 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHolistically-Nested Structure-Aware Graph Neural Network for Road Extraction
Jul 02, 2024Convolutional neural networks (CNN) have made significant advances in detecting roads from satellite images. However, existing CNN approaches are generally repurposed semantic segmentation architectures and suffer from the poor delineation of long and curved regions. Lack of overall road topology and structure information further deteriorates their performance on challenging remote sensing images. This paper presents a novel multi-task graph neural network (GNN) which simultaneously detects both road regions and road borders; the inter-play between these two tasks unlocks superior performance from two perspectives: (1) the hierarchically detected road borders enable the network to capture and encode holistic road structure to enhance road connectivity (2) identifying the intrinsic correlation of semantic landcover regions mitigates the difficulty in recognizing roads cluttered by regions with similar appearance. Experiments on challenging dataset demonstrate that the proposed architecture can improve the road border delineation and road extraction accuracy compared with the existing methods.
Digital Forgetting in Large Language Models: A Survey of Unlearning Methods
Apr 02, 2024The objective of digital forgetting is, given a model with undesirable knowledge or behavior, obtain a new model where the detected issues are no longer present. The motivations for forgetting include privacy protection, copyright protection, elimination of biases and discrimination, and prevention of harmful content generation. Effective digital forgetting has to be effective (meaning how well the new model has forgotten the undesired knowledge/behavior), retain the performance of the original model on the desirable tasks, and be scalable (in particular forgetting has to be more efficient than retraining from scratch on just the tasks/data to be retained). This survey focuses on forgetting in large language models (LLMs). We first provide background on LLMs, including their components, the types of LLMs, and their usual training pipeline. Second, we describe the motivations, types, and desired properties of digital forgetting. Third, we introduce the approaches to digital forgetting in LLMs, among which unlearning methodologies stand out as the state of the art. Fourth, we provide a detailed taxonomy of machine unlearning methods for LLMs, and we survey and compare current approaches. Fifth, we detail datasets, models and metrics used for the evaluation of forgetting, retaining and runtime. Sixth, we discuss challenges in the area. Finally, we provide some concluding remarks.
Achieving Security and Privacy in Federated Learning Systems: Survey, Research Challenges and Future Directions
Dec 12, 2020

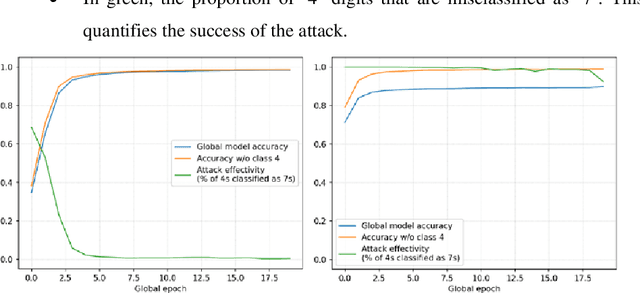
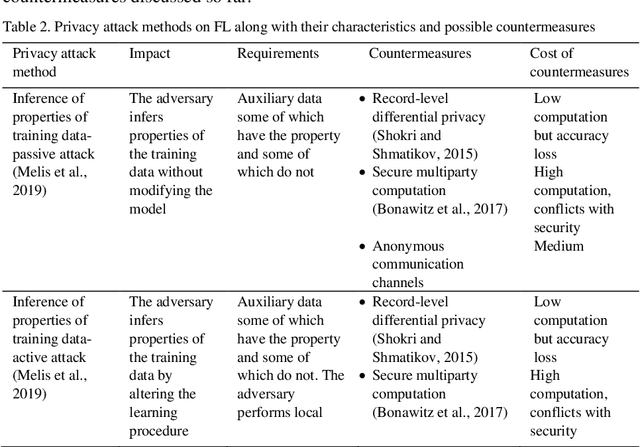
Federated learning (FL) allows a server to learn a machine learning (ML) model across multiple decentralized clients that privately store their own training data. In contrast with centralized ML approaches, FL saves computation to the server and does not require the clients to outsource their private data to the server. However, FL is not free of issues. On the one hand, the model updates sent by the clients at each training epoch might leak information on the clients' private data. On the other hand, the model learnt by the server may be subjected to attacks by malicious clients; these security attacks might poison the model or prevent it from converging. In this paper, we first examine security and privacy attacks to FL and critically survey solutions proposed in the literature to mitigate each attack. Afterwards, we discuss the difficulty of simultaneously achieving security and privacy protection. Finally, we sketch ways to tackle this open problem and attain both security and privacy.
Federated Multi-view Matrix Factorization for Personalized Recommendations
Apr 08, 2020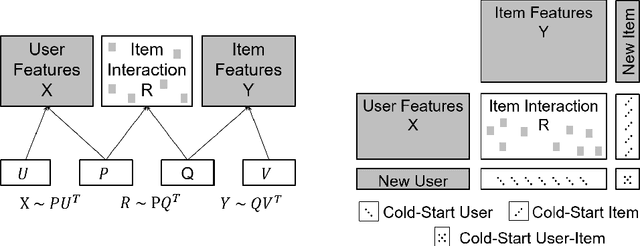

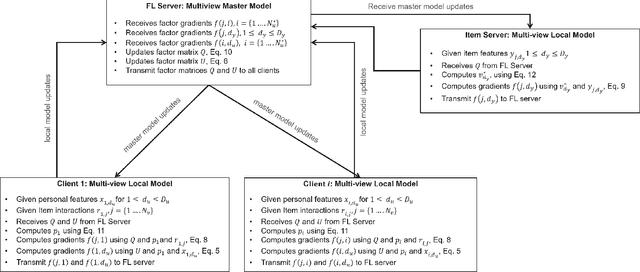
We introduce the federated multi-view matrix factorization method that extends the federated learning framework to matrix factorization with multiple data sources. Our method is able to learn the multi-view model without transferring the user's personal data to a central server. As far as we are aware this is the first federated model to provide recommendations using multi-view matrix factorization. The model is rigorously evaluated on three datasets on production settings. Empirical validation confirms that federated multi-view matrix factorization outperforms simpler methods that do not take into account the multi-view structure of the data, in addition, it demonstrates the usefulness of the proposed method for the challenging prediction tasks of cold-start federated recommendations.
Spectral Pyramid Graph Attention Network for Hyperspectral Image Classification
Jan 20, 2020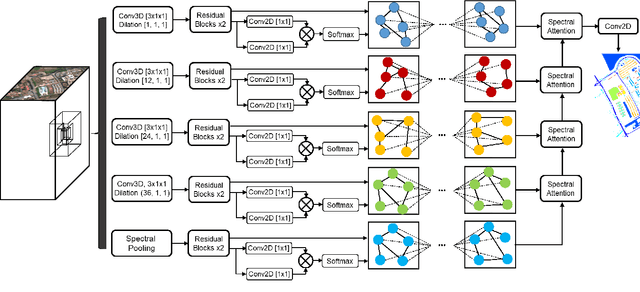
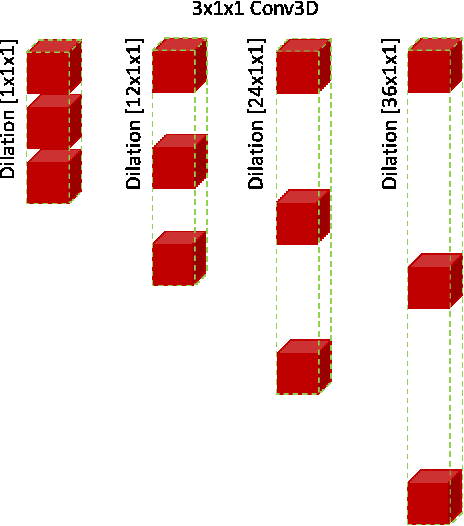
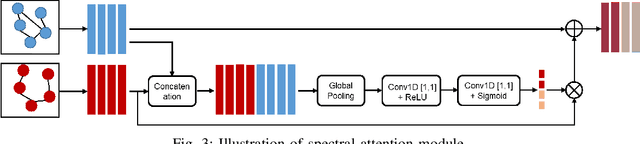
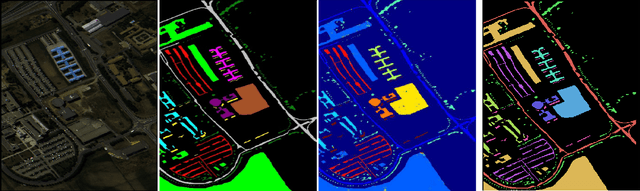
Convolutional neural networks (CNN) have made significant advances in hyperspectral image (HSI) classification. However, standard convolutional kernel neglects the intrinsic connections between data points, resulting in poor region delineation and small spurious predictions. Furthermore, HSIs have a unique continuous data distribution along the high dimensional spectrum domain - much remains to be addressed in characterizing the spectral contexts considering the prohibitively high dimensionality and improving reasoning capability in light of the limited amount of labelled data. This paper presents a novel architecture which explicitly addresses these two issues. Specifically, we design an architecture to encode the multiple spectral contextual information in the form of spectral pyramid of multiple embedding spaces. In each spectral embedding space, we propose graph attention mechanism to explicitly perform interpretable reasoning in the spatial domain based on the connection in spectral feature space. Experiments on three HSI datasets demonstrate that the proposed architecture can significantly improve the classification accuracy compared with the existing methods.
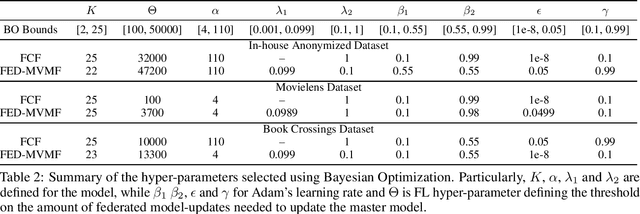
Federated Collaborative Filtering for Privacy-Preserving Personalized Recommendation System
Jan 29, 2019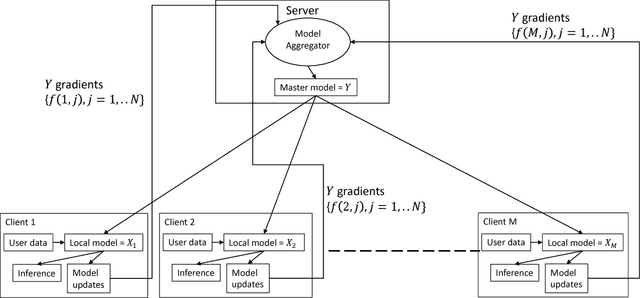
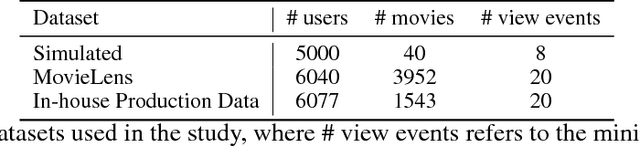
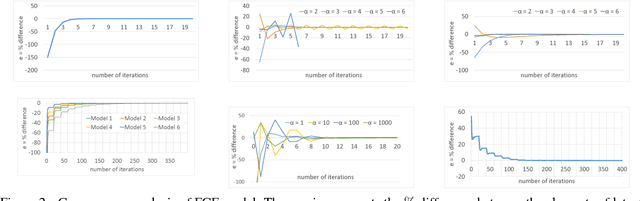
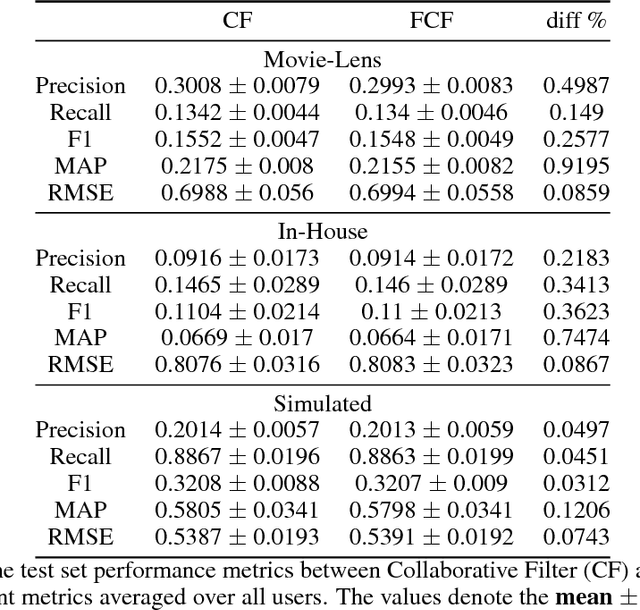
The increasing interest in user privacy is leading to new privacy preserving machine learning paradigms. In the Federated Learning paradigm, a master machine learning model is distributed to user clients, the clients use their locally stored data and model for both inference and calculating model updates. The model updates are sent back and aggregated on the server to update the master model then redistributed to the clients. In this paradigm, the user data never leaves the client, greatly enhancing the user' privacy, in contrast to the traditional paradigm of collecting, storing and processing user data on a backend server beyond the user's control. In this paper we introduce, as far as we are aware, the first federated implementation of a Collaborative Filter. The federated updates to the model are based on a stochastic gradient approach. As a classical case study in machine learning, we explore a personalized recommendation system based on users' implicit feedback and demonstrate the method's applicability to both the MovieLens and an in-house dataset. Empirical validation confirms a collaborative filter can be federated without a loss of accuracy compared to a standard implementation, hence enhancing the user's privacy in a widely used recommender application while maintaining recommender performance.