 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGiving Commands to a Self-driving Car: A Multimodal Reasoner for Visual Grounding
Paper and Code
Mar 19, 2020
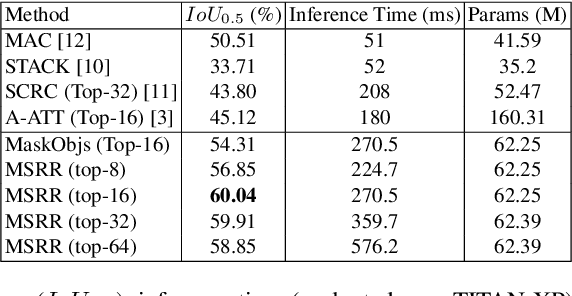
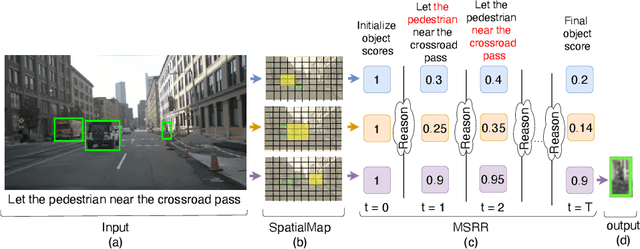
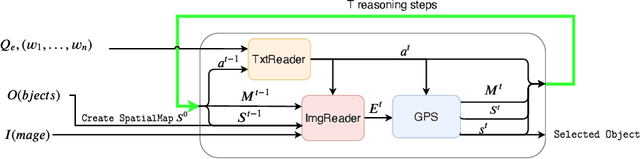
We propose a new spatial memory module and a spatial reasoner for the Visual Grounding (VG) task. The goal of this task is to find a certain object in an image based on a given textual query. Our work focuses on integrating the regions of a Region Proposal Network (RPN) into a new multi-step reasoning model which we have named a Multimodal Spatial Region Reasoner (MSRR). The introduced model uses the object regions from an RPN as initialization of a 2D spatial memory and then implements a multi-step reasoning process scoring each region according to the query, hence why we call it a multimodal reasoner. We evaluate this new model on challenging datasets and our experiments show that our model that jointly reasons over the object regions of the image and words of the query largely improves accuracy compared to current state-of-the-art models.