 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Review on the Effectiveness and Privacy Threats of Membership Inference Attacks
Mar 24, 2026Membership inference attacks (MIAs) aim to determine whether a data sample was included in a machine learning (ML) model's training set and have become the de facto standard for measuring privacy leakages in ML. We propose an evaluation framework that defines the conditions under which MIAs constitute a genuine privacy threat, and review representative MIAs against it. We find that, under the realistic conditions defined in our framework, MIAs represent weak privacy threats. Thus, relying on them as a privacy metric in ML can lead to an overestimation of risk and to unnecessary sacrifices in model utility as a consequence of employing too strong defenses.
Revisiting the LiRA Membership Inference Attack Under Realistic Assumptions
Mar 08, 2026Membership inference attacks (MIAs) have become the standard tool for evaluating privacy leakage in machine learning (ML). Among them, the Likelihood-Ratio Attack (LiRA) is widely regarded as the state of the art when sufficient shadow models are available. However, prior evaluations have often overstated the effectiveness of LiRA by attacking models overconfident on their training samples, calibrating thresholds on target data, assuming balanced membership priors, and/or overlooking attack reproducibility. We re-evaluate LiRA under a realistic protocol that (i) trains models using anti-overfitting (AOF) and transfer learning (TL), when applicable, to reduce overconfidence as in production models; (ii) calibrates decision thresholds using shadow models and data rather than target data; (iii) measures positive predictive value (PPV, or precision) under shadow-based thresholds and skewed membership priors (pi <= 10%); and (iv) quantifies per-sample membership reproducibility across different seeds and training variations. We find that AOF significantly weakens LiRA, while TL further reduces attack effectiveness while improving model accuracy. Under shadow-based thresholds and skewed priors, LiRA's PPV often drops substantially, especially under AOF or AOF+TL. We also find that thresholded vulnerable sets at extremely low FPR show poor reproducibility across runs, while likelihood-ratio rankings are more stable. These results suggest that LiRA, and likely weaker MIAs, are less effective than previously suggested under realistic conditions, and that reliable privacy auditing requires evaluation protocols that reflect practical training practices, feasible attacker assumptions, and reproducibility considerations. Code is available at https://github.com/najeebjebreel/lira_analysis.
Truthful Text Sanitization Guided by Inference Attacks
Dec 17, 2024



The purpose of text sanitization is to rewrite those text spans in a document that may directly or indirectly identify an individual, to ensure they no longer disclose personal information. Text sanitization must strike a balance between preventing the leakage of personal information (privacy protection) while also retaining as much of the document's original content as possible (utility preservation). We present an automated text sanitization strategy based on generalizations, which are more abstract (but still informative) terms that subsume the semantic content of the original text spans. The approach relies on instruction-tuned large language models (LLMs) and is divided into two stages. The LLM is first applied to obtain truth-preserving replacement candidates and rank them according to their abstraction level. Those candidates are then evaluated for their ability to protect privacy by conducting inference attacks with the LLM. Finally, the system selects the most informative replacement shown to be resistant to those attacks. As a consequence of this two-stage process, the chosen replacements effectively balance utility and privacy. We also present novel metrics to automatically evaluate these two aspects without the need to manually annotate data. Empirical results on the Text Anonymization Benchmark show that the proposed approach leads to enhanced utility, with only a marginal increase in the risk of re-identifying protected individuals compared to fully suppressing the original information. Furthermore, the selected replacements are shown to be more truth-preserving and abstractive than previous methods.
Mobile IoT device for BPM monitoring people with heart problems
Oct 08, 2024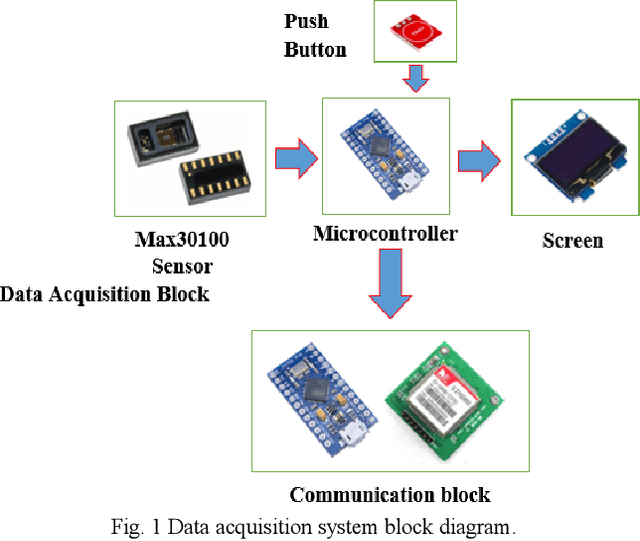
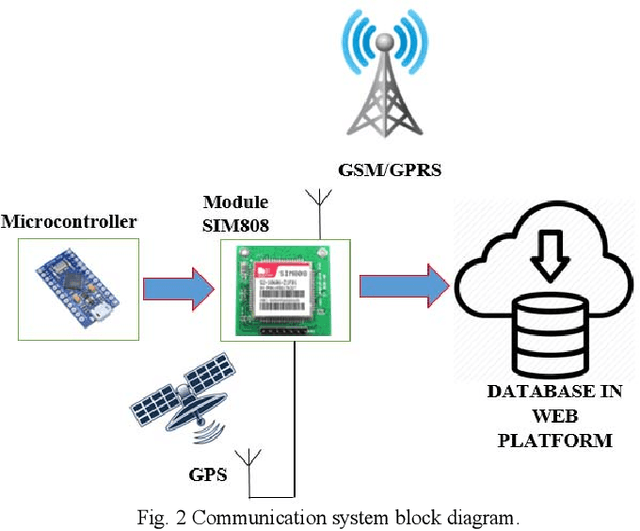
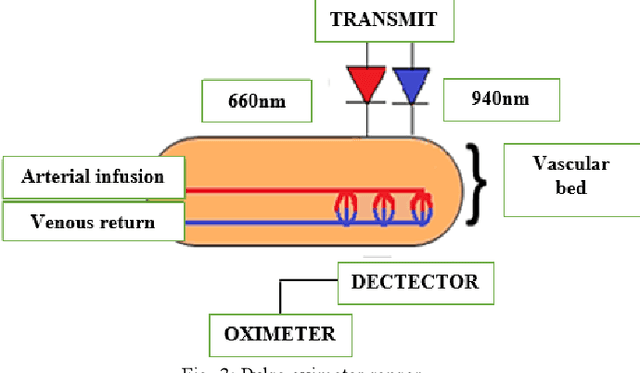

The developed system using a mobile electronic device for monitoring and warnings of heart problems, when the heart rate is outside the nominal range, which ranges from 60 to 100 beats per minute. Also, a system has been developed to save and monitor in real time changes of the cardiac pulsations, through a sensor connected to a control system. The connection of the communication module for Arduino GSM/GPRS/GPS, using the GPS network to locate the user. In addition, this device connects with GSM / GPRS technology that allows text messages to be sent to the contact number configured in the device, when warnings of heart problems are issued, moreover connects to the internet to store data in the cloud.
* 5 pages, 13 figures
Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
Apr 02, 2024The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Exploring language relations through syntactic distances and geographic proximity
Mar 27, 2024Languages are grouped into families that share common linguistic traits. While this approach has been successful in understanding genetic relations between diverse languages, more analyses are needed to accurately quantify their relatedness, especially in less studied linguistic levels such as syntax. Here, we explore linguistic distances using series of parts of speech (POS) extracted from the Universal Dependencies dataset. Within an information-theoretic framework, we show that employing POS trigrams maximizes the possibility of capturing syntactic variations while being at the same time compatible with the amount of available data. Linguistic connections are then established by assessing pairwise distances based on the POS distributions. Intriguingly, our analysis reveals definite clusters that correspond to well known language families and groups, with exceptions explained by distinct morphological typologies. Furthermore, we obtain a significant correlation between language similarity and geographic distance, which underscores the influence of spatial proximity on language kinships.
Multi-Task Faces Data Set: A Legally and Ethically Compliant Collection of Face Images for Various Classification Tasks
Nov 20, 2023



Human facial data hold tremendous potential to address a variety of classification problems, including face recognition, age estimation, gender identification, emotion analysis, and race classification. However, recent privacy regulations, such as the EU General Data Protection Regulation and others, have restricted the ways in which human images may be collected and used for research. As a result, several previously published data sets containing human faces have been removed from the internet due to inadequate data collection methods that failed to meet privacy regulations. Data sets consisting of synthetic data have been proposed as an alternative, but they fall short of accurately representing the real data distribution. On the other hand, most available data sets are labeled for just a single task, which limits their applicability. To address these issues, we present the Multi-Task Faces (MTF) image data set, a meticulously curated collection of face images designed for various classification tasks, including face recognition, as well as race, gender, and age classification. The MTF data set has been ethically gathered by leveraging publicly available images of celebrities and strictly adhering to copyright regulations. In this paper, we present this data set and provide detailed descriptions of the followed data collection and processing procedures. Furthermore, we evaluate the performance of five deep learning (DL) models on the MTF data set across the aforementioned classification tasks. Additionally, we compare the performance of DL models over the processed MTF data and over raw data crawled from the internet. The reported results constitute a baseline for further research employing these data. The MTF data set can be accessed through the following link (please cite the present paper if you use the data set): https://github.com/RamiHaf/MTF_data_set
An Examination of the Alleged Privacy Threats of Confidence-Ranked Reconstruction of Census Microdata
Nov 06, 2023



The alleged threat of reconstruction attacks has led the U.S. Census Bureau (USCB) to replace in the Decennial Census 2020 the traditional statistical disclosure limitation based on rank swapping with one based on differential privacy (DP). This has resulted in substantial accuracy loss of the released statistics. Worse yet, it has been shown that the reconstruction attacks used as an argument to move to DP are very far from allowing unequivocal reidentification of the respondents, because in general there are a lot of reconstructions compatible with the released statistics. In a very recent paper, a new reconstruction attack has been proposed, whose goal is to indicate the confidence that a reconstructed record was in the original respondent data. The alleged risk of serious disclosure entailed by such confidence-ranked reconstruction has renewed the interest of the USCB to use DP-based solutions. To forestall the potential accuracy loss in future data releases resulting from adoption of these solutions, we show in this paper that the proposed confidence-ranked reconstruction does not threaten privacy. Specifically, we report empirical results showing that the proposed ranking cannot guide reidentification or attribute disclosure attacks, and hence it fails to warrant the USCB's move towards DP. Further, we also demonstrate that, due to the way the Census data are compiled, processed and released, it is not possible to reconstruct original and complete records through any methodology, and the confidence-ranked reconstruction not only is completely ineffective at accurately reconstructing Census records but is trivially outperformed by an adequate interpretation of the released aggregate statistics.
Defending against the Label-flipping Attack in Federated Learning
Jul 05, 2022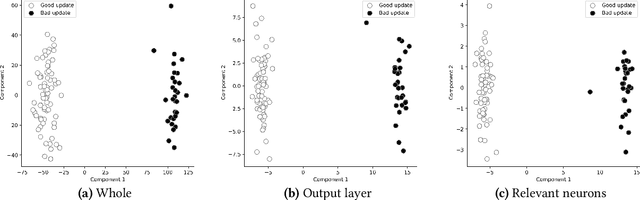

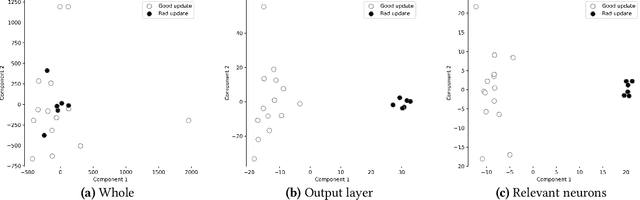

Federated learning (FL) provides autonomy and privacy by design to participating peers, who cooperatively build a machine learning (ML) model while keeping their private data in their devices. However, that same autonomy opens the door for malicious peers to poison the model by conducting either untargeted or targeted poisoning attacks. The label-flipping (LF) attack is a targeted poisoning attack where the attackers poison their training data by flipping the labels of some examples from one class (i.e., the source class) to another (i.e., the target class). Unfortunately, this attack is easy to perform and hard to detect and it negatively impacts on the performance of the global model. Existing defenses against LF are limited by assumptions on the distribution of the peers' data and/or do not perform well with high-dimensional models. In this paper, we deeply investigate the LF attack behavior and find that the contradicting objectives of attackers and honest peers on the source class examples are reflected in the parameter gradients corresponding to the neurons of the source and target classes in the output layer, making those gradients good discriminative features for the attack detection. Accordingly, we propose a novel defense that first dynamically extracts those gradients from the peers' local updates, and then clusters the extracted gradients, analyzes the resulting clusters and filters out potential bad updates before model aggregation. Extensive empirical analysis on three data sets shows the proposed defense's effectiveness against the LF attack regardless of the data distribution or model dimensionality. Also, the proposed defense outperforms several state-of-the-art defenses by offering lower test error, higher overall accuracy, higher source class accuracy, lower attack success rate, and higher stability of the source class accuracy.
The Text Anonymization Benchmark (TAB): A Dedicated Corpus and Evaluation Framework for Text Anonymization
Jan 25, 2022


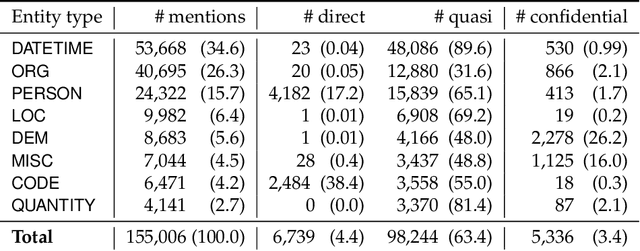
We present a novel benchmark and associated evaluation metrics for assessing the performance of text anonymization methods. Text anonymization, defined as the task of editing a text document to prevent the disclosure of personal information, currently suffers from a shortage of privacy-oriented annotated text resources, making it difficult to properly evaluate the level of privacy protection offered by various anonymization methods. This paper presents TAB (Text Anonymization Benchmark), a new, open-source annotated corpus developed to address this shortage. The corpus comprises 1,268 English-language court cases from the European Court of Human Rights (ECHR) enriched with comprehensive annotations about the personal information appearing in each document, including their semantic category, identifier type, confidential attributes, and co-reference relations. Compared to previous work, the TAB corpus is designed to go beyond traditional de-identification (which is limited to the detection of predefined semantic categories), and explicitly marks which text spans ought to be masked in order to conceal the identity of the person to be protected. Along with presenting the corpus and its annotation layers, we also propose a set of evaluation metrics that are specifically tailored towards measuring the performance of text anonymization, both in terms of privacy protection and utility preservation. We illustrate the use of the benchmark and the proposed metrics by assessing the empirical performance of several baseline text anonymization models. The full corpus along with its privacy-oriented annotation guidelines, evaluation scripts and baseline models are available on: https://github.com/NorskRegnesentral/text-anonymisation-benchmark