 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Physical World Destinations for Commands Given to Self-Driving Cars
Dec 10, 2021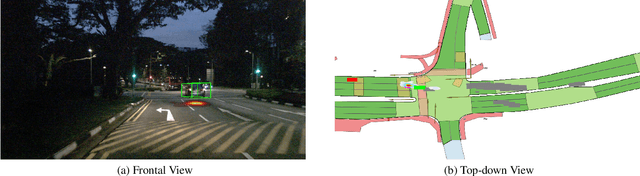

In recent years, we have seen significant steps taken in the development of self-driving cars. Multiple companies are starting to roll out impressive systems that work in a variety of settings. These systems can sometimes give the impression that full self-driving is just around the corner and that we would soon build cars without even a steering wheel. The increase in the level of autonomy and control given to an AI provides an opportunity for new modes of human-vehicle interaction. However, surveys have shown that giving more control to an AI in self-driving cars is accompanied by a degree of uneasiness by passengers. In an attempt to alleviate this issue, recent works have taken a natural language-oriented approach by allowing the passenger to give commands that refer to specific objects in the visual scene. Nevertheless, this is only half the task as the car should also understand the physical destination of the command, which is what we focus on in this paper. We propose an extension in which we annotate the 3D destination that the car needs to reach after executing the given command and evaluate multiple different baselines on predicting this destination location. Additionally, we introduce a model that outperforms the prior works adapted for this particular setting.
Giving Commands to a Self-Driving Car: How to Deal with Uncertain Situations?
Jun 08, 2021
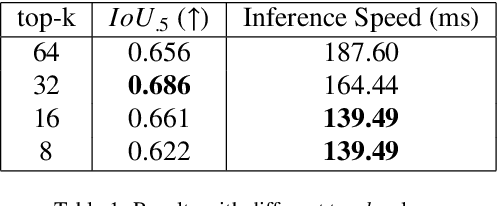
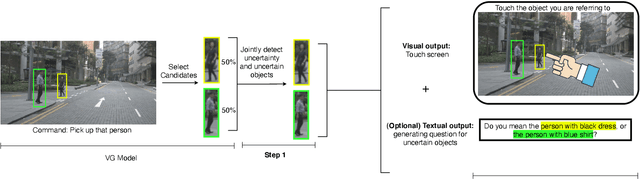
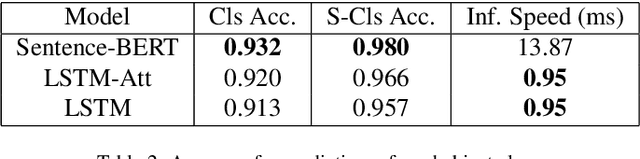
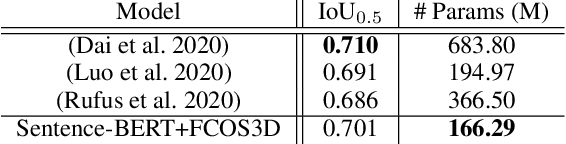
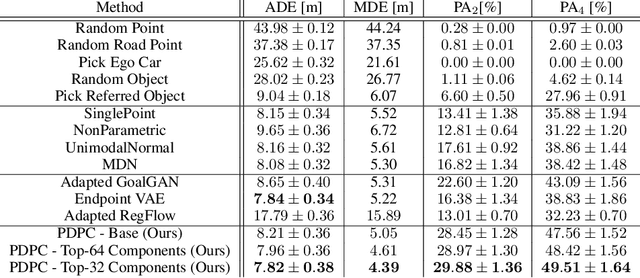
Current technology for autonomous cars primarily focuses on getting the passenger from point A to B. Nevertheless, it has been shown that passengers are afraid of taking a ride in self-driving cars. One way to alleviate this problem is by allowing the passenger to give natural language commands to the car. However, the car can misunderstand the issued command or the visual surroundings which could lead to uncertain situations. It is desirable that the self-driving car detects these situations and interacts with the passenger to solve them. This paper proposes a model that detects uncertain situations when a command is given and finds the visual objects causing it. Optionally, a question generated by the system describing the uncertain objects is included. We argue that if the car could explain the objects in a human-like way, passengers could gain more confidence in the car's abilities. Thus, we investigate how to (1) detect uncertain situations and their underlying causes, and (2) how to generate clarifying questions for the passenger. When evaluating on the Talk2Car dataset, we show that the proposed model, \acrfull{pipeline}, improves \gls{m:ambiguous-absolute-increase} in terms of $IoU_{.5}$ compared to not using \gls{pipeline}. Furthermore, we designed a referring expression generator (REG) \acrfull{reg_model} tailored to a self-driving car setting which yields a relative improvement of \gls{m:meteor-relative} METEOR and \gls{m:rouge-relative} ROUGE-l compared with state-of-the-art REG models, and is three times faster.
Commands 4 Autonomous Vehicles (C4AV) Workshop Summary
Sep 18, 2020
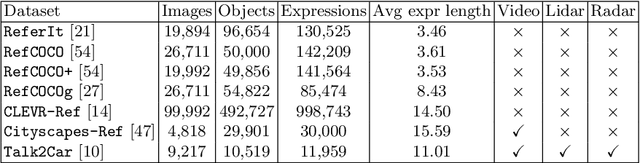

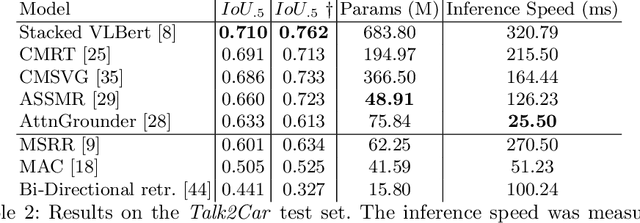
The task of visual grounding requires locating the most relevant region or object in an image, given a natural language query. So far, progress on this task was mostly measured on curated datasets, which are not always representative of human spoken language. In this work, we deviate from recent, popular task settings and consider the problem under an autonomous vehicle scenario. In particular, we consider a situation where passengers can give free-form natural language commands to a vehicle which can be associated with an object in the street scene. To stimulate research on this topic, we have organized the \emph{Commands for Autonomous Vehicles} (C4AV) challenge based on the recent \emph{Talk2Car} dataset (URL: https://www.aicrowd.com/challenges/eccv-2020-commands-4-autonomous-vehicles). This paper presents the results of the challenge. First, we compare the used benchmark against existing datasets for visual grounding. Second, we identify the aspects that render top-performing models successful, and relate them to existing state-of-the-art models for visual grounding, in addition to detecting potential failure cases by evaluating on carefully selected subsets. Finally, we discuss several possibilities for future work.
A Baseline for the Commands For Autonomous Vehicles Challenge
Apr 20, 2020
The Commands For Autonomous Vehicles (C4AV) challenge requires participants to solve an object referral task in a real-world setting. More specifically, we consider a scenario where a passenger can pass free-form natural language commands to a self-driving car. This problem is particularly challenging, as the language is much less constrained compared to existing benchmarks, and object references are often implicit. The challenge is based on the recent \texttt{Talk2Car} dataset. This document provides a technical overview of a model that we released to help participants get started in the competition. The code can be found at https://github.com/talk2car/Talk2Car.
Giving Commands to a Self-driving Car: A Multimodal Reasoner for Visual Grounding
Mar 19, 2020
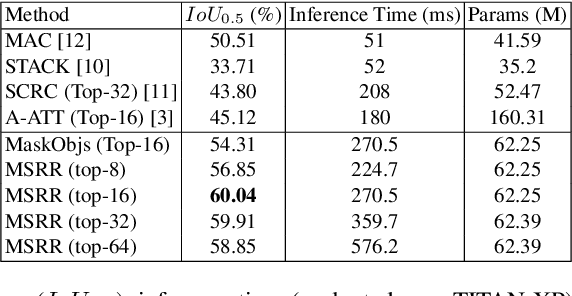
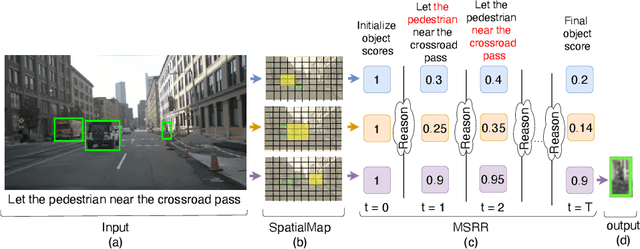
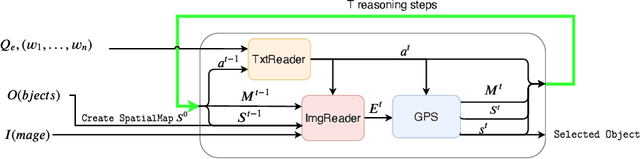
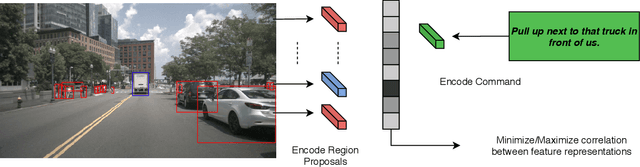
We propose a new spatial memory module and a spatial reasoner for the Visual Grounding (VG) task. The goal of this task is to find a certain object in an image based on a given textual query. Our work focuses on integrating the regions of a Region Proposal Network (RPN) into a new multi-step reasoning model which we have named a Multimodal Spatial Region Reasoner (MSRR). The introduced model uses the object regions from an RPN as initialization of a 2D spatial memory and then implements a multi-step reasoning process scoring each region according to the query, hence why we call it a multimodal reasoner. We evaluate this new model on challenging datasets and our experiments show that our model that jointly reasons over the object regions of the image and words of the query largely improves accuracy compared to current state-of-the-art models.
Talk2Car: Taking Control of Your Self-Driving Car
Sep 24, 2019

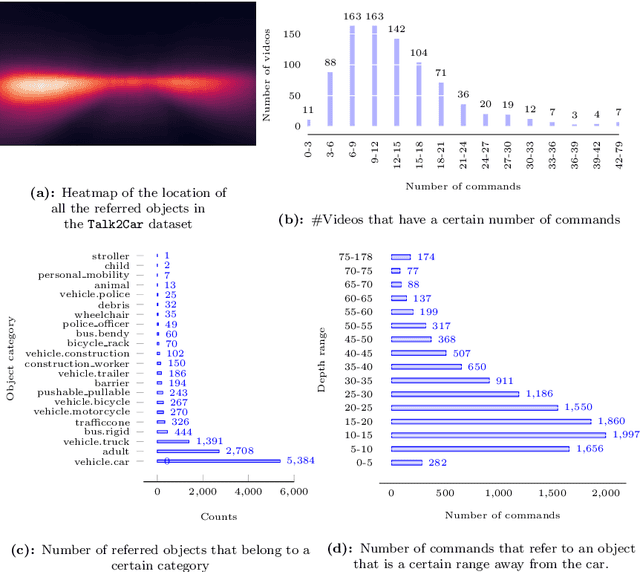
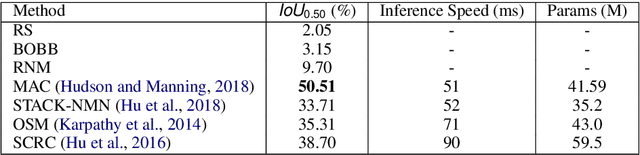
A long-term goal of artificial intelligence is to have an agent execute commands communicated through natural language. In many cases the commands are grounded in a visual environment shared by the human who gives the command and the agent. Execution of the command then requires mapping the command into the physical visual space, after which the appropriate action can be taken. In this paper we consider the former. Or more specifically, we consider the problem in an autonomous driving setting, where a passenger requests an action that can be associated with an object found in a street scene. Our work presents the Talk2Car dataset, which is the first object referral dataset that contains commands written in natural language for self-driving cars. We provide a detailed comparison with related datasets such as ReferIt, RefCOCO, RefCOCO+, RefCOCOg, Cityscape-Ref and CLEVR-Ref. Additionally, we include a performance analysis using strong state-of-the-art models. The results show that the proposed object referral task is a challenging one for which the models show promising results but still require additional research in natural language processing, computer vision and the intersection of these fields. The dataset can be found on our website: http://macchina-ai.eu/