 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALMs: Authorial Language Models for Authorship Attribution
Paper and Code
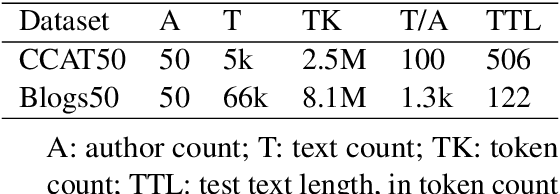

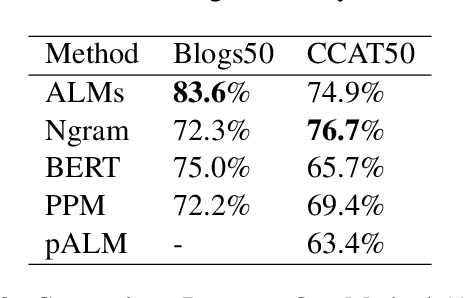
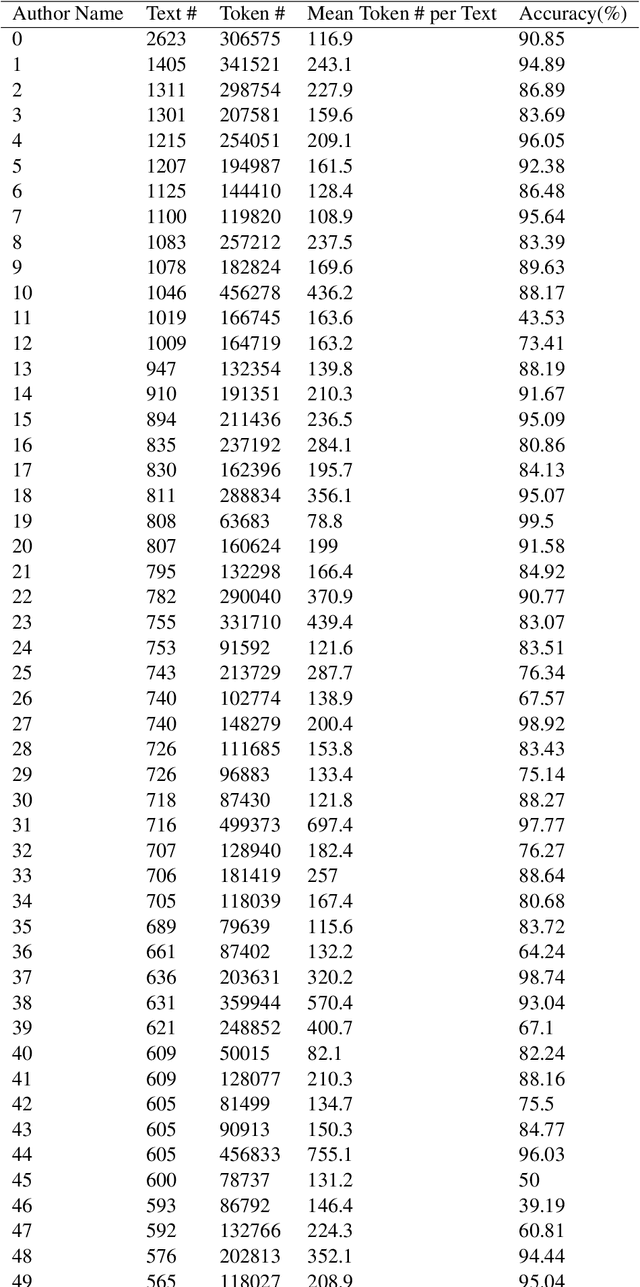
In this paper, we introduce an authorship attribution method called Authorial Language Models (ALMs) that involves identifying the most likely author of a questioned document based on the perplexity of the questioned document calculated for a set of causal language models fine-tuned on the writings of a set of candidate author. We benchmarked ALMs against state-of-art-systems using the CCAT50 dataset and the Blogs50 datasets. We find that ALMs achieves a macro-average accuracy score of 83.6% on Blogs50, outperforming all other methods, and 74.9% on CCAT50, matching the performance of the best method. To assess the performance of ALMs on shorter texts, we also conducted text ablation testing. We found that to reach a macro-average accuracy of 70%, ALMs needs 40 tokens on Blogs50 and 400 tokens on CCAT50, while to reach 60% ALMs requires 20 tokens on Blogs50 and 70 tokens on CCAT50.