 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sociolinguistic Foundations of Language Modeling
Jul 12, 2024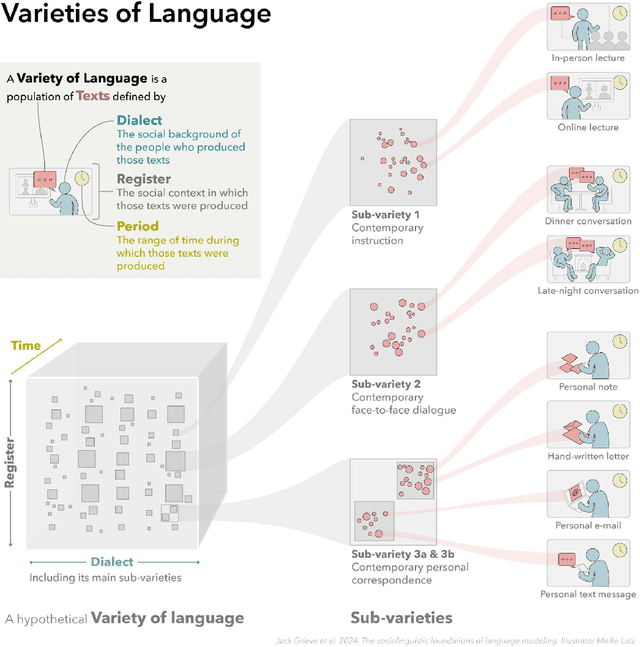
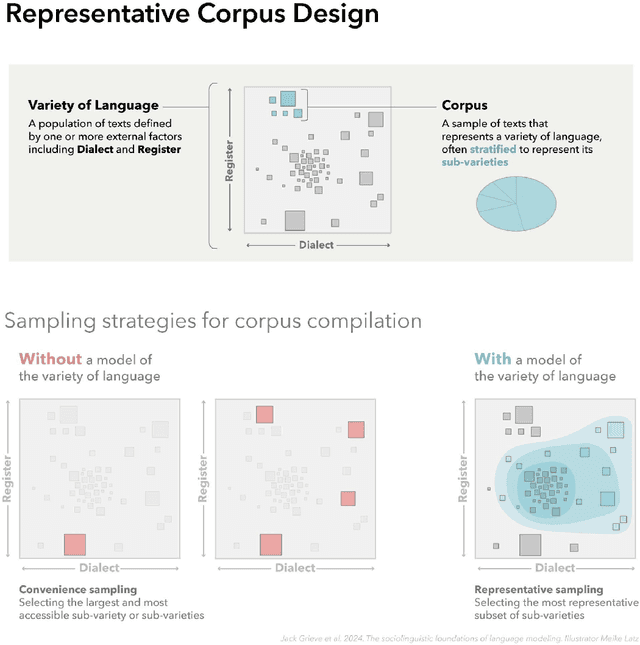
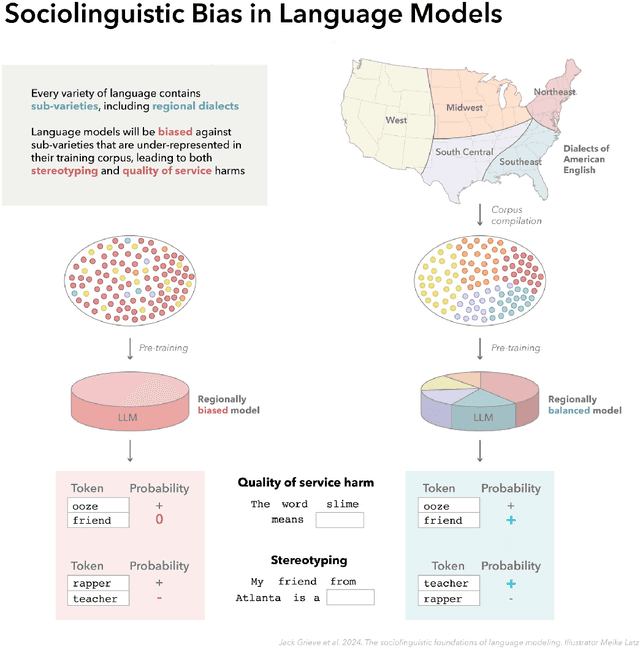
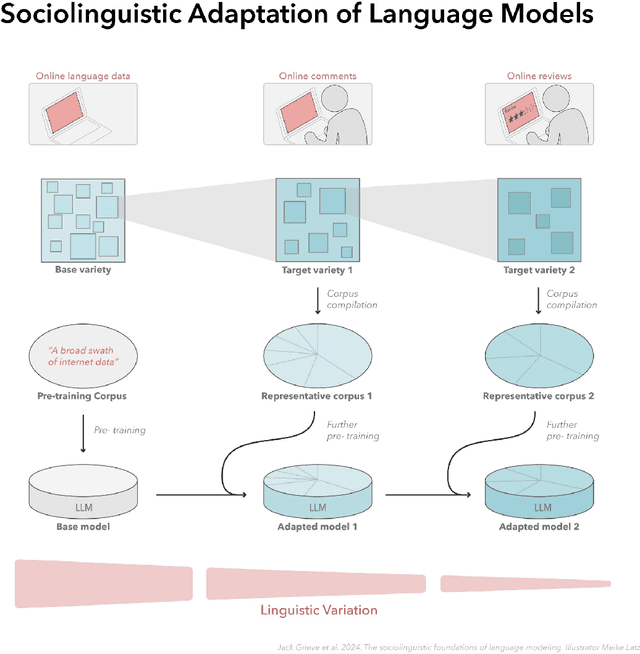
In this paper, we introduce a sociolinguistic perspective on language modeling. We claim that large language models are inherently models of varieties of language, and we consider how this insight can inform the development and deployment of large language models. We begin by presenting a technical definition of the concept of a variety of language as developed in sociolinguistics. We then discuss how this perspective can help address five basic challenges in language modeling: social bias, domain adaptation, alignment, language change, and scale. Ultimately, we argue that it is crucial to carefully define and compile training corpora that accurately represent the specific varieties of language being modeled to maximize the performance and societal value of large language models.
ALMs: Authorial Language Models for Authorship Attribution
Jan 22, 2024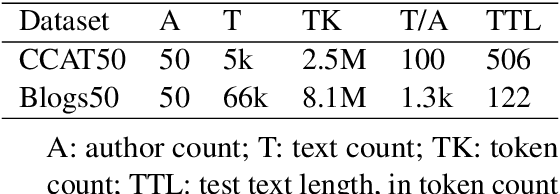

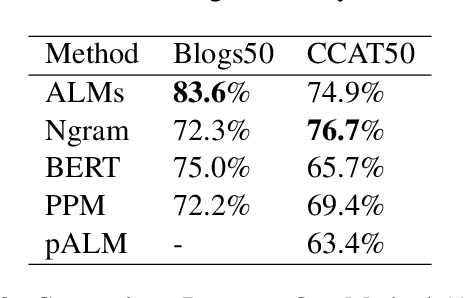
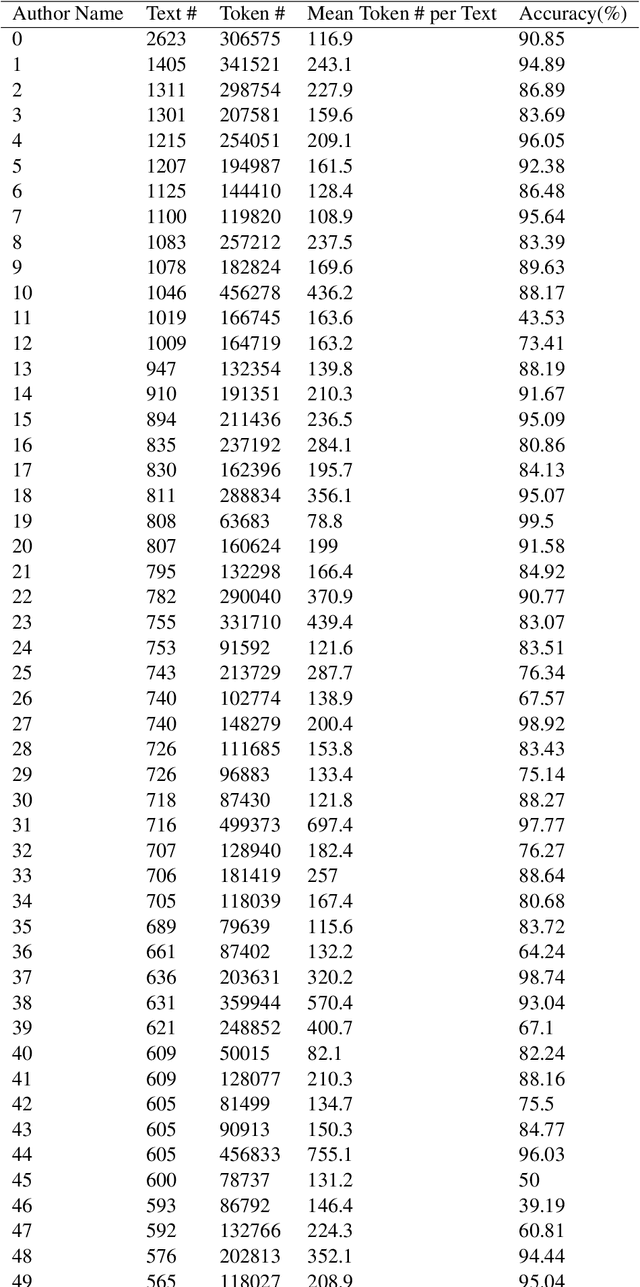
In this paper, we introduce an authorship attribution method called Authorial Language Models (ALMs) that involves identifying the most likely author of a questioned document based on the perplexity of the questioned document calculated for a set of causal language models fine-tuned on the writings of a set of candidate author. We benchmarked ALMs against state-of-art-systems using the CCAT50 dataset and the Blogs50 datasets. We find that ALMs achieves a macro-average accuracy score of 83.6% on Blogs50, outperforming all other methods, and 74.9% on CCAT50, matching the performance of the best method. To assess the performance of ALMs on shorter texts, we also conducted text ablation testing. We found that to reach a macro-average accuracy of 70%, ALMs needs 40 tokens on Blogs50 and 400 tokens on CCAT50, while to reach 60% ALMs requires 20 tokens on Blogs50 and 70 tokens on CCAT50.
American cultural regions mapped through the lexical analysis of social media
Aug 16, 2022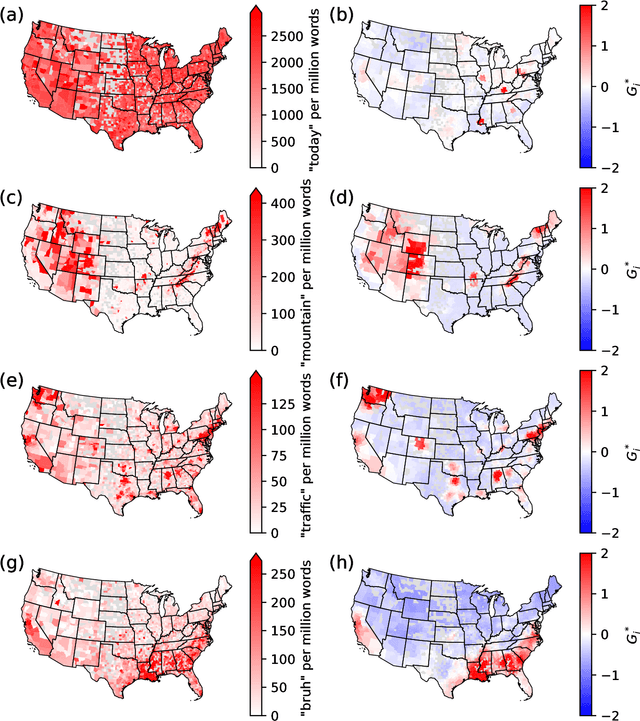
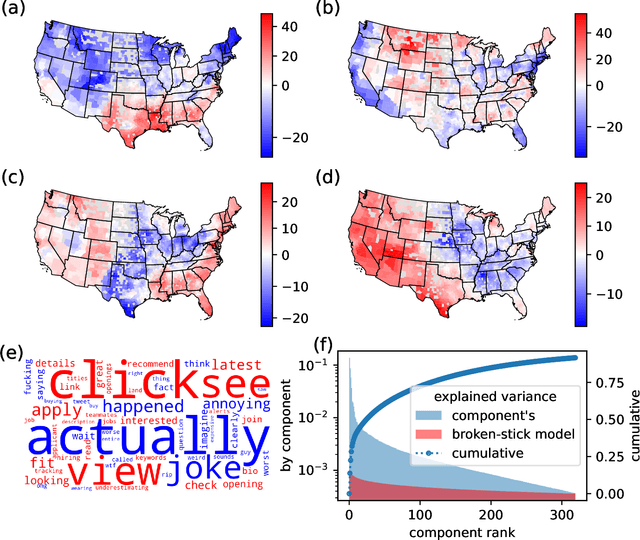
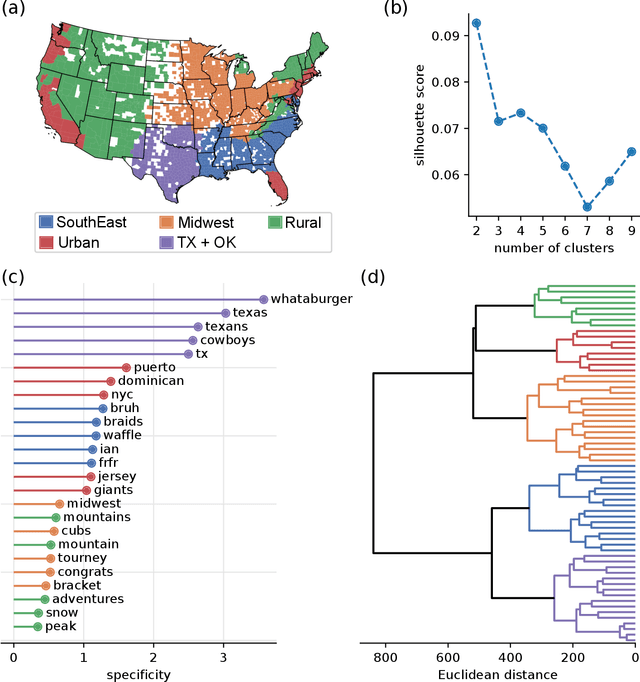
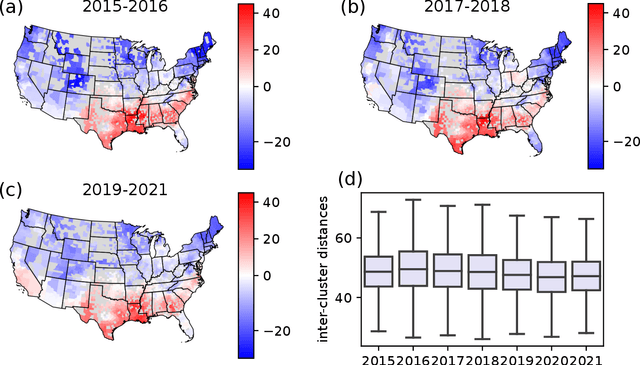
Cultural areas represent a useful concept that cross-fertilizes diverse fields in social sciences. Knowledge of how humans organize and relate their ideas and behavior within a society helps to understand their actions and attitudes towards different issues. However, the selection of common traits that shape a cultural area is somewhat arbitrary. What is needed is a method that can leverage the massive amounts of data coming online, especially through social media, to identify cultural regions without ad-hoc assumptions, biases or prejudices. In this work, we take a crucial step towards this direction by introducing a method to infer cultural regions based on the automatic analysis of large datasets from microblogging posts. Our approach is based on the principle that cultural affiliation can be inferred from the topics that people discuss among themselves. Specifically, we measure regional variations in written discourse generated in American social media. From the frequency distributions of content words in geotagged Tweets, we find the words' usage regional hotspots, and from there we derive principal components of regional variation. Through a hierarchical clustering of the data in this lower-dimensional space, our method yields clear cultural areas and the topics of discussion that define them. We obtain a manifest North-South separation, which is primarily influenced by the African American culture, and further contiguous (East-West) and non-contiguous (urban-rural) divisions that provide a comprehensive picture of today's cultural areas in the US.