially temporally inconsistent and inefficient motion estimation procedures, that run for every inserted frame and (iii) low contrast regions that do not trigger events, and thus cause events-only motion estimation to generate artifacts. Moreover, previous methods were only tested on datasets consisting of planar and faraway scenes, which do not capture the full complexity of the real world. In this work, we address the above problems by introducing multi-scale feature-level fusion and computing one-shot non-linear inter-frame motion from events and images, which can be efficiently sampled for image warping. We also collect the first large-scale events and frames dataset consisting of more than 100 challenging scenes with depth variations, captured with a new experimental setup based on a beamsplitter. We show that our method improves the reconstruction quality by up to 0.2 dB in terms of PSNR and up to 15% in LPIPS score.
Multi-Bracket High Dynamic Range Imaging with Event Cameras
Mar 13, 2022



Modern high dynamic range (HDR) imaging pipelines align and fuse multiple low dynamic range (LDR) images captured at different exposure times. While these methods work well in static scenes, dynamic scenes remain a challenge since the LDR images still suffer from saturation and noise. In such scenarios, event cameras would be a valid complement, thanks to their higher temporal resolution and dynamic range. In this paper, we propose the first multi-bracket HDR pipeline combining a standard camera with an event camera. Our results show better overall robustness when using events, with improvements in PSNR by up to 5dB on synthetic data and up to 0.7dB on real-world data. We also introduce a new dataset containing bracketed LDR images with aligned events and HDR ground truth.
TimeLens: Event-based Video Frame Interpolation
Jun 14, 2021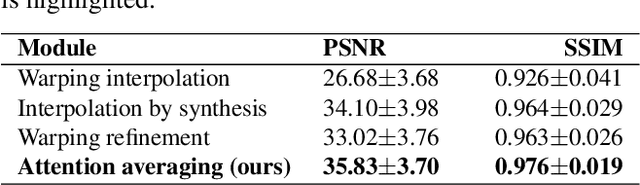
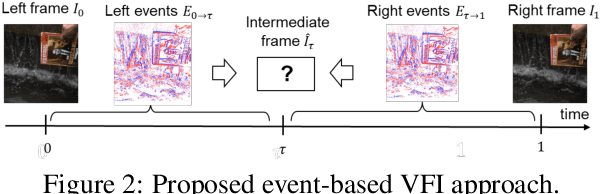
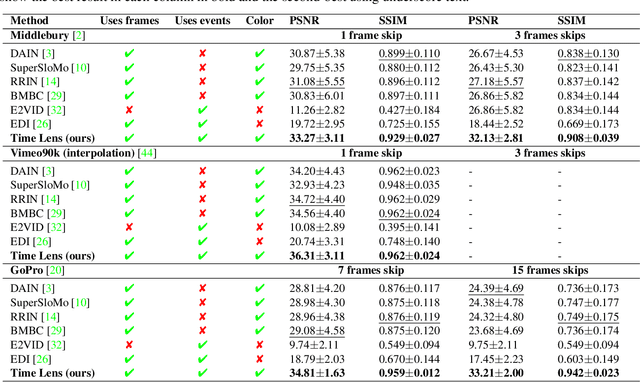
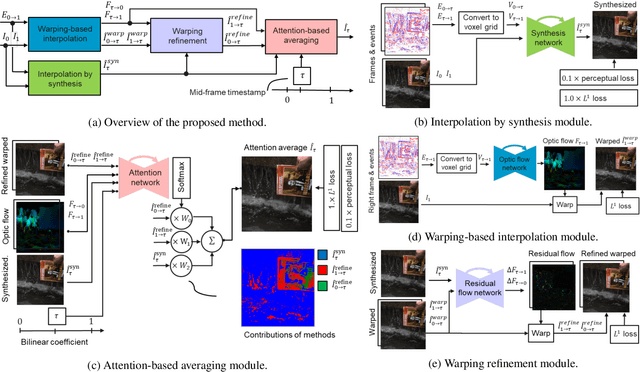
State-of-the-art frame interpolation methods generate intermediate frames by inferring object motions in the image from consecutive key-frames. In the absence of additional information, first-order approximations, i.e. optical flow, must be used, but this choice restricts the types of motions that can be modeled, leading to errors in highly dynamic scenarios. Event cameras are novel sensors that address this limitation by providing auxiliary visual information in the blind-time between frames. They asynchronously measure per-pixel brightness changes and do this with high temporal resolution and low latency. Event-based frame interpolation methods typically adopt a synthesis-based approach, where predicted frame residuals are directly applied to the key-frames. However, while these approaches can capture non-linear motions they suffer from ghosting and perform poorly in low-texture regions with few events. Thus, synthesis-based and flow-based approaches are complementary. In this work, we introduce Time Lens, a novel indicates equal contribution method that leverages the advantages of both. We extensively evaluate our method on three synthetic and two real benchmarks where we show an up to 5.21 dB improvement in terms of PSNR over state-of-the-art frame-based and event-based methods. Finally, we release a new large-scale dataset in highly dynamic scenarios, aimed at pushing the limits of existing methods.
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations
Jun 10, 2021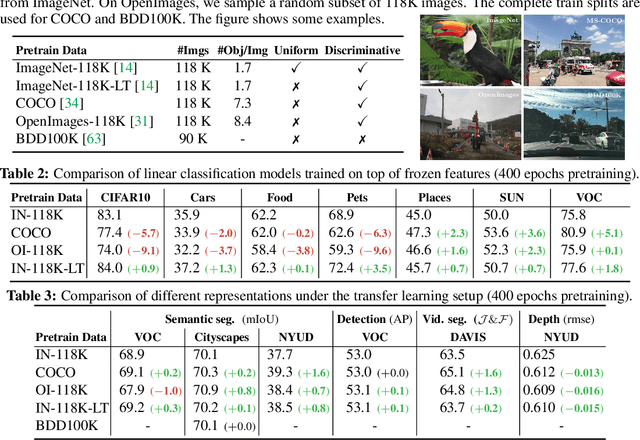
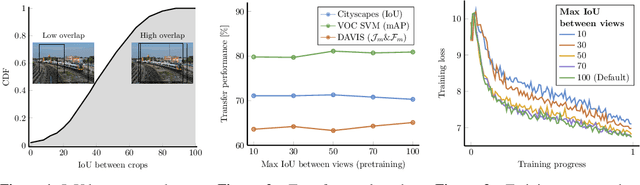
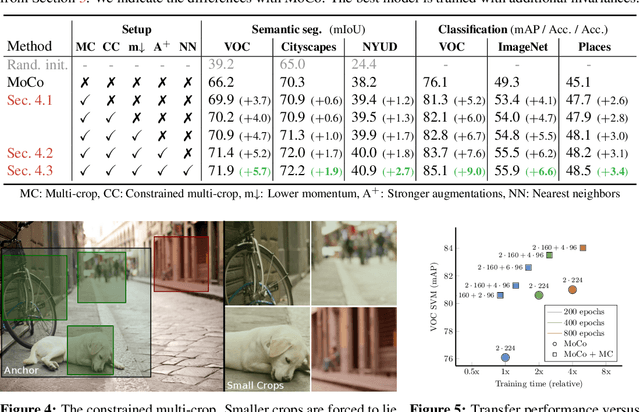
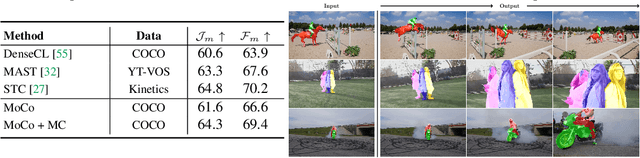
Contrastive self-supervised learning has outperformed supervised pretraining on many downstream tasks like segmentation and object detection. However, current methods are still primarily applied to curated datasets like ImageNet. In this paper, we first study how biases in the dataset affect existing methods. Our results show that current contrastive approaches work surprisingly well across: (i) object- versus scene-centric, (ii) uniform versus long-tailed and (iii) general versus domain-specific datasets. Second, given the generality of the approach, we try to realize further gains with minor modifications. We show that learning additional invariances -- through the use of multi-scale cropping, stronger augmentations and nearest neighbors -- improves the representations. Finally, we observe that MoCo learns spatially structured representations when trained with a multi-crop strategy. The representations can be used for semantic segment retrieval and video instance segmentation without finetuning. Moreover, the results are on par with specialized models. We hope this work will serve as a useful study for other researchers. The code and models will be available at https://github.com/wvangansbeke/Revisiting-Contrastive-SSL.
Learning to Relate Depth and Semantics for Unsupervised Domain Adaptation
May 17, 2021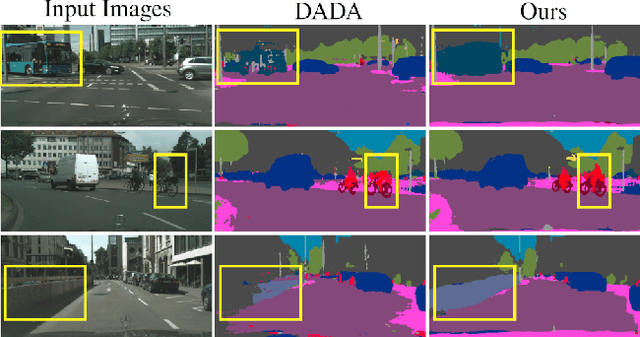
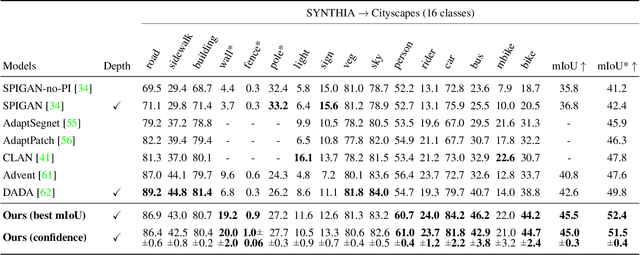

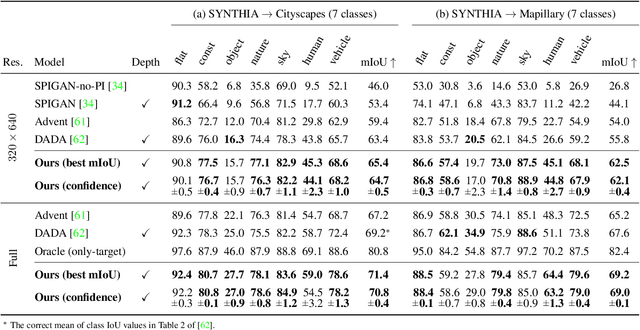
We present an approach for encoding visual task relationships to improve model performance in an Unsupervised Domain Adaptation (UDA) setting. Semantic segmentation and monocular depth estimation are shown to be complementary tasks; in a multi-task learning setting, a proper encoding of their relationships can further improve performance on both tasks. Motivated by this observation, we propose a novel Cross-Task Relation Layer (CTRL), which encodes task dependencies between the semantic and depth predictions. To capture the cross-task relationships, we propose a neural network architecture that contains task-specific and cross-task refinement heads. Furthermore, we propose an Iterative Self-Learning (ISL) training scheme, which exploits semantic pseudo-labels to provide extra supervision on the target domain. We experimentally observe improvements in both tasks' performance because the complementary information present in these tasks is better captured. Specifically, we show that: (1) our approach improves performance on all tasks when they are complementary and mutually dependent; (2) the CTRL helps to improve both semantic segmentation and depth estimation tasks performance in the challenging UDA setting; (3) the proposed ISL training scheme further improves the semantic segmentation performance. The implementation is available at https://github.com/susaha/ctrl-uda.
Exploring Relational Context for Multi-Task Dense Prediction
Apr 28, 2021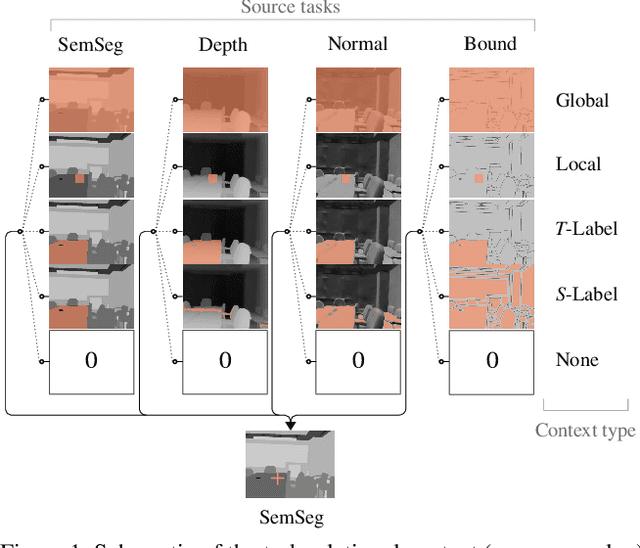
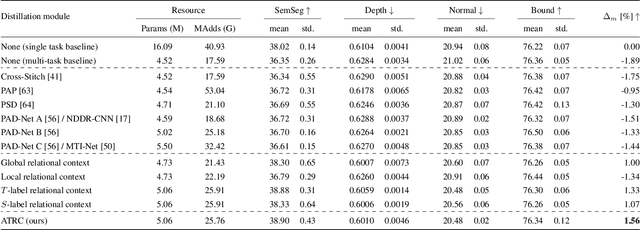
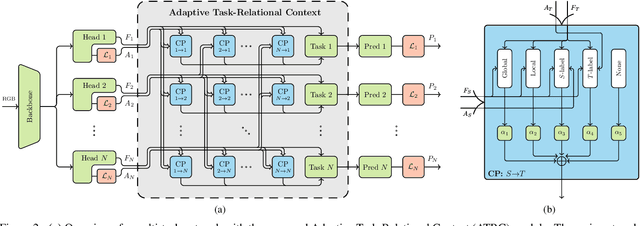
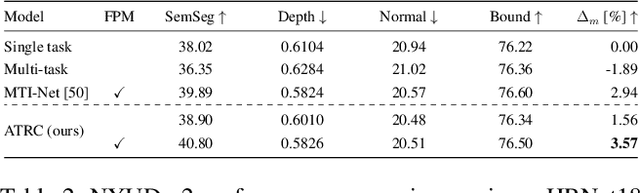
The timeline of computer vision research is marked with advances in learning and utilizing efficient contextual representations. Most of them, however, are targeted at improving model performance on a single downstream task. We consider a multi-task environment for dense prediction tasks, represented by a common backbone and independent task-specific heads. Our goal is to find the most efficient way to refine each task prediction by capturing cross-task contexts dependent on tasks' relations. We explore various attention-based contexts, such as global and local, in the multi-task setting and analyze their behavior when applied to refine each task independently. Empirical findings confirm that different source-target task pairs benefit from different context types. To automate the selection process, we propose an Adaptive Task-Relational Context (ATRC) module, which samples the pool of all available contexts for each task pair using neural architecture search and outputs the optimal configuration for deployment. Our method achieves state-of-the-art performance on two important multi-task benchmarks, namely NYUD-v2 and PASCAL-Context. The proposed ATRC has a low computational toll and can be used as a drop-in refinement module for any supervised multi-task architecture.
Spectral Tensor Train Parameterization of Deep Learning Layers
Mar 07, 2021


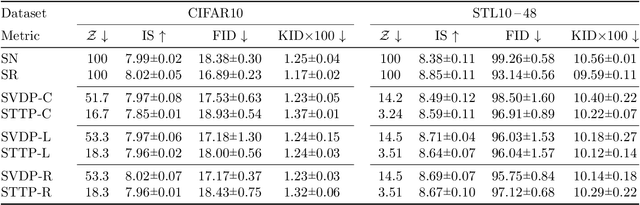
We study low-rank parameterizations of weight matrices with embedded spectral properties in the Deep Learning context. The low-rank property leads to parameter efficiency and permits taking computational shortcuts when computing mappings. Spectral properties are often subject to constraints in optimization problems, leading to better models and stability of optimization. We start by looking at the compact SVD parameterization of weight matrices and identifying redundancy sources in the parameterization. We further apply the Tensor Train (TT) decomposition to the compact SVD components, and propose a non-redundant differentiable parameterization of fixed TT-rank tensor manifolds, termed the Spectral Tensor Train Parameterization (STTP). We demonstrate the effects of neural network compression in the image classification setting and both compression and improved training stability in the generative adversarial training setting.