 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDigital Forgetting in Large Language Models: A Survey of Unlearning Methods
Apr 02, 2024The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
An Examination of the Alleged Privacy Threats of Confidence-Ranked Reconstruction of Census Microdata
Nov 06, 2023



The alleged threat of reconstruction attacks has led the U.S. Census Bureau (USCB) to replace in the Decennial Census 2020 the traditional statistical disclosure limitation based on rank swapping with one based on differential privacy (DP). This has resulted in substantial accuracy loss of the released statistics. Worse yet, it has been shown that the reconstruction attacks used as an argument to move to DP are very far from allowing unequivocal reidentification of the respondents, because in general there are a lot of reconstructions compatible with the released statistics. In a very recent paper, a new reconstruction attack has been proposed, whose goal is to indicate the confidence that a reconstructed record was in the original respondent data. The alleged risk of serious disclosure entailed by such confidence-ranked reconstruction has renewed the interest of the USCB to use DP-based solutions. To forestall the potential accuracy loss in future data releases resulting from adoption of these solutions, we show in this paper that the proposed confidence-ranked reconstruction does not threaten privacy. Specifically, we report empirical results showing that the proposed ranking cannot guide reidentification or attribute disclosure attacks, and hence it fails to warrant the USCB's move towards DP. Further, we also demonstrate that, due to the way the Census data are compiled, processed and released, it is not possible to reconstruct original and complete records through any methodology, and the confidence-ranked reconstruction not only is completely ineffective at accurately reconstructing Census records but is trivially outperformed by an adequate interpretation of the released aggregate statistics.
GRAIMATTER Green Paper: Recommendations for disclosure control of trained Machine Learning (ML) models from Trusted Research Environments (TREs)
Nov 03, 2022



TREs are widely, and increasingly used to support statistical analysis of sensitive data across a range of sectors (e.g., health, police, tax and education) as they enable secure and transparent research whilst protecting data confidentiality. There is an increasing desire from academia and industry to train AI models in TREs. The field of AI is developing quickly with applications including spotting human errors, streamlining processes, task automation and decision support. These complex AI models require more information to describe and reproduce, increasing the possibility that sensitive personal data can be inferred from such descriptions. TREs do not have mature processes and controls against these risks. This is a complex topic, and it is unreasonable to expect all TREs to be aware of all risks or that TRE researchers have addressed these risks in AI-specific training. GRAIMATTER has developed a draft set of usable recommendations for TREs to guard against the additional risks when disclosing trained AI models from TREs. The development of these recommendations has been funded by the GRAIMATTER UKRI DARE UK sprint research project. This version of our recommendations was published at the end of the project in September 2022. During the course of the project, we have identified many areas for future investigations to expand and test these recommendations in practice. Therefore, we expect that this document will evolve over time.
Enhanced Security and Privacy via Fragmented Federated Learning
Jul 13, 2022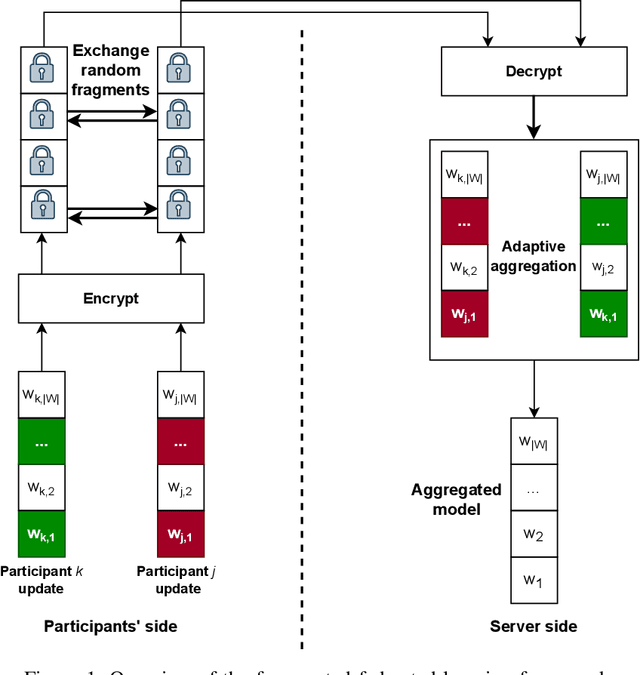



In federated learning (FL), a set of participants share updates computed on their local data with an aggregator server that combines updates into a global model. However, reconciling accuracy with privacy and security is a challenge to FL. On the one hand, good updates sent by honest participants may reveal their private local information, whereas poisoned updates sent by malicious participants may compromise the model's availability and/or integrity. On the other hand, enhancing privacy via update distortion damages accuracy, whereas doing so via update aggregation damages security because it does not allow the server to filter out individual poisoned updates. To tackle the accuracy-privacy-security conflict, we propose {\em fragmented federated learning} (FFL), in which participants randomly exchange and mix fragments of their updates before sending them to the server. To achieve privacy, we design a lightweight protocol that allows participants to privately exchange and mix encrypted fragments of their updates so that the server can neither obtain individual updates nor link them to their originators. To achieve security, we design a reputation-based defense tailored for FFL that builds trust in participants and their mixed updates based on the quality of the fragments they exchange and the mixed updates they send. Since the exchanged fragments' parameters keep their original coordinates and attackers can be neutralized, the server can correctly reconstruct a global model from the received mixed updates without accuracy loss. Experiments on four real data sets show that FFL can prevent semi-honest servers from mounting privacy attacks, can effectively counter poisoning attacks and can keep the accuracy of the global model.
Defending against the Label-flipping Attack in Federated Learning
Jul 05, 2022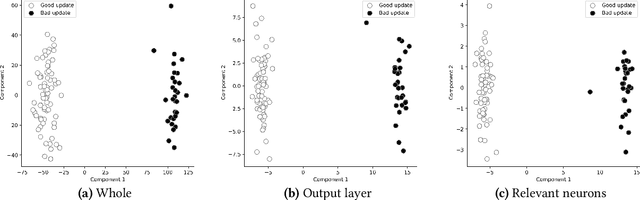

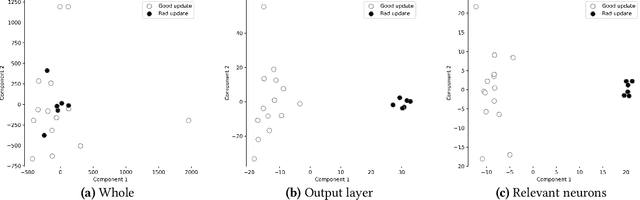

Federated learning (FL) provides autonomy and privacy by design to participating peers, who cooperatively build a machine learning (ML) model while keeping their private data in their devices. However, that same autonomy opens the door for malicious peers to poison the model by conducting either untargeted or targeted poisoning attacks. The label-flipping (LF) attack is a targeted poisoning attack where the attackers poison their training data by flipping the labels of some examples from one class (i.e., the source class) to another (i.e., the target class). Unfortunately, this attack is easy to perform and hard to detect and it negatively impacts on the performance of the global model. Existing defenses against LF are limited by assumptions on the distribution of the peers' data and/or do not perform well with high-dimensional models. In this paper, we deeply investigate the LF attack behavior and find that the contradicting objectives of attackers and honest peers on the source class examples are reflected in the parameter gradients corresponding to the neurons of the source and target classes in the output layer, making those gradients good discriminative features for the attack detection. Accordingly, we propose a novel defense that first dynamically extracts those gradients from the peers' local updates, and then clusters the extracted gradients, analyzes the resulting clusters and filters out potential bad updates before model aggregation. Extensive empirical analysis on three data sets shows the proposed defense's effectiveness against the LF attack regardless of the data distribution or model dimensionality. Also, the proposed defense outperforms several state-of-the-art defenses by offering lower test error, higher overall accuracy, higher source class accuracy, lower attack success rate, and higher stability of the source class accuracy.
A Critical Review on the Use of Differential Privacy in Machine Learning
Jun 09, 2022


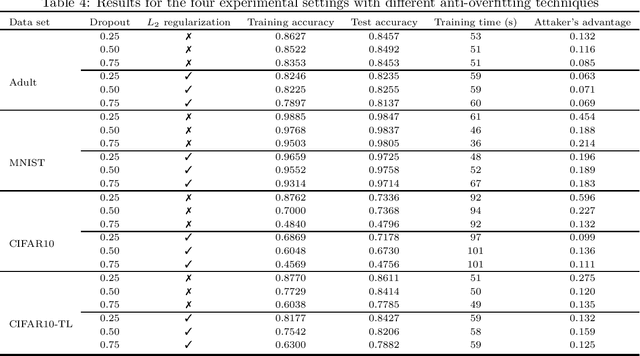
We review the use of differential privacy (DP) for privacy protection in machine learning (ML). We show that, driven by the aim of preserving the accuracy of the learned models, DP-based ML implementations are so loose that they do not offer the ex ante privacy guarantees of DP. Instead, what they deliver is basically noise addition similar to the traditional (and often criticized) statistical disclosure control approach. Due to the lack of formal privacy guarantees, the actual level of privacy offered must be experimentally assessed ex post, which is done very seldom. In this respect, we present empirical results showing that standard anti-overfitting techniques in ML can achieve a better utility/privacy/efficiency trade-off than DP.
Secure and Privacy-Preserving Federated Learning via Co-Utility
Aug 04, 2021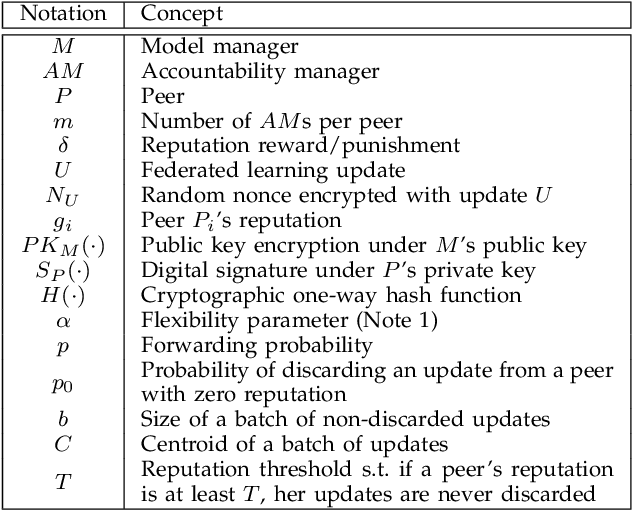
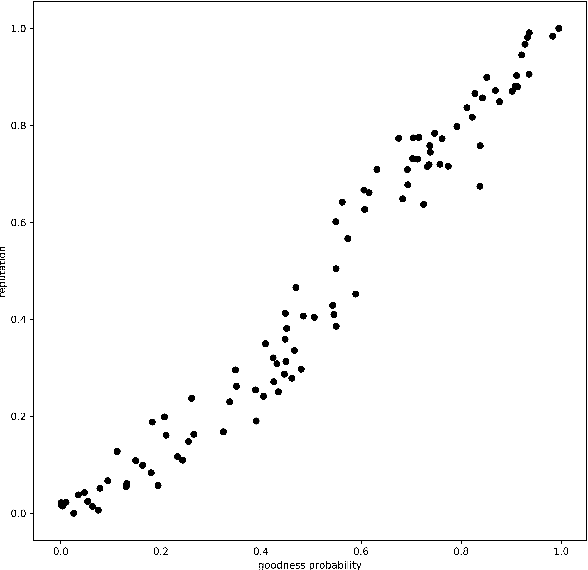
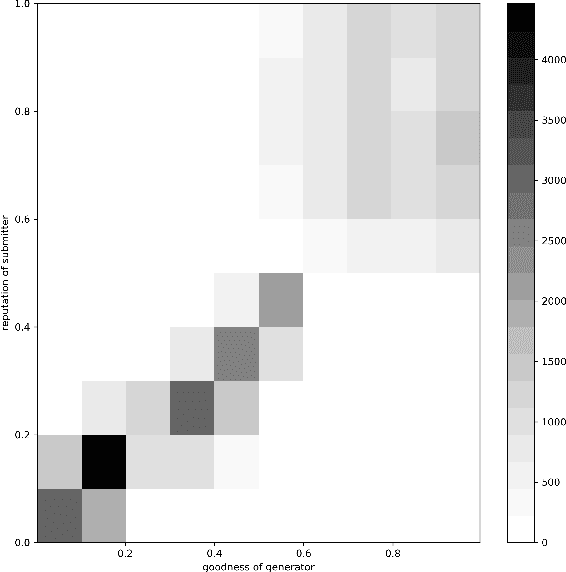

The decentralized nature of federated learning, that often leverages the power of edge devices, makes it vulnerable to attacks against privacy and security. The privacy risk for a peer is that the model update she computes on her private data may, when sent to the model manager, leak information on those private data. Even more obvious are security attacks, whereby one or several malicious peers return wrong model updates in order to disrupt the learning process and lead to a wrong model being learned. In this paper we build a federated learning framework that offers privacy to the participating peers as well as security against Byzantine and poisoning attacks. Our framework consists of several protocols that provide strong privacy to the participating peers via unlinkable anonymity and that are rationally sustainable based on the co-utility property. In other words, no rational party is interested in deviating from the proposed protocols. We leverage the notion of co-utility to build a decentralized co-utile reputation management system that provides incentives for parties to adhere to the protocols. Unlike privacy protection via differential privacy, our approach preserves the values of model updates and hence the accuracy of plain federated learning; unlike privacy protection via update aggregation, our approach preserves the ability to detect bad model updates while substantially reducing the computational overhead compared to methods based on homomorphic encryption.
Achieving Security and Privacy in Federated Learning Systems: Survey, Research Challenges and Future Directions
Dec 12, 2020

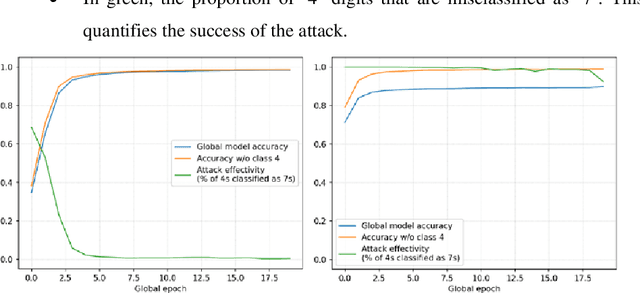
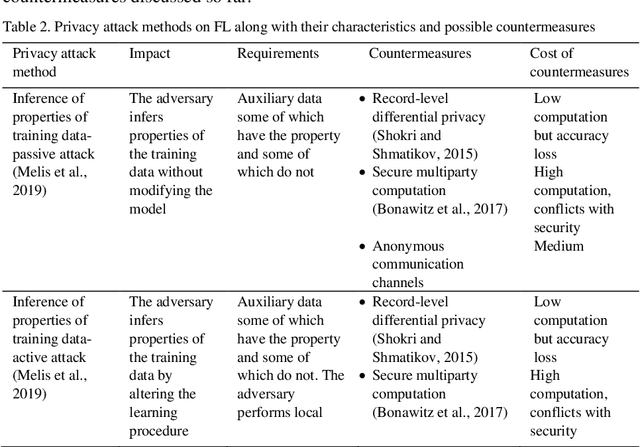
Federated learning (FL) allows a server to learn a machine learning (ML) model across multiple decentralized clients that privately store their own training data. In contrast with centralized ML approaches, FL saves computation to the server and does not require the clients to outsource their private data to the server. However, FL is not free of issues. On the one hand, the model updates sent by the clients at each training epoch might leak information on the clients' private data. On the other hand, the model learnt by the server may be subjected to attacks by malicious clients; these security attacks might poison the model or prevent it from converging. In this paper, we first examine security and privacy attacks to FL and critically survey solutions proposed in the literature to mitigate each attack. Afterwards, we discuss the difficulty of simultaneously achieving security and privacy protection. Finally, we sketch ways to tackle this open problem and attain both security and privacy.