 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality and diversity in word patterns
Paper and Code
Aug 23, 2022
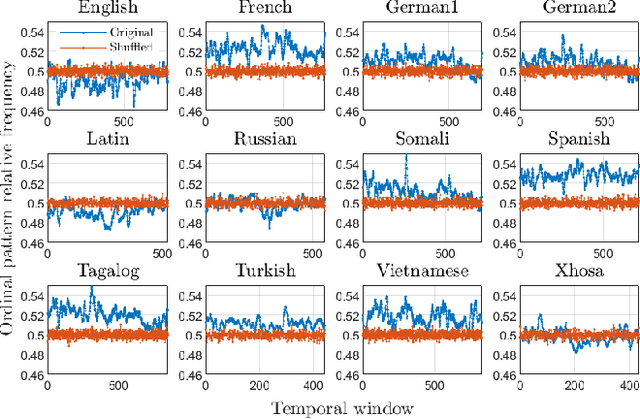
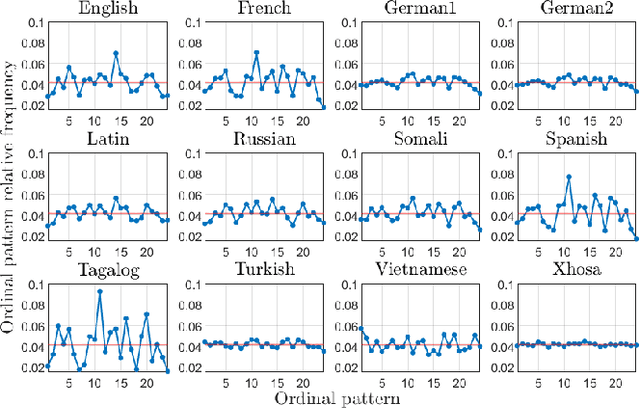
Words are fundamental linguistic units that connect thoughts and things through meaning. However, words do not appear independently in a text sequence. The existence of syntactic rules induce correlations among neighboring words. Further, words are not evenly distributed but approximately follow a power law since terms with a pure semantic content appear much less often than terms that specify grammar relations. Using an ordinal pattern approach, we present an analysis of lexical statistical connections for eleven major languages. We find that the diverse manners that languages utilize to express word relations give rise to unique pattern distributions. Remarkably, we find that these relations can be modeled with a Markov model of order 2 and that this result is universally valid for all the studied languages. Furthermore, fluctuations of the pattern distributions can allow us to determine the historical period when the text was written and its author. Taken together, these results emphasize the relevance of time series analysis and information-theoretic methods for the understanding of statistical correlations in natural languages.