 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sociolinguistic Foundations of Language Modeling
Paper and Code
Jul 12, 2024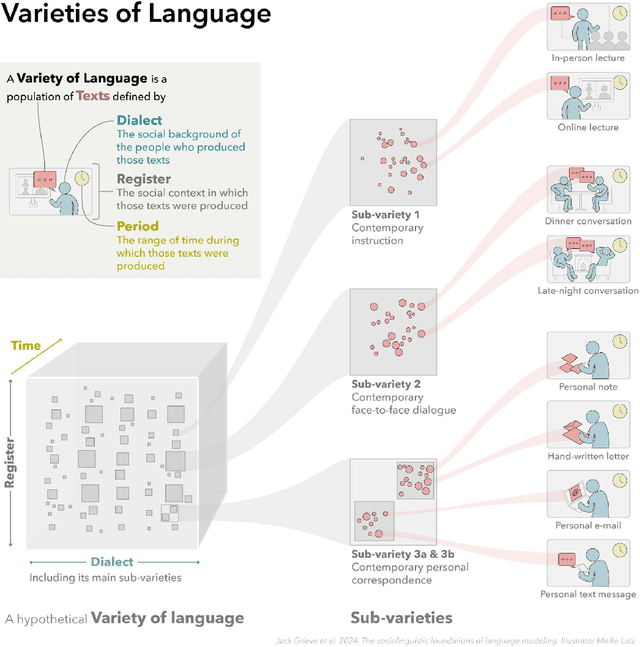
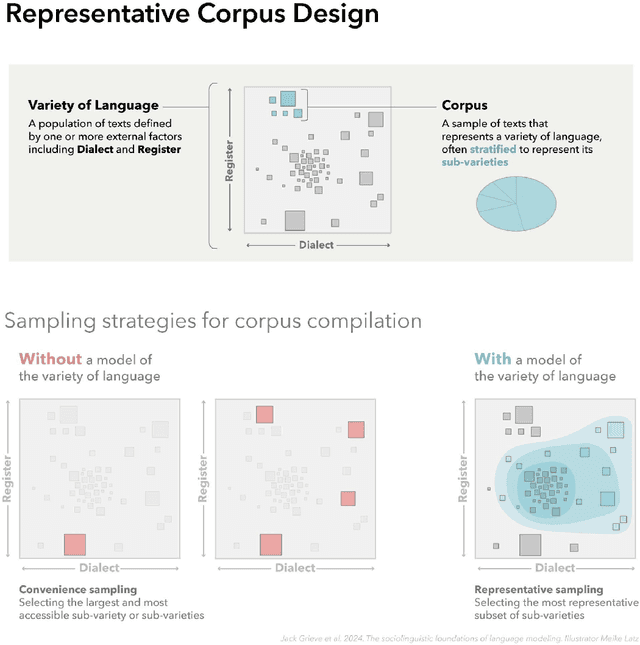
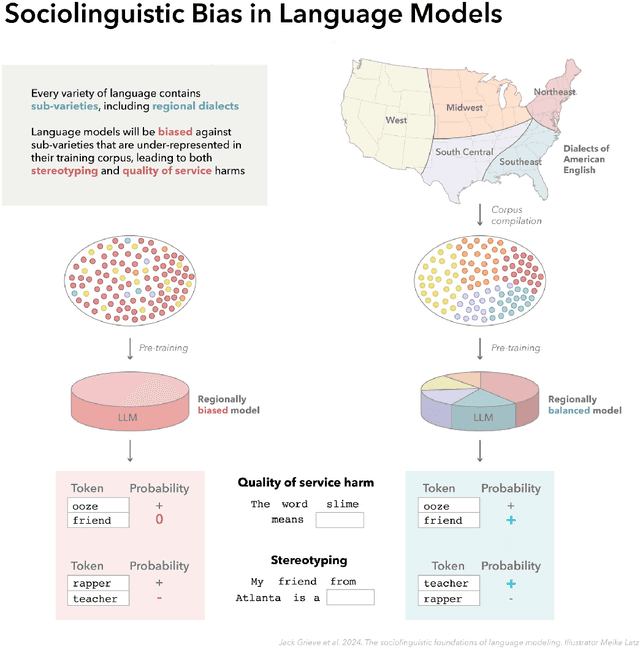
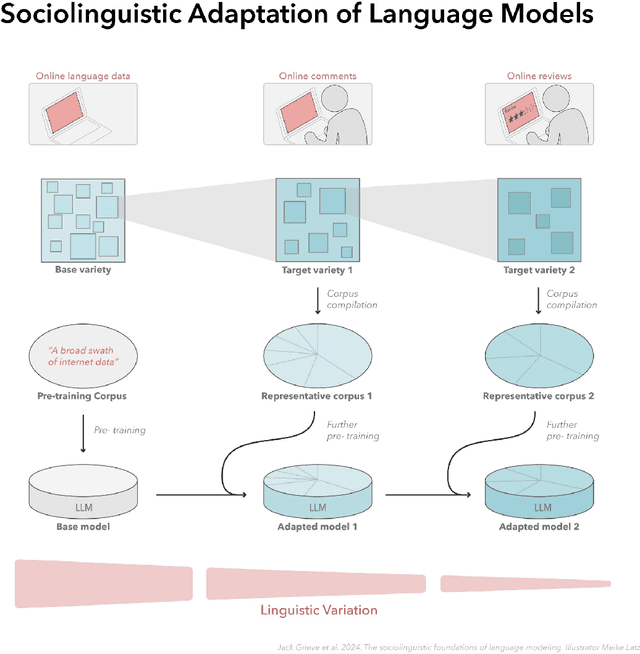
In this paper, we introduce a sociolinguistic perspective on language modeling. We claim that large language models are inherently models of varieties of language, and we consider how this insight can inform the development and deployment of large language models. We begin by presenting a technical definition of the concept of a variety of language as developed in sociolinguistics. We then discuss how this perspective can help address five basic challenges in language modeling: social bias, domain adaptation, alignment, language change, and scale. Ultimately, we argue that it is crucial to carefully define and compile training corpora that accurately represent the specific varieties of language being modeled to maximize the performance and societal value of large language models.