 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Forgetting in Large Language Models: A Survey of Unlearning Methods
Apr 02, 2024The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Giving Commands to a Self-driving Car: A Multimodal Reasoner for Visual Grounding
Mar 19, 2020
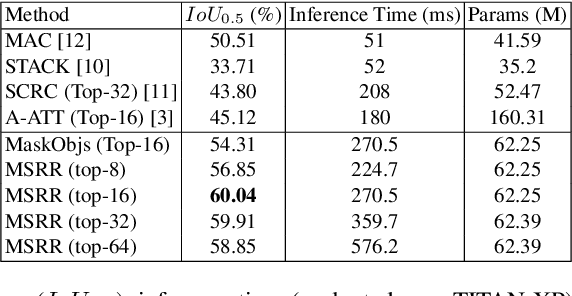
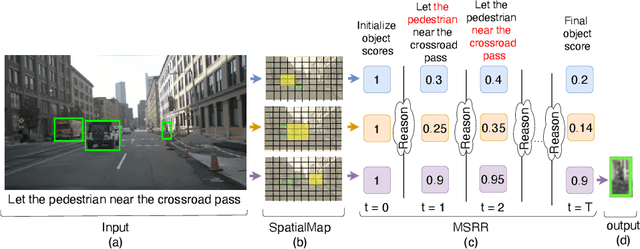
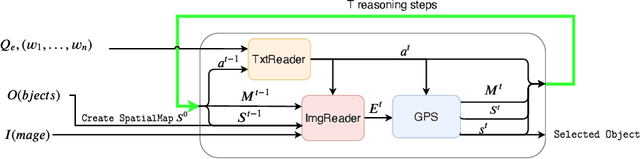
We propose a new spatial memory module and a spatial reasoner for the Visual Grounding (VG) task. The goal of this task is to find a certain object in an image based on a given textual query. Our work focuses on integrating the regions of a Region Proposal Network (RPN) into a new multi-step reasoning model which we have named a Multimodal Spatial Region Reasoner (MSRR). The introduced model uses the object regions from an RPN as initialization of a 2D spatial memory and then implements a multi-step reasoning process scoring each region according to the query, hence why we call it a multimodal reasoner. We evaluate this new model on challenging datasets and our experiments show that our model that jointly reasons over the object regions of the image and words of the query largely improves accuracy compared to current state-of-the-art models.
Do Neural Network Cross-Modal Mappings Really Bridge Modalities?
Jun 04, 2018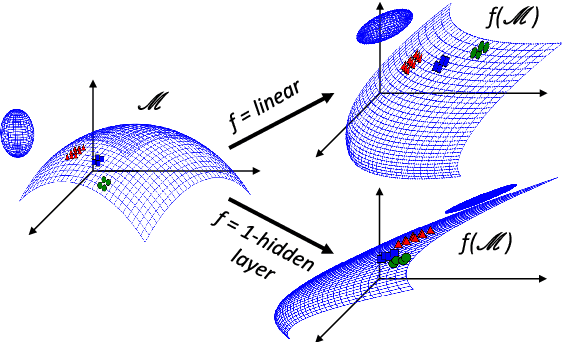
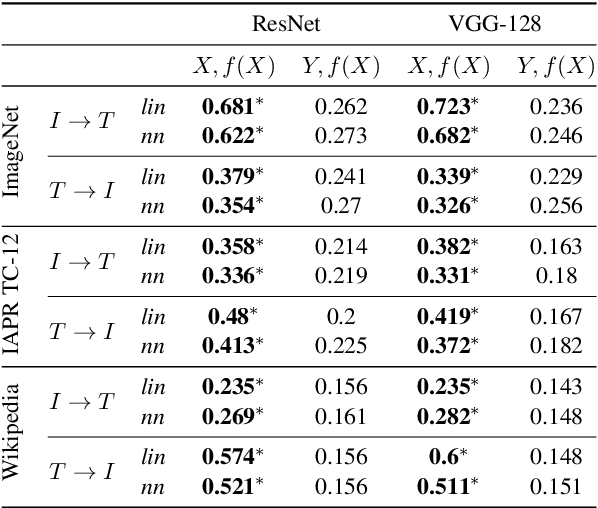
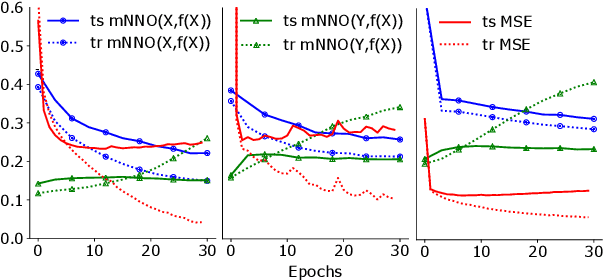
Feed-forward networks are widely used in cross-modal applications to bridge modalities by mapping distributed vectors of one modality to the other, or to a shared space. The predicted vectors are then used to perform e.g., retrieval or labeling. Thus, the success of the whole system relies on the ability of the mapping to make the neighborhood structure (i.e., the pairwise similarities) of the predicted vectors akin to that of the target vectors. However, whether this is achieved has not been investigated yet. Here, we propose a new similarity measure and two ad hoc experiments to shed light on this issue. In three cross-modal benchmarks we learn a large number of language-to-vision and vision-to-language neural network mappings (up to five layers) using a rich diversity of image and text features and loss functions. Our results reveal that, surprisingly, the neighborhood structure of the predicted vectors consistently resembles more that of the input vectors than that of the target vectors. In a second experiment, we further show that untrained nets do not significantly disrupt the neighborhood (i.e., semantic) structure of the input vectors.
Acquiring Common Sense Spatial Knowledge through Implicit Spatial Templates
Nov 21, 2017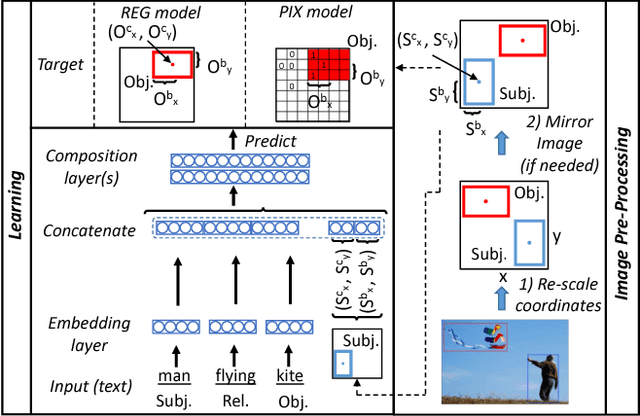
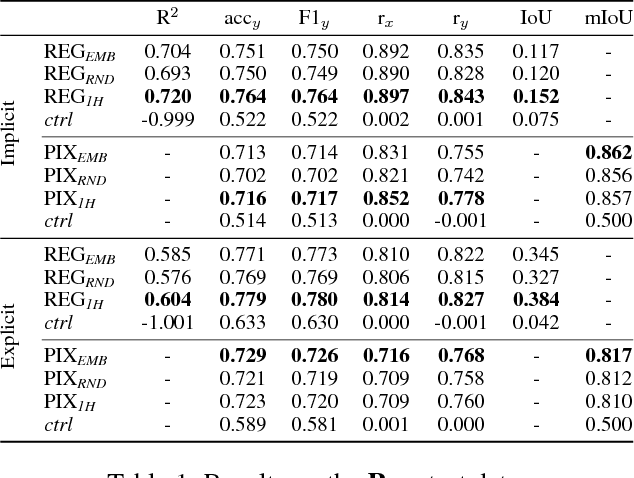

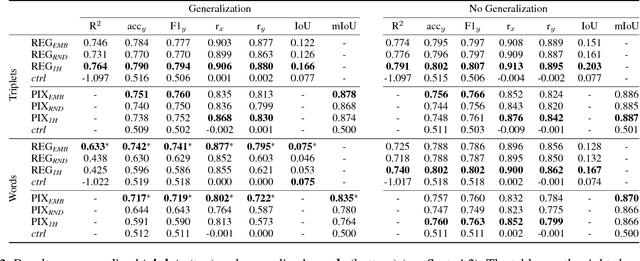
Spatial understanding is a fundamental problem with wide-reaching real-world applications. The representation of spatial knowledge is often modeled with spatial templates, i.e., regions of acceptability of two objects under an explicit spatial relationship (e.g., "on", "below", etc.). In contrast with prior work that restricts spatial templates to explicit spatial prepositions (e.g., "glass on table"), here we extend this concept to implicit spatial language, i.e., those relationships (generally actions) for which the spatial arrangement of the objects is only implicitly implied (e.g., "man riding horse"). In contrast with explicit relationships, predicting spatial arrangements from implicit spatial language requires significant common sense spatial understanding. Here, we introduce the task of predicting spatial templates for two objects under a relationship, which can be seen as a spatial question-answering task with a (2D) continuous output ("where is the man w.r.t. a horse when the man is walking the horse?"). We present two simple neural-based models that leverage annotated images and structured text to learn this task. The good performance of these models reveals that spatial locations are to a large extent predictable from implicit spatial language. Crucially, the models attain similar performance in a challenging generalized setting, where the object-relation-object combinations (e.g.,"man walking dog") have never been seen before. Next, we go one step further by presenting the models with unseen objects (e.g., "dog"). In this scenario, we show that leveraging word embeddings enables the models to output accurate spatial predictions, proving that the models acquire solid common sense spatial knowledge allowing for such generalization.
Reviving Threshold-Moving: a Simple Plug-in Bagging Ensemble for Binary and Multiclass Imbalanced Data
Jun 20, 2017
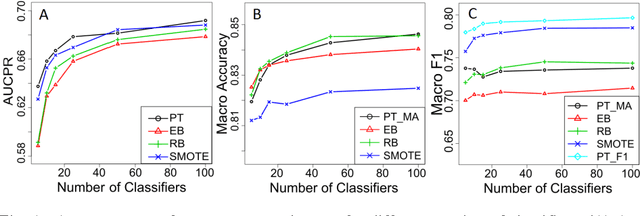
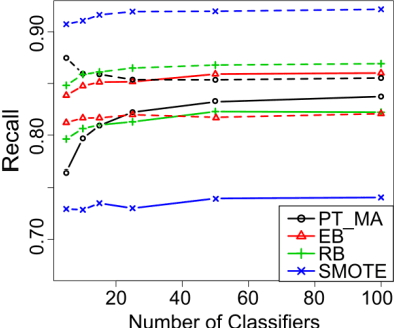
Class imbalance presents a major hurdle in the application of data mining methods. A common practice to deal with it is to create ensembles of classifiers that learn from resampled balanced data. For example, bagged decision trees combined with random undersampling (RUS) or the synthetic minority oversampling technique (SMOTE). However, most of the resampling methods entail asymmetric changes to the examples of different classes, which in turn can introduce its own biases in the model. Furthermore, those methods require a performance measure to be specified a priori before learning. An alternative is to use a so-called threshold-moving method that a posteriori changes the decision threshold of a model to counteract the imbalance, thus has a potential to adapt to the performance measure of interest. Surprisingly, little attention has been paid to the potential of combining bagging ensemble with threshold-moving. In this paper, we present probability thresholding bagging (PT-bagging), a versatile plug-in method that fills this gap. Contrary to usual rebalancing practice, our method preserves the natural class distribution of the data resulting in well calibrated posterior probabilities. We also extend the proposed method to handle multiclass data. The method is validated on binary and multiclass benchmark data sets. We perform analyses that provide insights into the proposed method.
Learning to Predict: A Fast Re-constructive Method to Generate Multimodal Embeddings
Mar 25, 2017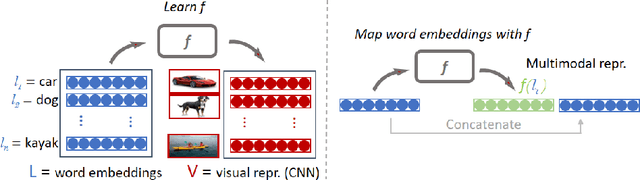
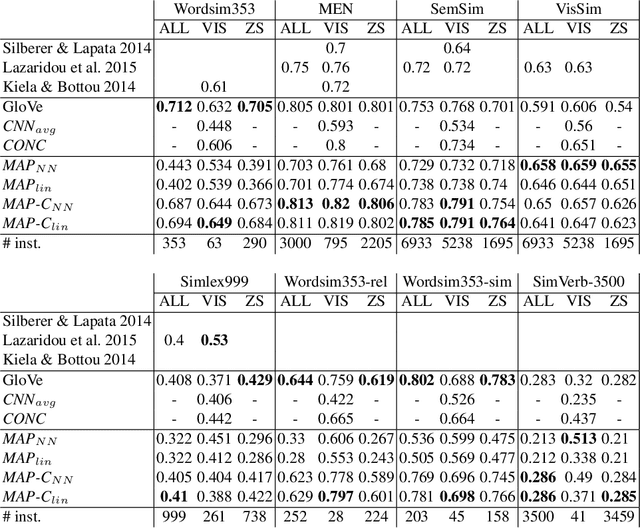

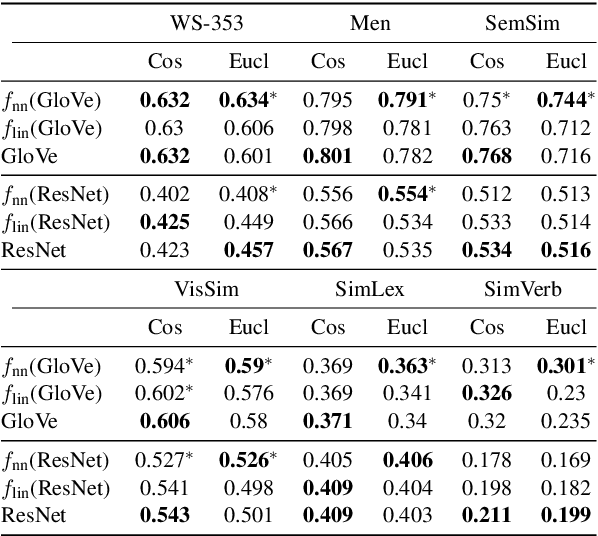
Integrating visual and linguistic information into a single multimodal representation is an unsolved problem with wide-reaching applications to both natural language processing and computer vision. In this paper, we present a simple method to build multimodal representations by learning a language-to-vision mapping and using its output to build multimodal embeddings. In this sense, our method provides a cognitively plausible way of building representations, consistent with the inherently re-constructive and associative nature of human memory. Using seven benchmark concept similarity tests we show that the mapped vectors not only implicitly encode multimodal information, but also outperform strong unimodal baselines and state-of-the-art multimodal methods, thus exhibiting more "human-like" judgments---particularly in zero-shot settings.