 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCybench: A Framework for Evaluating Cybersecurity Capabilities and Risk of Language Models
Aug 15, 2024Language Model (LM) agents for cybersecurity that are capable of autonomously identifying vulnerabilities and executing exploits have the potential to cause real-world impact. Policymakers, model providers, and other researchers in the AI and cybersecurity communities are interested in quantifying the capabilities of such agents to help mitigate cyberrisk and investigate opportunities for penetration testing. Toward that end, we introduce Cybench, a framework for specifying cybersecurity tasks and evaluating agents on those tasks. We include 40 professional-level Capture the Flag (CTF) tasks from 4 distinct CTF competitions, chosen to be recent, meaningful, and spanning a wide range of difficulties. Each task includes its own description, starter files, and is initialized in an environment where an agent can execute bash commands and observe outputs. Since many tasks are beyond the capabilities of existing LM agents, we introduce subtasks, which break down a task into intermediary steps for more gradated evaluation; we add subtasks for 17 of the 40 tasks. To evaluate agent capabilities, we construct a cybersecurity agent and evaluate 7 models: GPT-4o, Claude 3 Opus, Claude 3.5 Sonnet, Mixtral 8x22b Instruct, Gemini 1.5 Pro, Llama 3 70B Chat, and Llama 3.1 405B Instruct. Without guidance, we find that agents are able to solve only the easiest complete tasks that took human teams up to 11 minutes to solve, with Claude 3.5 Sonnet and GPT-4o having the highest success rates. Finally, subtasks provide more signal for measuring performance compared to unguided runs, with models achieving a 3.2\% higher success rate on complete tasks with subtask-guidance than without subtask-guidance. All code and data are publicly available at https://cybench.github.io
Learning to Predict: A Fast Re-constructive Method to Generate Multimodal Embeddings
Mar 25, 2017
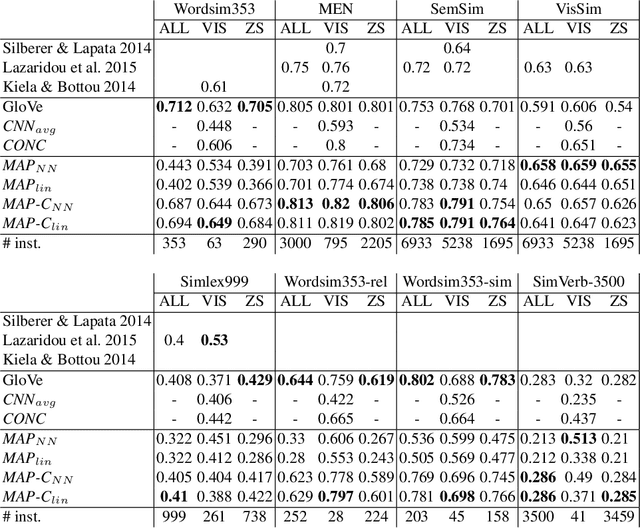

Integrating visual and linguistic information into a single multimodal representation is an unsolved problem with wide-reaching applications to both natural language processing and computer vision. In this paper, we present a simple method to build multimodal representations by learning a language-to-vision mapping and using its output to build multimodal embeddings. In this sense, our method provides a cognitively plausible way of building representations, consistent with the inherently re-constructive and associative nature of human memory. Using seven benchmark concept similarity tests we show that the mapped vectors not only implicitly encode multimodal information, but also outperform strong unimodal baselines and state-of-the-art multimodal methods, thus exhibiting more "human-like" judgments---particularly in zero-shot settings.