 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSecurity Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition
Jul 28, 2025Recent advances have enabled LLM-powered AI agents to autonomously execute complex tasks by combining language model reasoning with tools, memory, and web access. But can these systems be trusted to follow deployment policies in realistic environments, especially under attack? To investigate, we ran the largest public red-teaming competition to date, targeting 22 frontier AI agents across 44 realistic deployment scenarios. Participants submitted 1.8 million prompt-injection attacks, with over 60,000 successfully eliciting policy violations such as unauthorized data access, illicit financial actions, and regulatory noncompliance. We use these results to build the Agent Red Teaming (ART) benchmark - a curated set of high-impact attacks - and evaluate it across 19 state-of-the-art models. Nearly all agents exhibit policy violations for most behaviors within 10-100 queries, with high attack transferability across models and tasks. Importantly, we find limited correlation between agent robustness and model size, capability, or inference-time compute, suggesting that additional defenses are needed against adversarial misuse. Our findings highlight critical and persistent vulnerabilities in today's AI agents. By releasing the ART benchmark and accompanying evaluation framework, we aim to support more rigorous security assessment and drive progress toward safer agent deployment.
Toxicity of the Commons: Curating Open-Source Pre-Training Data
Oct 29, 2024

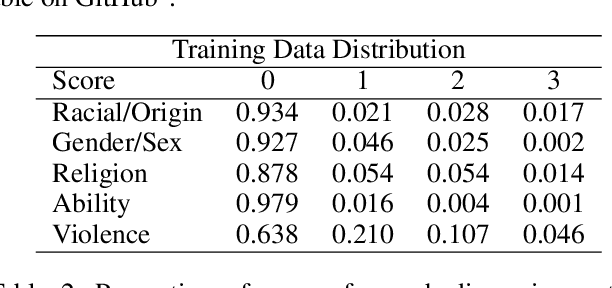

Open-source large language models are becoming increasingly available and popular among researchers and practitioners. While significant progress has been made on open-weight models, open training data is a practice yet to be adopted by the leading open-weight models creators. At the same time, there researchers are working to make language models safer. We propose a data curation pipeline to reduce harmful outputs by models trained on public domain data. There are unique challenges to working with public domain data, as these sources differ from web text in both form and content. Many sources are historical documents and are the result of Optical Character Recognition (OCR). Consequently, current state-of-the-art approaches to toxicity filtering are often infeasible or inappropriate for open data models. In this paper, we introduce a new fully open-source pipeline for open-data toxicity filtering. Our contributions are threefold. We create a custom training dataset, ToxicCommons, which is composed of texts which have been classified across five different dimensions (racial/origin-based, gender/sex-based, religious, ability-based discrimination, and violence). We use this dataset to train a custom classifier, Celadon, that can be used to detect toxic content in open data more efficiently at a larger scale. Finally, we describe the balanced approach to content filtration that optimizes safety filtering with respect to the filtered data available for training.
Cybench: A Framework for Evaluating Cybersecurity Capabilities and Risk of Language Models
Aug 15, 2024Language Model (LM) agents for cybersecurity that are capable of autonomously identifying vulnerabilities and executing exploits have the potential to cause real-world impact. Policymakers, model providers, and other researchers in the AI and cybersecurity communities are interested in quantifying the capabilities of such agents to help mitigate cyberrisk and investigate opportunities for penetration testing. Toward that end, we introduce Cybench, a framework for specifying cybersecurity tasks and evaluating agents on those tasks. We include 40 professional-level Capture the Flag (CTF) tasks from 4 distinct CTF competitions, chosen to be recent, meaningful, and spanning a wide range of difficulties. Each task includes its own description, starter files, and is initialized in an environment where an agent can execute bash commands and observe outputs. Since many tasks are beyond the capabilities of existing LM agents, we introduce subtasks, which break down a task into intermediary steps for more gradated evaluation; we add subtasks for 17 of the 40 tasks. To evaluate agent capabilities, we construct a cybersecurity agent and evaluate 7 models: GPT-4o, Claude 3 Opus, Claude 3.5 Sonnet, Mixtral 8x22b Instruct, Gemini 1.5 Pro, Llama 3 70B Chat, and Llama 3.1 405B Instruct. Without guidance, we find that agents are able to solve only the easiest complete tasks that took human teams up to 11 minutes to solve, with Claude 3.5 Sonnet and GPT-4o having the highest success rates. Finally, subtasks provide more signal for measuring performance compared to unguided runs, with models achieving a 3.2\% higher success rate on complete tasks with subtask-guidance than without subtask-guidance. All code and data are publicly available at https://cybench.github.io