 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReWind: Understanding Long Videos with Instructed Learnable Memory
Nov 23, 2024Vision-Language Models (VLMs) are crucial for applications requiring integrated understanding textual and visual information. However, existing VLMs struggle with long videos due to computational inefficiency, memory limitations, and difficulties in maintaining coherent understanding across extended sequences. To address these challenges, we introduce ReWind, a novel memory-based VLM designed for efficient long video understanding while preserving temporal fidelity. ReWind operates in a two-stage framework. In the first stage, ReWind maintains a dynamic learnable memory module with a novel \textbf{read-perceive-write} cycle that stores and updates instruction-relevant visual information as the video unfolds. This module utilizes learnable queries and cross-attentions between memory contents and the input stream, ensuring low memory requirements by scaling linearly with the number of tokens. In the second stage, we propose an adaptive frame selection mechanism guided by the memory content to identify instruction-relevant key moments. It enriches the memory representations with detailed spatial information by selecting a few high-resolution frames, which are then combined with the memory contents and fed into a Large Language Model (LLM) to generate the final answer. We empirically demonstrate ReWind's superior performance in visual question answering (VQA) and temporal grounding tasks, surpassing previous methods on long video benchmarks. Notably, ReWind achieves a +13\% score gain and a +12\% accuracy improvement on the MovieChat-1K VQA dataset and an +8\% mIoU increase on Charades-STA for temporal grounding.
Submodular video object proposal selection for semantic object segmentation
Jul 08, 2024Learning a data-driven spatio-temporal semantic representation of the objects is the key to coherent and consistent labelling in video. This paper proposes to achieve semantic video object segmentation by learning a data-driven representation which captures the synergy of multiple instances from continuous frames. To prune the noisy detections, we exploit the rich information among multiple instances and select the discriminative and representative subset. This selection process is formulated as a facility location problem solved by maximising a submodular function. Our method retrieves the longer term contextual dependencies which underpins a robust semantic video object segmentation algorithm. We present extensive experiments on a challenging dataset that demonstrate the superior performance of our approach compared with the state-of-the-art methods.
Graph-Boosted Attentive Network for Semantic Body Parsing
Jul 08, 2024Human body parsing remains a challenging problem in natural scenes due to multi-instance and inter-part semantic confusions as well as occlusions. This paper proposes a novel approach to decomposing multiple human bodies into semantic part regions in unconstrained environments. Specifically we propose a convolutional neural network (CNN) architecture which comprises of novel semantic and contour attention mechanisms across feature hierarchy to resolve the semantic ambiguities and boundary localization issues related to semantic body parsing. We further propose to encode estimated pose as higher-level contextual information which is combined with local semantic cues in a novel graphical model in a principled manner. In this proposed model, the lower-level semantic cues can be recursively updated by propagating higher-level contextual information from estimated pose and vice versa across the graph, so as to alleviate erroneous pose information and pixel level predictions. We further propose an optimization technique to efficiently derive the solutions. Our proposed method achieves the state-of-art results on the challenging Pascal Person-Part dataset.
Non-parametric Contextual Relationship Learning for Semantic Video Object Segmentation
Jul 08, 2024We propose a novel approach for modeling semantic contextual relationships in videos. This graph-based model enables the learning and propagation of higher-level spatial-temporal contexts to facilitate the semantic labeling of local regions. We introduce an exemplar-based nonparametric view of contextual cues, where the inherent relationships implied by object hypotheses are encoded on a similarity graph of regions. Contextual relationships learning and propagation are performed to estimate the pairwise contexts between all pairs of unlabeled local regions. Our algorithm integrates the learned contexts into a Conditional Random Field (CRF) in the form of pairwise potentials and infers the per-region semantic labels. We evaluate our approach on the challenging YouTube-Objects dataset which shows that the proposed contextual relationship model outperforms the state-of-the-art methods.
Context Propagation from Proposals for Semantic Video Object Segmentation
Jul 08, 2024

In this paper, we propose a novel approach to learning semantic contextual relationships in videos for semantic object segmentation. Our algorithm derives the semantic contexts from video object proposals which encode the key evolution of objects and the relationship among objects over the spatio-temporal domain. This semantic contexts are propagated across the video to estimate the pairwise contexts between all pairs of local superpixels which are integrated into a conditional random field in the form of pairwise potentials and infers the per-superpixel semantic labels. The experiments demonstrate that our contexts learning and propagation model effectively improves the robustness of resolving visual ambiguities in semantic video object segmentation compared with the state-of-the-art methods.
Holistically-Nested Structure-Aware Graph Neural Network for Road Extraction
Jul 02, 2024Convolutional neural networks (CNN) have made significant advances in detecting roads from satellite images. However, existing CNN approaches are generally repurposed semantic segmentation architectures and suffer from the poor delineation of long and curved regions. Lack of overall road topology and structure information further deteriorates their performance on challenging remote sensing images. This paper presents a novel multi-task graph neural network (GNN) which simultaneously detects both road regions and road borders; the inter-play between these two tasks unlocks superior performance from two perspectives: (1) the hierarchically detected road borders enable the network to capture and encode holistic road structure to enhance road connectivity (2) identifying the intrinsic correlation of semantic landcover regions mitigates the difficulty in recognizing roads cluttered by regions with similar appearance. Experiments on challenging dataset demonstrate that the proposed architecture can improve the road border delineation and road extraction accuracy compared with the existing methods.
Probabilistic Subgoal Representations for Hierarchical Reinforcement learning
Jun 24, 2024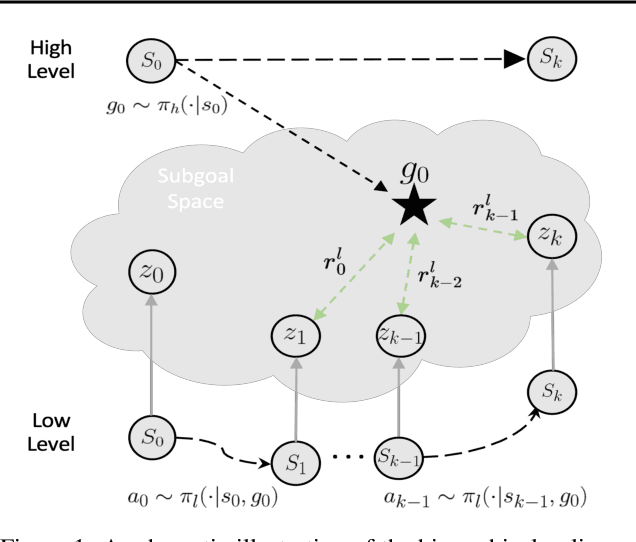
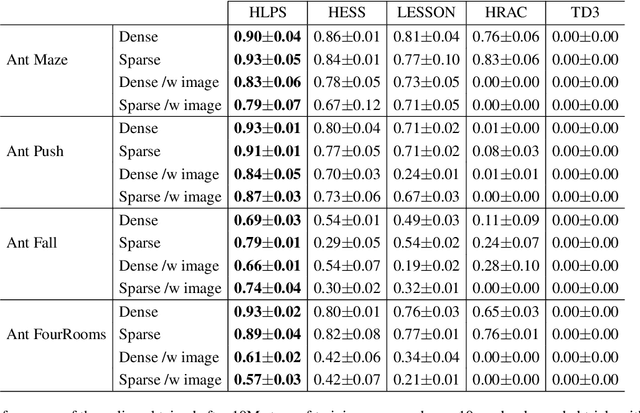
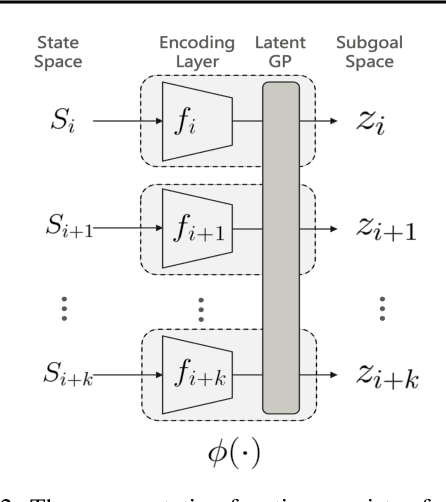
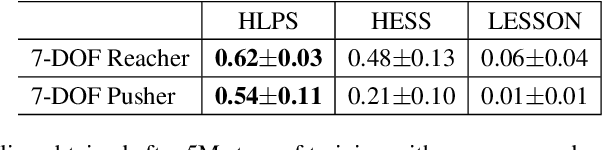
In goal-conditioned hierarchical reinforcement learning (HRL), a high-level policy specifies a subgoal for the low-level policy to reach. Effective HRL hinges on a suitable subgoal represen tation function, abstracting state space into latent subgoal space and inducing varied low-level behaviors. Existing methods adopt a subgoal representation that provides a deterministic mapping from state space to latent subgoal space. Instead, this paper utilizes Gaussian Processes (GPs) for the first probabilistic subgoal representation. Our method employs a GP prior on the latent subgoal space to learn a posterior distribution over the subgoal representation functions while exploiting the long-range correlation in the state space through learnable kernels. This enables an adaptive memory that integrates long-range subgoal information from prior planning steps allowing to cope with stochastic uncertainties. Furthermore, we propose a novel learning objective to facilitate the simultaneous learning of probabilistic subgoal representations and policies within a unified framework. In experiments, our approach outperforms state-of-the-art baselines in standard benchmarks but also in environments with stochastic elements and under diverse reward conditions. Additionally, our model shows promising capabilities in transferring low-level policies across different tasks.
Hierarchical Reinforcement Learning with Adversarially Guided Subgoals
Jan 31, 2022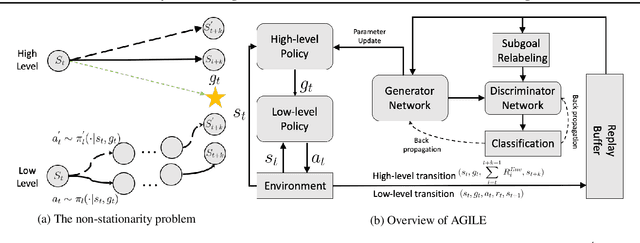

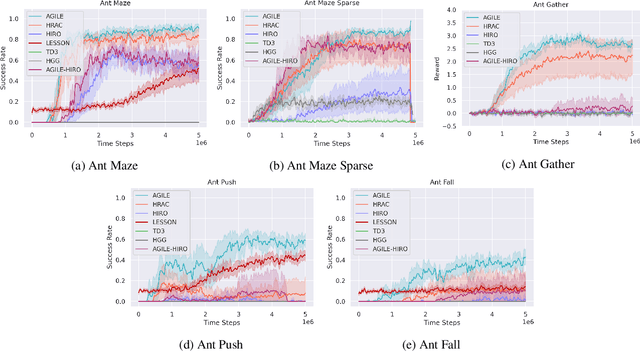
Hierarchical reinforcement learning (HRL) proposes to solve difficult tasks by performing decision-making and control at successively higher levels of temporal abstraction. However, off-policy HRL often suffers from the problem of non-stationary high-level policy since the low-level policy is constantly changing. In this paper, we propose a novel HRL approach for mitigating the non-stationarity by adversarially enforcing the high-level policy to generate subgoals compatible with the current instantiation of the low-level policy. In practice, the adversarial learning is implemented by training a simple discriminator network concurrently with the high-level policy which determines the compatibility level of subgoals. Experiments with state-of-the-art algorithms show that our approach improves both HRL learning efficiency and overall performance in various challenging continuous control tasks.
Spectral Pyramid Graph Attention Network for Hyperspectral Image Classification
Jan 20, 2020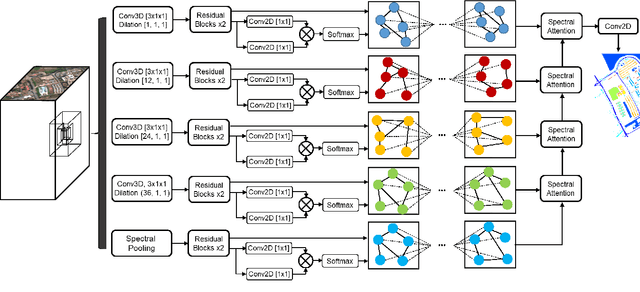
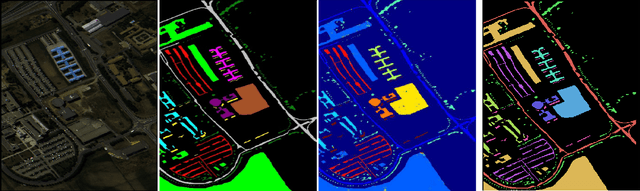
Convolutional neural networks (CNN) have made significant advances in hyperspectral image (HSI) classification. However, standard convolutional kernel neglects the intrinsic connections between data points, resulting in poor region delineation and small spurious predictions. Furthermore, HSIs have a unique continuous data distribution along the high dimensional spectrum domain - much remains to be addressed in characterizing the spectral contexts considering the prohibitively high dimensionality and improving reasoning capability in light of the limited amount of labelled data. This paper presents a novel architecture which explicitly addresses these two issues. Specifically, we design an architecture to encode the multiple spectral contextual information in the form of spectral pyramid of multiple embedding spaces. In each spectral embedding space, we propose graph attention mechanism to explicitly perform interpretable reasoning in the spatial domain based on the connection in spectral feature space. Experiments on three HSI datasets demonstrate that the proposed architecture can significantly improve the classification accuracy compared with the existing methods.
Simultaneously Learning Architectures and Features of Deep Neural Networks
Jun 11, 2019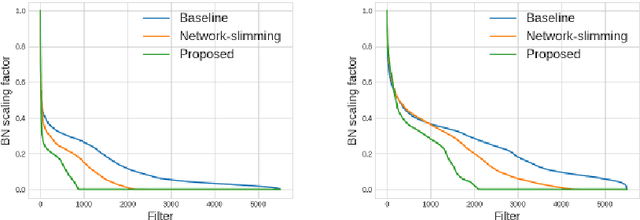
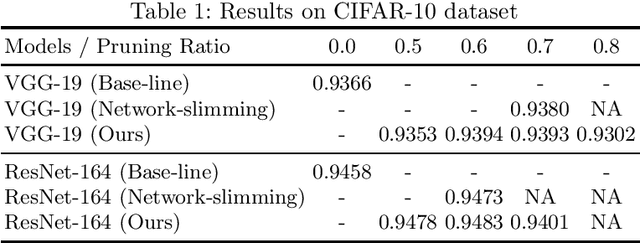
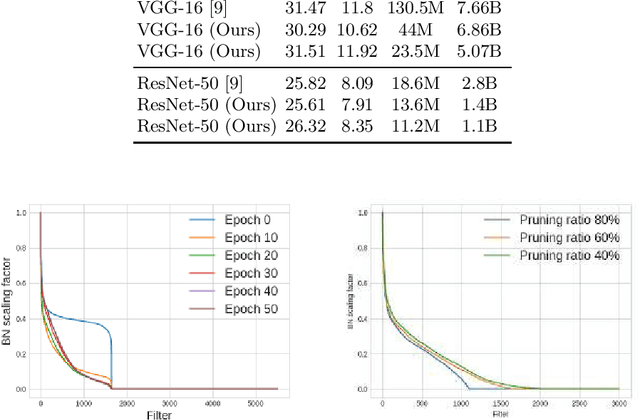
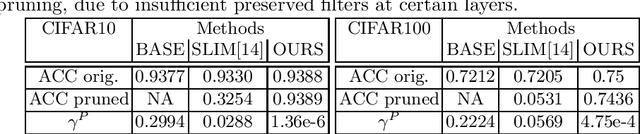
This paper presents a novel method which simultaneously learns the number of filters and network features repeatedly over multiple epochs. We propose a novel pruning loss to explicitly enforces the optimizer to focus on promising candidate filters while suppressing contributions of less relevant ones. In the meanwhile, we further propose to enforce the diversities between filters and this diversity-based regularization term improves the trade-off between model sizes and accuracies. It turns out the interplay between architecture and feature optimizations improves the final compressed models, and the proposed method is compared favorably to existing methods, in terms of both models sizes and accuracies for a wide range of applications including image classification, image compression and audio classification.