 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Consensus Privacy Metrics Framework for Synthetic Data
Mar 06, 2025Synthetic data generation is one approach for sharing individual-level data. However, to meet legislative requirements, it is necessary to demonstrate that the individuals' privacy is adequately protected. There is no consolidated standard for measuring privacy in synthetic data. Through an expert panel and consensus process, we developed a framework for evaluating privacy in synthetic data. Our findings indicate that current similarity metrics fail to measure identity disclosure, and their use is discouraged. For differentially private synthetic data, a privacy budget other than close to zero was not considered interpretable. There was consensus on the importance of membership and attribute disclosure, both of which involve inferring personal information about an individual without necessarily revealing their identity. The resultant framework provides precise recommendations for metrics that address these types of disclosures effectively. Our findings further present specific opportunities for future research that can help with widespread adoption of synthetic data.
An Examination of the Alleged Privacy Threats of Confidence-Ranked Reconstruction of Census Microdata
Nov 06, 2023The alleged threat of reconstruction attacks has led the U.S. Census Bureau (USCB) to replace in the Decennial Census 2020 the traditional statistical disclosure limitation based on rank swapping with one based on differential privacy (DP). This has resulted in substantial accuracy loss of the released statistics. Worse yet, it has been shown that the reconstruction attacks used as an argument to move to DP are very far from allowing unequivocal reidentification of the respondents, because in general there are a lot of reconstructions compatible with the released statistics. In a very recent paper, a new reconstruction attack has been proposed, whose goal is to indicate the confidence that a reconstructed record was in the original respondent data. The alleged risk of serious disclosure entailed by such confidence-ranked reconstruction has renewed the interest of the USCB to use DP-based solutions. To forestall the potential accuracy loss in future data releases resulting from adoption of these solutions, we show in this paper that the proposed confidence-ranked reconstruction does not threaten privacy. Specifically, we report empirical results showing that the proposed ranking cannot guide reidentification or attribute disclosure attacks, and hence it fails to warrant the USCB's move towards DP. Further, we also demonstrate that, due to the way the Census data are compiled, processed and released, it is not possible to reconstruct original and complete records through any methodology, and the confidence-ranked reconstruction not only is completely ineffective at accurately reconstructing Census records but is trivially outperformed by an adequate interpretation of the released aggregate statistics.
A Critical Review on the Use of Differential Privacy in Machine Learning
Jun 09, 2022


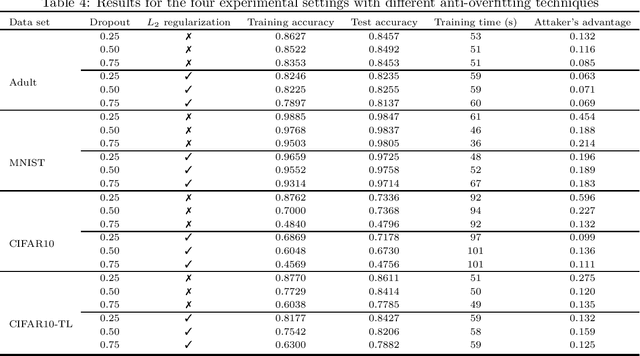
We review the use of differential privacy (DP) for privacy protection in machine learning (ML). We show that, driven by the aim of preserving the accuracy of the learned models, DP-based ML implementations are so loose that they do not offer the ex ante privacy guarantees of DP. Instead, what they deliver is basically noise addition similar to the traditional (and often criticized) statistical disclosure control approach. Due to the lack of formal privacy guarantees, the actual level of privacy offered must be experimentally assessed ex post, which is done very seldom. In this respect, we present empirical results showing that standard anti-overfitting techniques in ML can achieve a better utility/privacy/efficiency trade-off than DP.