 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
The Llama 3 Herd of Models
Jul 31, 2024Modern artificial intelligence (AI) systems are powered by foundation models. This paper presents a new set of foundation models, called Llama 3. It is a herd of language models that natively support multilinguality, coding, reasoning, and tool usage. Our largest model is a dense Transformer with 405B parameters and a context window of up to 128K tokens. This paper presents an extensive empirical evaluation of Llama 3. We find that Llama 3 delivers comparable quality to leading language models such as GPT-4 on a plethora of tasks. We publicly release Llama 3, including pre-trained and post-trained versions of the 405B parameter language model and our Llama Guard 3 model for input and output safety. The paper also presents the results of experiments in which we integrate image, video, and speech capabilities into Llama 3 via a compositional approach. We observe this approach performs competitively with the state-of-the-art on image, video, and speech recognition tasks. The resulting models are not yet being broadly released as they are still under development.
Emu: Enhancing Image Generation Models Using Photogenic Needles in a Haystack
Sep 27, 2023



Training text-to-image models with web scale image-text pairs enables the generation of a wide range of visual concepts from text. However, these pre-trained models often face challenges when it comes to generating highly aesthetic images. This creates the need for aesthetic alignment post pre-training. In this paper, we propose quality-tuning to effectively guide a pre-trained model to exclusively generate highly visually appealing images, while maintaining generality across visual concepts. Our key insight is that supervised fine-tuning with a set of surprisingly small but extremely visually appealing images can significantly improve the generation quality. We pre-train a latent diffusion model on $1.1$ billion image-text pairs and fine-tune it with only a few thousand carefully selected high-quality images. The resulting model, Emu, achieves a win rate of $82.9\%$ compared with its pre-trained only counterpart. Compared to the state-of-the-art SDXLv1.0, Emu is preferred $68.4\%$ and $71.3\%$ of the time on visual appeal on the standard PartiPrompts and our Open User Input benchmark based on the real-world usage of text-to-image models. In addition, we show that quality-tuning is a generic approach that is also effective for other architectures, including pixel diffusion and masked generative transformer models.
Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training
Jan 05, 2023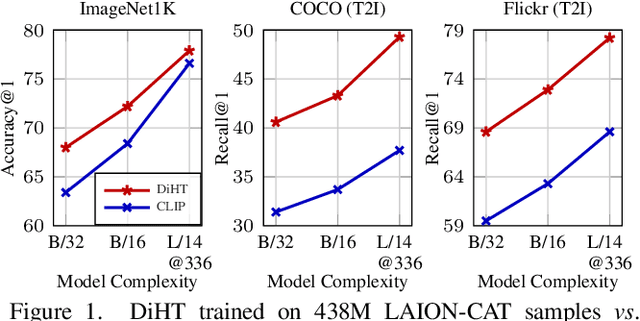
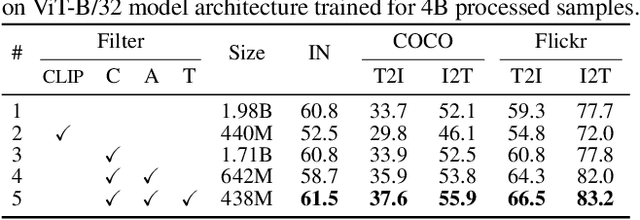
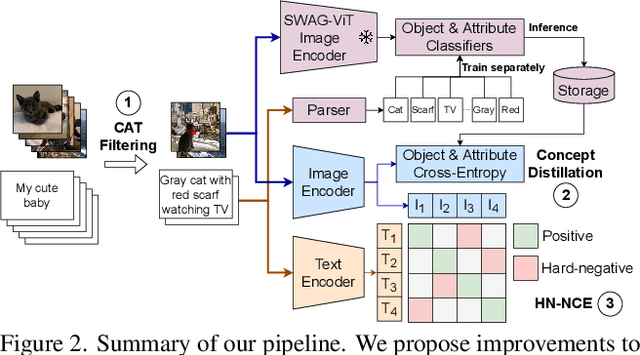
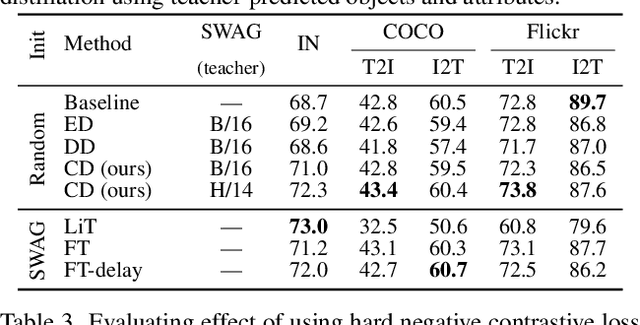
Vision-language models trained with contrastive learning on large-scale noisy data are becoming increasingly popular for zero-shot recognition problems. In this paper we improve the following three aspects of the contrastive pre-training pipeline: dataset noise, model initialization and the training objective. First, we propose a straightforward filtering strategy titled Complexity, Action, and Text-spotting (CAT) that significantly reduces dataset size, while achieving improved performance across zero-shot vision-language tasks. Next, we propose an approach titled Concept Distillation to leverage strong unimodal representations for contrastive training that does not increase training complexity while outperforming prior work. Finally, we modify the traditional contrastive alignment objective, and propose an importance-sampling approach to up-sample the importance of hard-negatives without adding additional complexity. On an extensive zero-shot benchmark of 29 tasks, our Distilled and Hard-negative Training (DiHT) approach improves on 20 tasks compared to the baseline. Furthermore, for few-shot linear probing, we propose a novel approach that bridges the gap between zero-shot and few-shot performance, substantially improving over prior work. Models are available at https://github.com/facebookresearch/diht.
Discovering Object Masks with Transformers for Unsupervised Semantic Segmentation
Jun 13, 2022
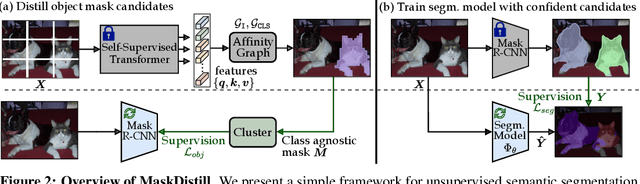
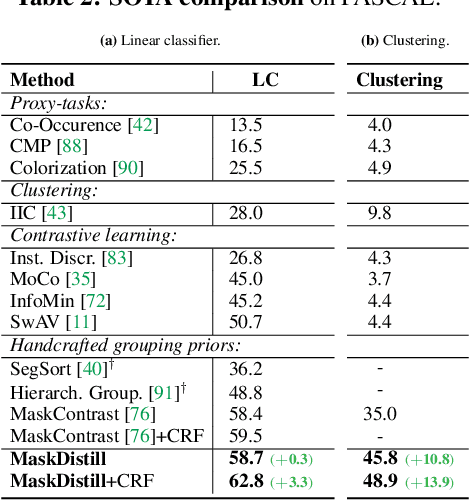
The task of unsupervised semantic segmentation aims to cluster pixels into semantically meaningful groups. Specifically, pixels assigned to the same cluster should share high-level semantic properties like their object or part category. This paper presents MaskDistill: a novel framework for unsupervised semantic segmentation based on three key ideas. First, we advocate a data-driven strategy to generate object masks that serve as a pixel grouping prior for semantic segmentation. This approach omits handcrafted priors, which are often designed for specific scene compositions and limit the applicability of competing frameworks. Second, MaskDistill clusters the object masks to obtain pseudo-ground-truth for training an initial object segmentation model. Third, we leverage this model to filter out low-quality object masks. This strategy mitigates the noise in our pixel grouping prior and results in a clean collection of masks which we use to train a final segmentation model. By combining these components, we can considerably outperform previous works for unsupervised semantic segmentation on PASCAL (+11% mIoU) and COCO (+4% mask AP50). Interestingly, as opposed to existing approaches, our framework does not latch onto low-level image cues and is not limited to object-centric datasets. The code and models will be made available.
Multi-Task Learning for Visual Scene Understanding
Mar 28, 2022


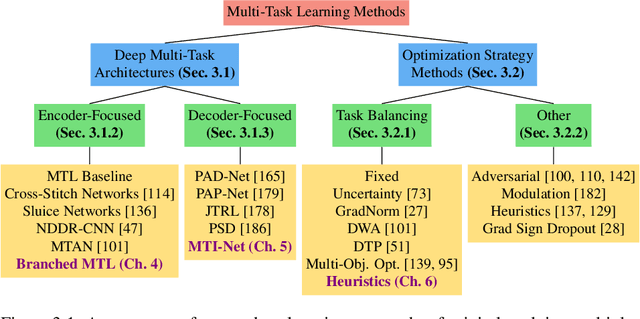
Despite the recent progress in deep learning, most approaches still go for a silo-like solution, focusing on learning each task in isolation: training a separate neural network for each individual task. Many real-world problems, however, call for a multi-modal approach and, therefore, for multi-tasking models. Multi-task learning (MTL) aims to leverage useful information across tasks to improve the generalization capability of a model. This thesis is concerned with multi-task learning in the context of computer vision. First, we review existing approaches for MTL. Next, we propose several methods that tackle important aspects of multi-task learning. The proposed methods are evaluated on various benchmarks. The results show several advances in the state-of-the-art of multi-task learning. Finally, we discuss several possibilities for future work.
Making Heads or Tails: Towards Semantically Consistent Visual Counterfactuals
Mar 24, 2022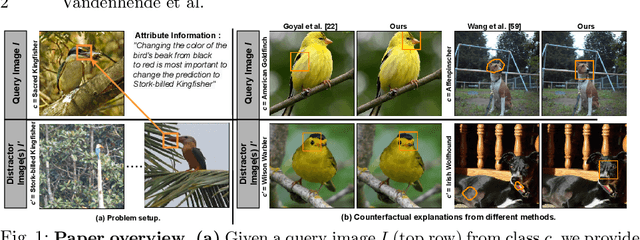
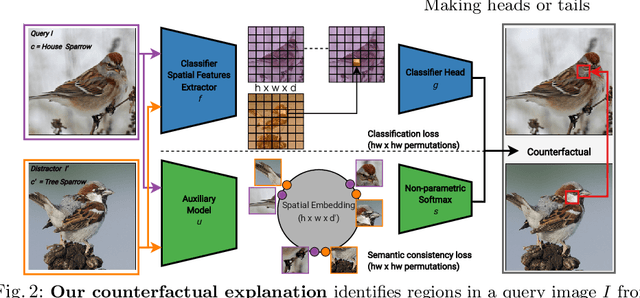
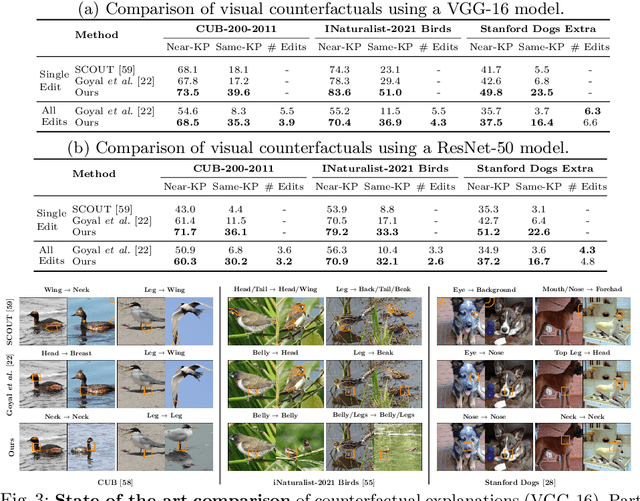

A visual counterfactual explanation replaces image regions in a query image with regions from a distractor image such that the system's decision on the transformed image changes to the distractor class. In this work, we present a novel framework for computing visual counterfactual explanations based on two key ideas. First, we enforce that the \textit{replaced} and \textit{replacer} regions contain the same semantic part, resulting in more semantically consistent explanations. Second, we use multiple distractor images in a computationally efficient way and obtain more discriminative explanations with fewer region replacements. Our approach is $\mathbf{27\%}$ more semantically consistent and an order of magnitude faster than a competing method on three fine-grained image recognition datasets. We highlight the utility of our counterfactuals over existing works through machine teaching experiments where we teach humans to classify different bird species. We also complement our explanations with the vocabulary of parts and attributes that contributed the most to the system's decision. In this task as well, we obtain state-of-the-art results when using our counterfactual explanations relative to existing works, reinforcing the importance of semantically consistent explanations.
Revisiting Contrastive Methods for Unsupervised Learning of Visual Representations
Jun 10, 2021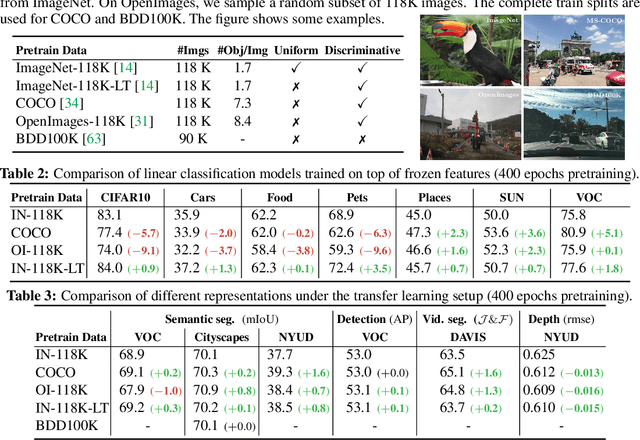
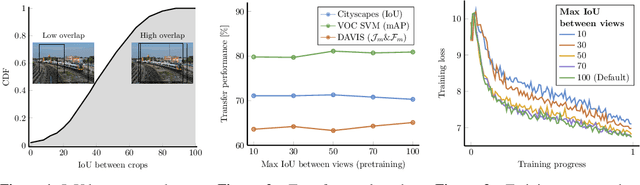
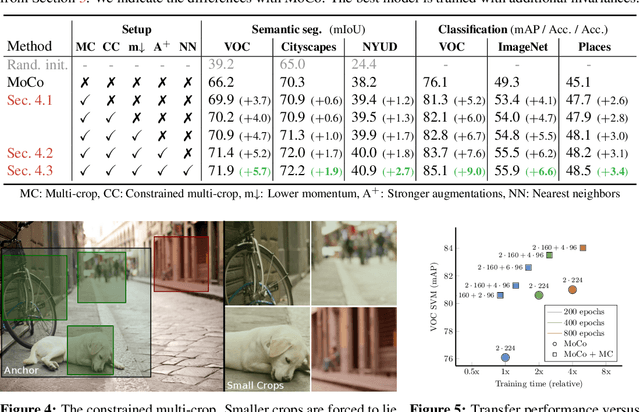
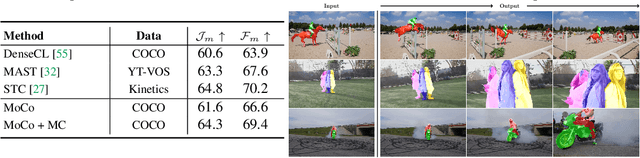
Contrastive self-supervised learning has outperformed supervised pretraining on many downstream tasks like segmentation and object detection. However, current methods are still primarily applied to curated datasets like ImageNet. In this paper, we first study how biases in the dataset affect existing methods. Our results show that current contrastive approaches work surprisingly well across: (i) object- versus scene-centric, (ii) uniform versus long-tailed and (iii) general versus domain-specific datasets. Second, given the generality of the approach, we try to realize further gains with minor modifications. We show that learning additional invariances -- through the use of multi-scale cropping, stronger augmentations and nearest neighbors -- improves the representations. Finally, we observe that MoCo learns spatially structured representations when trained with a multi-crop strategy. The representations can be used for semantic segment retrieval and video instance segmentation without finetuning. Moreover, the results are on par with specialized models. We hope this work will serve as a useful study for other researchers. The code and models will be available at https://github.com/wvangansbeke/Revisiting-Contrastive-SSL.
Unsupervised Semantic Segmentation by Contrasting Object Mask Proposals
Feb 11, 2021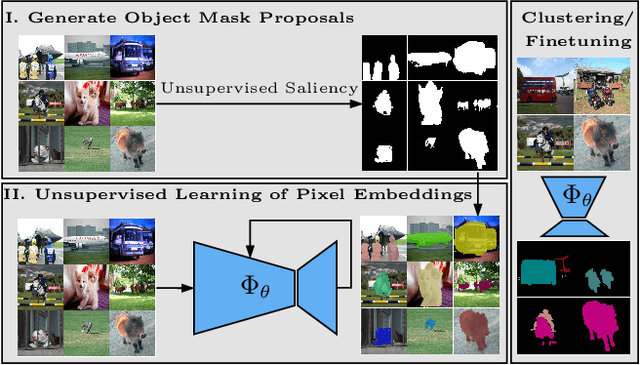
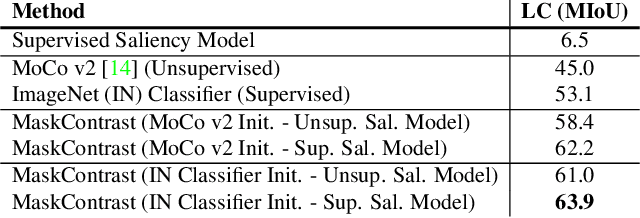
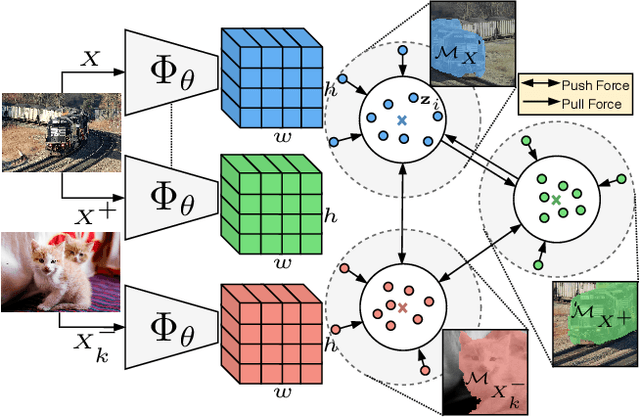

Being able to learn dense semantic representations of images without supervision is an important problem in computer vision. However, despite its significance, this problem remains rather unexplored, with a few exceptions that considered unsupervised semantic segmentation on small-scale datasets with a narrow visual domain. In this paper, we make a first attempt to tackle the problem on datasets that have been traditionally utilized for the supervised case. To achieve this, we introduce a novel two-step framework that adopts a predetermined prior in a contrastive optimization objective to learn pixel embeddings. This marks a large deviation from existing works that relied on proxy tasks or end-to-end clustering. Additionally, we argue about the importance of having a prior that contains information about objects, or their parts, and discuss several possibilities to obtain such a prior in an unsupervised manner. Extensive experimental evaluation shows that the proposed method comes with key advantages over existing works. First, the learned pixel embeddings can be directly clustered in semantic groups using K-Means. Second, the method can serve as an effective unsupervised pre-training for the semantic segmentation task. In particular, when fine-tuning the learned representations using just 1% of labeled examples on PASCAL, we outperform supervised ImageNet pre-training by 7.1% mIoU. The code is available at https://github.com/wvangansbeke/Unsupervised-Semantic-Segmentation.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
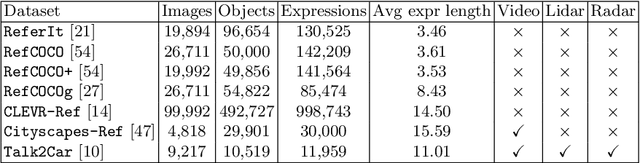

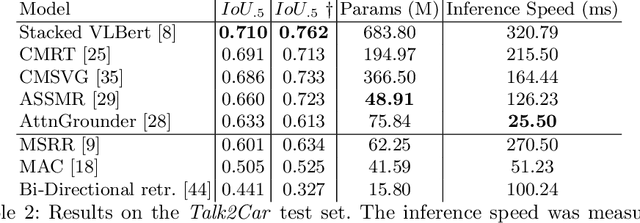
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.