Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Critical Review on the Use of Differential Privacy in Machine Learning
Paper and Code



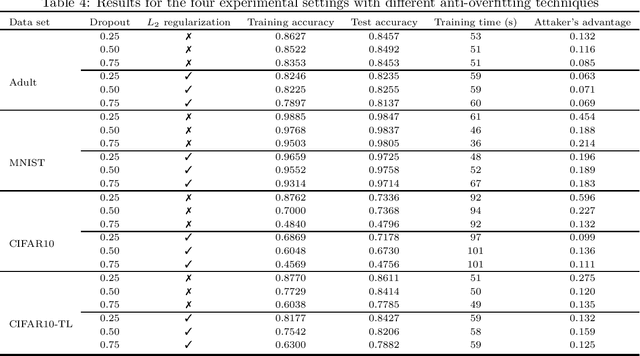
We review the use of differential privacy (DP) for privacy protection in machine learning (ML). We show that, driven by the aim of preserving the accuracy of the learned models, DP-based ML implementations are so loose that they do not offer the ex ante privacy guarantees of DP. Instead, what they deliver is basically noise addition similar to the traditional (and often criticized) statistical disclosure control approach. Due to the lack of formal privacy guarantees, the actual level of privacy offered must be experimentally assessed ex post, which is done very seldom. In this respect, we present empirical results showing that standard anti-overfitting techniques in ML can achieve a better utility/privacy/efficiency trade-off than DP.
View paper on