 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sociolinguistic Foundations of Language Modeling
Jul 12, 2024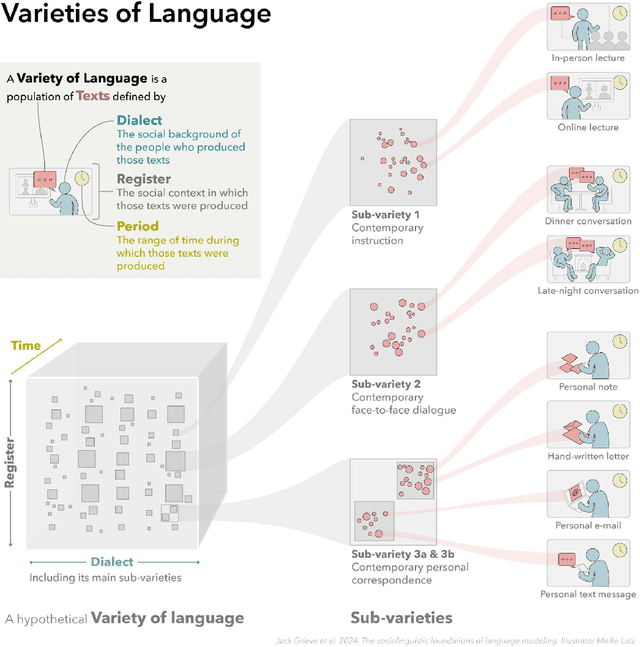
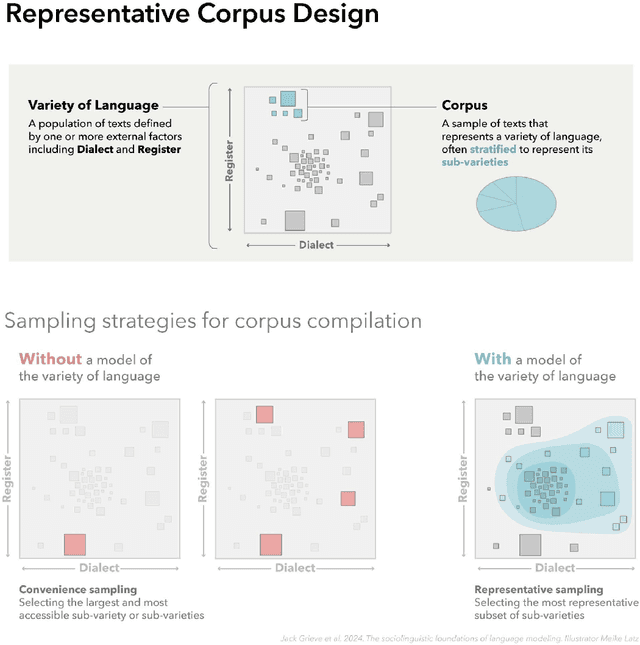
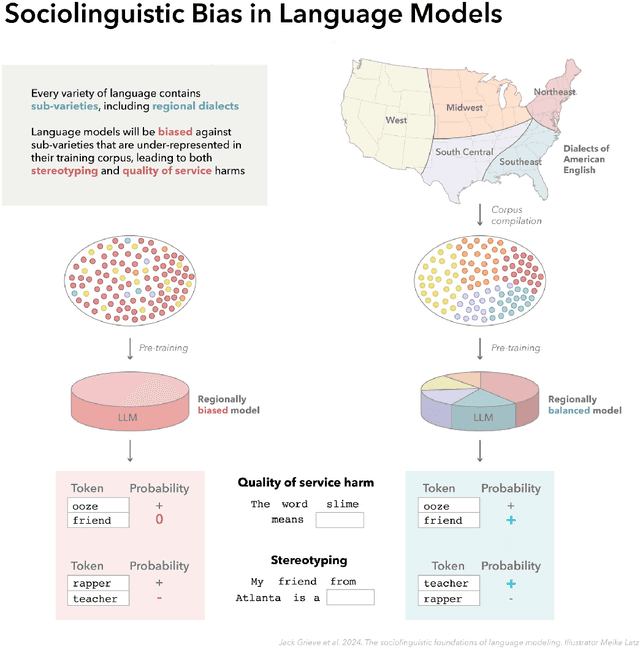
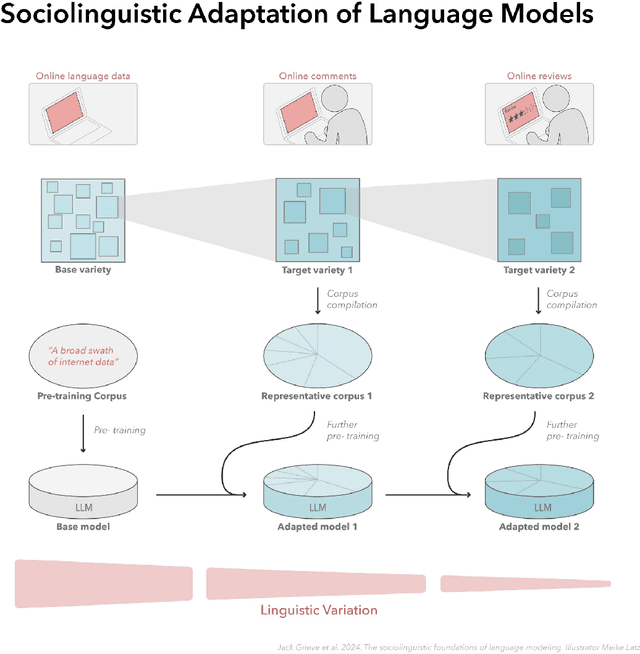
In this paper, we introduce a sociolinguistic perspective on language modeling. We claim that large language models are inherently models of varieties of language, and we consider how this insight can inform the development and deployment of large language models. We begin by presenting a technical definition of the concept of a variety of language as developed in sociolinguistics. We then discuss how this perspective can help address five basic challenges in language modeling: social bias, domain adaptation, alignment, language change, and scale. Ultimately, we argue that it is crucial to carefully define and compile training corpora that accurately represent the specific varieties of language being modeled to maximize the performance and societal value of large language models.
Explainability of Machine Learning Approaches in Forensic Linguistics: A Case Study in Geolinguistic Authorship Profiling
Apr 29, 2024Forensic authorship profiling uses linguistic markers to infer characteristics about an author of a text. This task is paralleled in dialect classification, where a prediction is made about the linguistic variety of a text based on the text itself. While there have been significant advances in the last years in variety classification (Jauhiainen et al., 2019) and state-of-the-art approaches reach accuracies of up to 100% depending on the similarity of varieties and the scope of prediction (e.g., Milne et al., 2012; Blodgett et al., 2017), forensic linguistics rarely relies on these approaches due to their lack of transparency (see Nini, 2023), amongst other reasons. In this paper we therefore explore explainability of machine learning approaches considering the forensic context. We focus on variety classification as a means of geolinguistic profiling of unknown texts. For this we work with an approach proposed by Xie et al. (2024) to extract the lexical items most relevant to the variety classifications. We find that the extracted lexical features are indeed representative of their respective varieties and note that the trained models also rely on place names for classifications.