 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Predict: A Fast Re-constructive Method to Generate Multimodal Embeddings
Paper and Code
Mar 25, 2017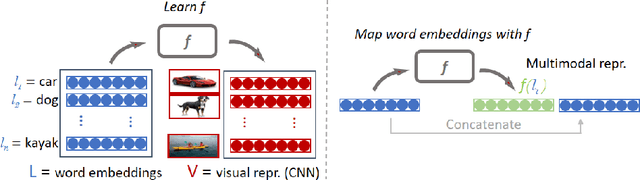
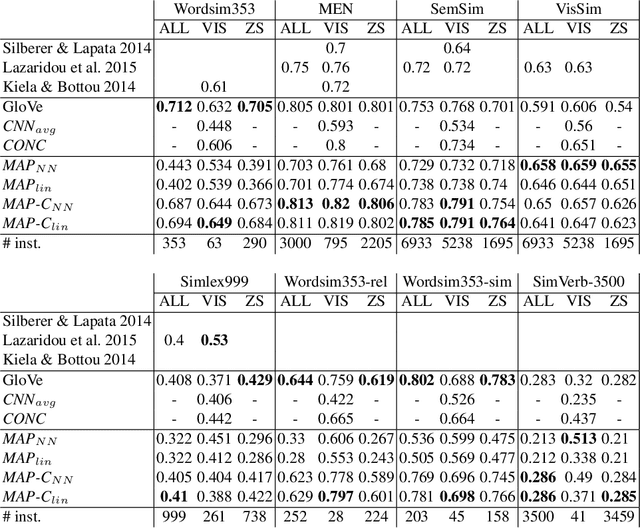

Integrating visual and linguistic information into a single multimodal representation is an unsolved problem with wide-reaching applications to both natural language processing and computer vision. In this paper, we present a simple method to build multimodal representations by learning a language-to-vision mapping and using its output to build multimodal embeddings. In this sense, our method provides a cognitively plausible way of building representations, consistent with the inherently re-constructive and associative nature of human memory. Using seven benchmark concept similarity tests we show that the mapped vectors not only implicitly encode multimodal information, but also outperform strong unimodal baselines and state-of-the-art multimodal methods, thus exhibiting more "human-like" judgments---particularly in zero-shot settings.