 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIRPLAI: A Human-in-the-Loop Approach to Fair and Private Machine Learning
Nov 11, 2025As machine learning systems move from theory to practice, they are increasingly tasked with decisions that affect healthcare access, financial opportunities, hiring, and public services. In these contexts, accuracy is only one piece of the puzzle - models must also be fair to different groups, protect individual privacy, and remain accountable to stakeholders. Achieving all three is difficult: differential privacy can unintentionally worsen disparities, fairness interventions often rely on sensitive data that privacy restricts, and automated pipelines ignore that fairness is ultimately a human and contextual judgment. We introduce FAIRPLAI (Fair and Private Learning with Active Human Influence), a practical framework that integrates human oversight into the design and deployment of machine learning systems. FAIRPLAI works in three ways: (1) it constructs privacy-fairness frontiers that make trade-offs between accuracy, privacy guarantees, and group outcomes transparent; (2) it enables interactive stakeholder input, allowing decision-makers to select fairness criteria and operating points that reflect their domain needs; and (3) it embeds a differentially private auditing loop, giving humans the ability to review explanations and edge cases without compromising individual data security. Applied to benchmark datasets, FAIRPLAI consistently preserves strong privacy protections while reducing fairness disparities relative to automated baselines. More importantly, it provides a straightforward, interpretable process for practitioners to manage competing demands of accuracy, privacy, and fairness in socially impactful applications. By embedding human judgment where it matters most, FAIRPLAI offers a pathway to machine learning systems that are effective, responsible, and trustworthy in practice. GitHub: https://github.com/Li1Davey/Fairplai
DP2Unlearning: An Efficient and Guaranteed Unlearning Framework for LLMs
Apr 18, 2025



Large language models (LLMs) have recently revolutionized language processing tasks but have also brought ethical and legal issues. LLMs have a tendency to memorize potentially private or copyrighted information present in the training data, which might then be delivered to end users at inference time. When this happens, a naive solution is to retrain the model from scratch after excluding the undesired data. Although this guarantees that the target data have been forgotten, it is also prohibitively expensive for LLMs. Approximate unlearning offers a more efficient alternative, as it consists of ex post modifications of the trained model itself to prevent undesirable results, but it lacks forgetting guarantees because it relies solely on empirical evidence. In this work, we present DP2Unlearning, a novel LLM unlearning framework that offers formal forgetting guarantees at a significantly lower cost than retraining from scratch on the data to be retained. DP2Unlearning involves training LLMs on textual data protected using {\epsilon}-differential privacy (DP), which later enables efficient unlearning with the guarantees against disclosure associated with the chosen {\epsilon}. Our experiments demonstrate that DP2Unlearning achieves similar model performance post-unlearning, compared to an LLM retraining from scratch on retained data -- the gold standard exact unlearning -- but at approximately half the unlearning cost. In addition, with a reasonable computational cost, it outperforms approximate unlearning methods at both preserving the utility of the model post-unlearning and effectively forgetting the targeted information.
Entropy and type-token ratio in gigaword corpora
Nov 15, 2024Lexical diversity measures the vocabulary variation in texts. While its utility is evident for analyses in language change and applied linguistics, it is not yet clear how to operationalize this concept in a unique way. We here investigate entropy and text-token ratio, two widely employed metrics for lexical diversities, in six massive linguistic datasets in English, Spanish, and Turkish, consisting of books, news articles, and tweets. These gigaword corpora correspond to languages with distinct morphological features and differ in registers and genres, thus constituting a diverse testbed for a quantitative approach to lexical diversity. Strikingly, we find a functional relation between entropy and text-token ratio that holds across the corpora under consideration. Further, in the limit of large vocabularies we find an analytical expression that sheds light on the origin of this relation and its connection with both Zipf and Heaps laws. Our results then contribute to the theoretical understanding of text structure and offer practical implications for fields like natural language processing.
Computational lexical analysis of Flamenco genres
May 09, 2024Flamenco, recognized by UNESCO as part of the Intangible Cultural Heritage of Humanity, is a profound expression of cultural identity rooted in Andalusia, Spain. However, there is a lack of quantitative studies that help identify characteristic patterns in this long-lived music tradition. In this work, we present a computational analysis of Flamenco lyrics, employing natural language processing and machine learning to categorize over 2000 lyrics into their respective Flamenco genres, termed as $\textit{palos}$. Using a Multinomial Naive Bayes classifier, we find that lexical variation across styles enables to accurately identify distinct $\textit{palos}$. More importantly, from an automatic method of word usage, we obtain the semantic fields that characterize each style. Further, applying a metric that quantifies the inter-genre distance we perform a network analysis that sheds light on the relationship between Flamenco styles. Remarkably, our results suggest historical connections and $\textit{palo}$ evolutions. Overall, our work illuminates the intricate relationships and cultural significance embedded within Flamenco lyrics, complementing previous qualitative discussions with quantitative analyses and sparking new discussions on the origin and development of traditional music genres.
Universality and diversity in word patterns
Aug 23, 2022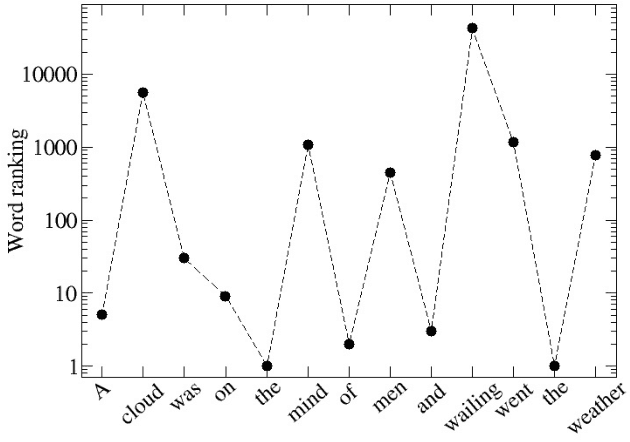
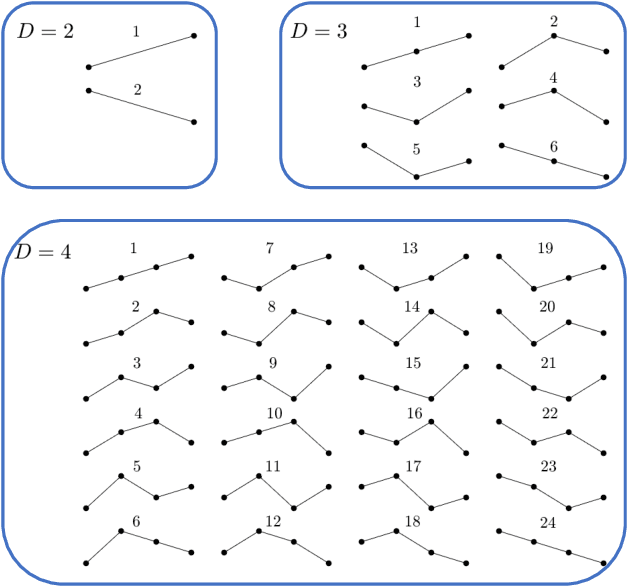
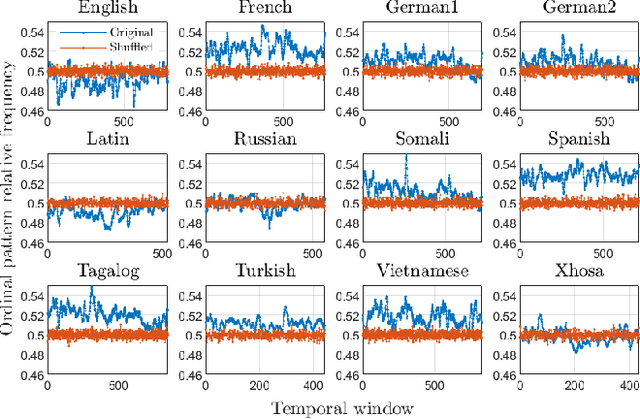
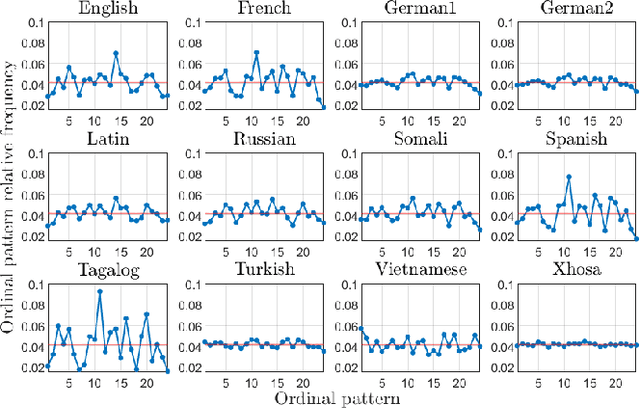
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.
American cultural regions mapped through the lexical analysis of social media
Aug 16, 2022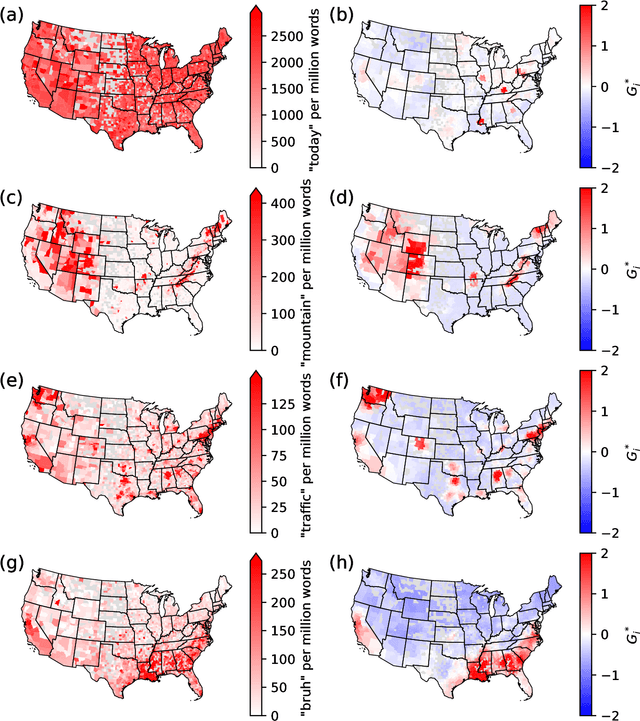
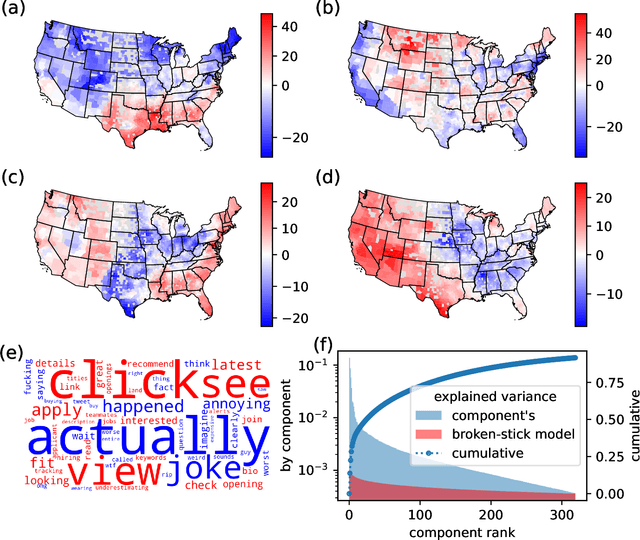
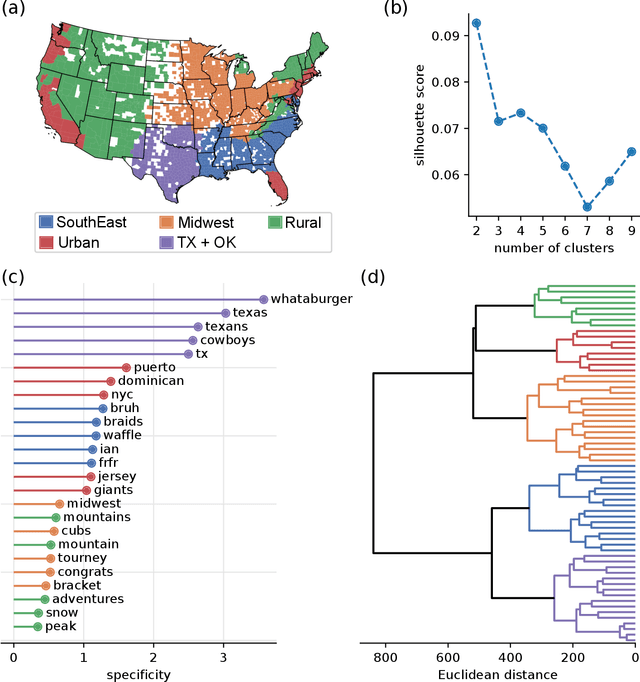
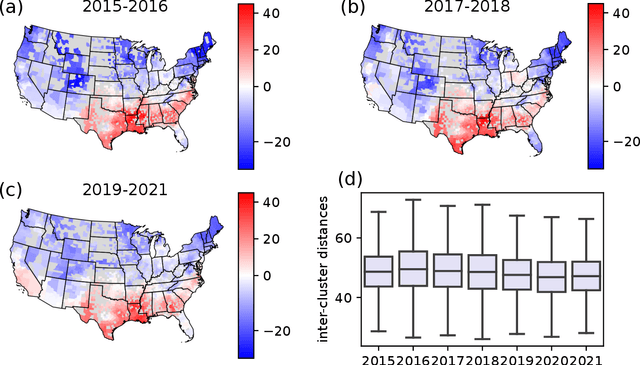
Cultural areas represent a useful concept that cross-fertilizes diverse fields in social sciences. Knowledge of how humans organize and relate their ideas and behavior within a society helps to understand their actions and attitudes towards different issues. However, the selection of common traits that shape a cultural area is somewhat arbitrary. What is needed is a method that can leverage the massive amounts of data coming online, especially through social media, to identify cultural regions without ad-hoc assumptions, biases or prejudices. In this work, we take a crucial step towards this direction by introducing a method to infer cultural regions based on the automatic analysis of large datasets from microblogging posts. Our approach is based on the principle that cultural affiliation can be inferred from the topics that people discuss among themselves. Specifically, we measure regional variations in written discourse generated in American social media. From the frequency distributions of content words in geotagged Tweets, we find the words' usage regional hotspots, and from there we derive principal components of regional variation. Through a hierarchical clustering of the data in this lower-dimensional space, our method yields clear cultural areas and the topics of discussion that define them. We obtain a manifest North-South separation, which is primarily influenced by the African American culture, and further contiguous (East-West) and non-contiguous (urban-rural) divisions that provide a comprehensive picture of today's cultural areas in the US.
Enhanced Security and Privacy via Fragmented Federated Learning
Jul 13, 2022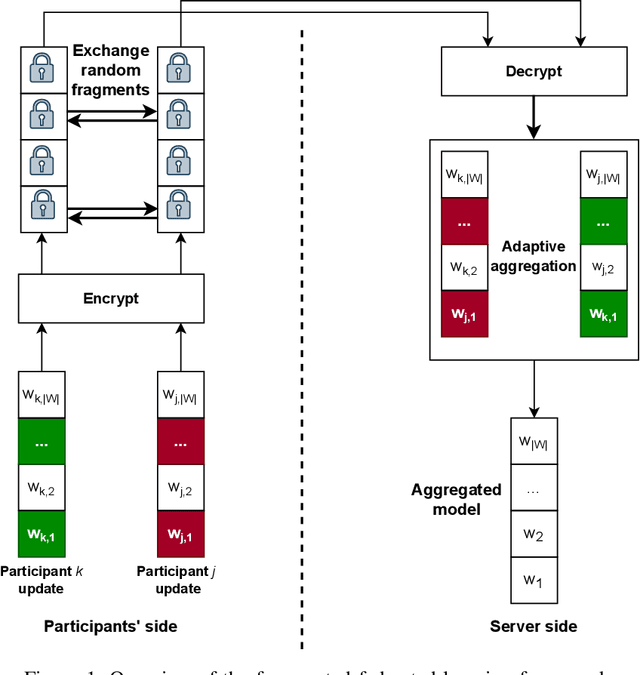



In federated learning (FL), a set of participants share updates computed on their local data with an aggregator server that combines updates into a global model. However, reconciling accuracy with privacy and security is a challenge to FL. On the one hand, good updates sent by honest participants may reveal their private local information, whereas poisoned updates sent by malicious participants may compromise the model's availability and/or integrity. On the other hand, enhancing privacy via update distortion damages accuracy, whereas doing so via update aggregation damages security because it does not allow the server to filter out individual poisoned updates. To tackle the accuracy-privacy-security conflict, we propose {\em fragmented federated learning} (FFL), in which participants randomly exchange and mix fragments of their updates before sending them to the server. To achieve privacy, we design a lightweight protocol that allows participants to privately exchange and mix encrypted fragments of their updates so that the server can neither obtain individual updates nor link them to their originators. To achieve security, we design a reputation-based defense tailored for FFL that builds trust in participants and their mixed updates based on the quality of the fragments they exchange and the mixed updates they send. Since the exchanged fragments' parameters keep their original coordinates and attackers can be neutralized, the server can correctly reconstruct a global model from the received mixed updates without accuracy loss. Experiments on four real data sets show that FFL can prevent semi-honest servers from mounting privacy attacks, can effectively counter poisoning attacks and can keep the accuracy of the global model.
A Critical Review on the Use of Differential Privacy in Machine Learning
Jun 09, 2022


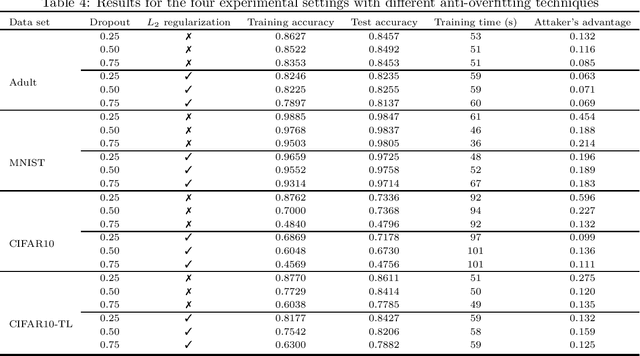
We review the use of differential privacy (DP) for privacy protection in machine learning (ML). We show that, driven by the aim of preserving the accuracy of the learned models, DP-based ML implementations are so loose that they do not offer the ex ante privacy guarantees of DP. Instead, what they deliver is basically noise addition similar to the traditional (and often criticized) statistical disclosure control approach. Due to the lack of formal privacy guarantees, the actual level of privacy offered must be experimentally assessed ex post, which is done very seldom. In this respect, we present empirical results showing that standard anti-overfitting techniques in ML can achieve a better utility/privacy/efficiency trade-off than DP.
Capturing the diversity of multilingual societies
May 12, 2021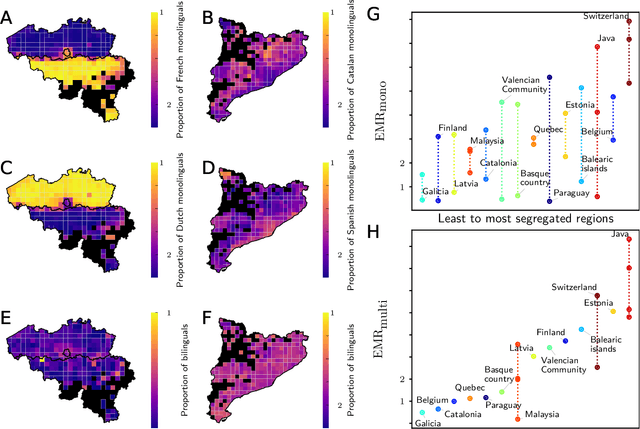
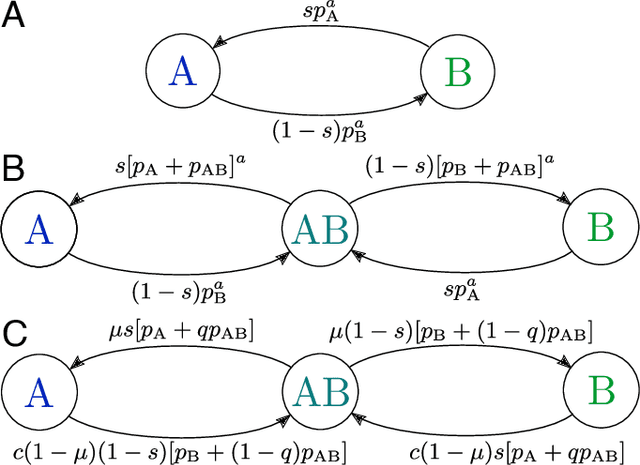
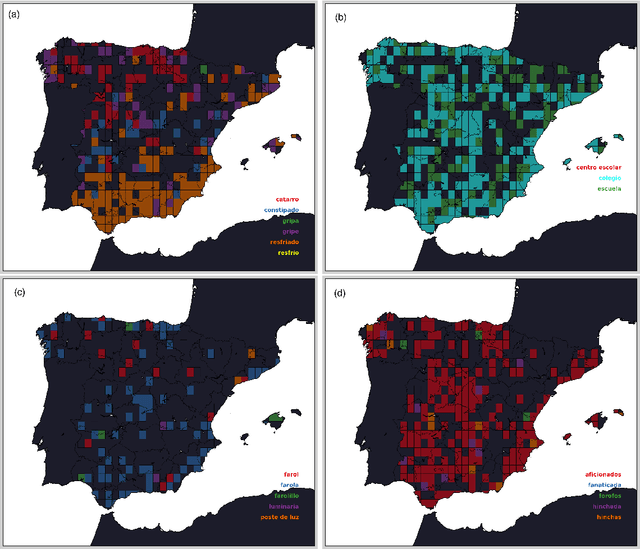
Cultural diversity encoded within languages of the world is at risk, as many languages have become endangered in the last decades in a context of growing globalization. To preserve this diversity, it is first necessary to understand what drives language extinction, and which mechanisms might enable coexistence. Here, we consider the processes at work in language shift through a conjunction of theoretical and data-driven perspectives. A large-scale empirical study of spatial patterns of languages in multilingual societies using Twitter and census data yields a wide diversity. It ranges from an almost complete mixing of language speakers, including multilinguals, to segregation with a neat separation of the linguistic domains and with multilinguals mainly at their boundaries. To understand how these different states can emerge and, especially, become stable, we propose a model in which coexistence of languages may be reached when learning the other language is facilitated and when bilinguals favor the use of the endangered language. Simulations carried out in a metapopulation framework highlight the importance of spatial interactions arising from people mobility to explain the stability of a mixed state or the presence of a boundary between two linguistic regions. Changes in the parameters regulating the relation between the languages can destabilize a system, which undergoes global transitions. According to our model, the evolution of the system once it undergoes a transition is highly history-dependent. It is easy to change the status quo but going back to a previous state may not be simple or even possible.
Dialectometric analysis of language variation in Twitter
Feb 22, 2017
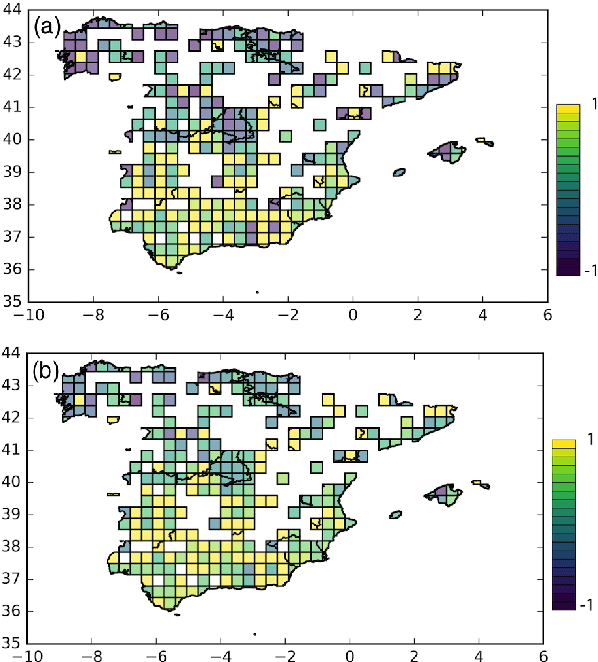
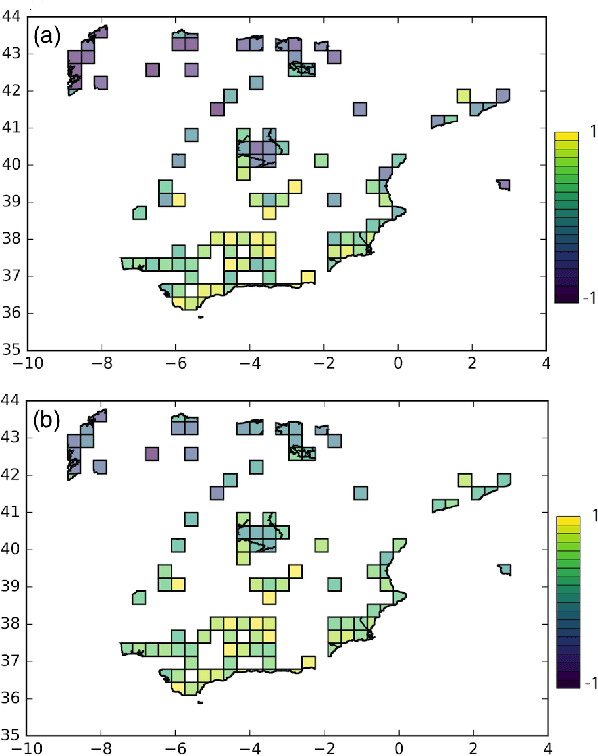
In the last few years, microblogging platforms such as Twitter have given rise to a deluge of textual data that can be used for the analysis of informal communication between millions of individuals. In this work, we propose an information-theoretic approach to geographic language variation using a corpus based on Twitter. We test our models with tens of concepts and their associated keywords detected in Spanish tweets geolocated in Spain. We employ dialectometric measures (cosine similarity and Jensen-Shannon divergence) to quantify the linguistic distance on the lexical level between cells created in a uniform grid over the map. This can be done for a single concept or in the general case taking into account an average of the considered variants. The latter permits an analysis of the dialects that naturally emerge from the data. Interestingly, our results reveal the existence of two dialect macrovarieties. The first group includes a region-specific speech spoken in small towns and rural areas whereas the second cluster encompasses cities that tend to use a more uniform variety. Since the results obtained with the two different metrics qualitatively agree, our work suggests that social media corpora can be efficiently used for dialectometric analyses.
* 10 pages, 7 figures, 1 table. Accepted to VarDial 2017