 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAWS: Perception of Articulation in the Wild at Scale from Egocentric Videos
Mar 26, 2026Articulation perception aims to recover the motion and structure of articulated objects (e.g., drawers and cupboards), and is fundamental to 3D scene understanding in robotics, simulation, and animation. Existing learning-based methods rely heavily on supervised training with high-quality 3D data and manual annotations, limiting scalability and diversity. To address this limitation, we propose PAWS, a method that directly extracts object articulations from hand-object interactions in large-scale in-the-wild egocentric videos. We evaluate our method on the public data sets, including HD-EPIC and Arti4D data sets, achieving significant improvements over baselines. We further demonstrate that the extracted articulations benefit downstream tasks, including fine-tuning 3D articulation prediction models and enabling robot manipulation. See the project website at https://aaltoml.github.io/PAWS/.
RubricEval: A Rubric-Level Meta-Evaluation Benchmark for LLM Judges in Instruction Following
Mar 26, 2026Rubric-based evaluation has become a prevailing paradigm for evaluating instruction following in large language models (LLMs). Despite its widespread use, the reliability of these rubric-level evaluations remains unclear, calling for meta-evaluation. However, prior meta-evaluation efforts largely focus on the response level, failing to assess the fine-grained judgment accuracy that rubric-based evaluation relies on. To bridge this gap, we introduce RubricEval. Our benchmark features: (1) the first rubric-level meta-evaluation benchmark for instruction following, (2) diverse instructions and responses spanning multiple categories and model sources, and (3) a substantial set of 3,486 quality-controlled instances, along with Easy/Hard subsets that better differentiates judge performance. Our experiments reveal that rubric-level judging remains far from solved: even GPT-4o, a widely adopted judge in instruction-following benchmarks, achieves only 55.97% on Hard subset. Considering evaluation paradigm, rubric-level evaluation outperforms checklist-level, explicit reasoning improves accuracy, and both together reduce inter-judge variance. Through our established rubric taxonomy, we further identify common failure modes and offer actionable insights for reliable instruction-following evaluation.
An Industrial-Scale Insurance LLM Achieving Verifiable Domain Mastery and Hallucination Control without Competence Trade-offs
Mar 15, 2026Adapting Large Language Models (LLMs) to high-stakes vertical domains like insurance presents a significant challenge: scenarios demand strict adherence to complex regulations and business logic with zero tolerance for hallucinations. Existing approaches often suffer from a Competency Trade-off - sacrificing general intelligence for domain expertise - or rely heavily on RAG without intrinsic reasoning. To bridge this gap, we present INS-S1, an insurance-specific LLM family trained via a novel end-to-end alignment paradigm. Our approach features two methodological innovations: (1) A Verifiable Data Synthesis System that constructs hierarchical datasets for actuarial reasoning and compliance; and (2) A Progressive SFT-RL Curriculum Framework that integrates dynamic data annealing with a synergistic mix of Verified Reasoning (RLVR) and AI Feedback (RLAIF). By optimizing data ratios and reward signals, this framework enforces domain constraints while preventing catastrophic forgetting. Additionally, we release INSEva, the most comprehensive insurance benchmark to date (39k+ samples). Extensive experiments show that INS-S1 achieves SOTA performance on domain tasks, significantly outperforming DeepSeek-R1 and Gemini-2.5-Pro. Crucially, it maintains top-tier general capabilities and achieves a record-low 0.6% hallucination rate (HHEM). Our results demonstrate that rigorous domain specialization can be achieved without compromising general intelligence.
GCHR : Goal-Conditioned Hindsight Regularization for Sample-Efficient Reinforcement Learning
Aug 08, 2025



Goal-conditioned reinforcement learning (GCRL) with sparse rewards remains a fundamental challenge in reinforcement learning. While hindsight experience replay (HER) has shown promise by relabeling collected trajectories with achieved goals, we argue that trajectory relabeling alone does not fully exploit the available experiences in off-policy GCRL methods, resulting in limited sample efficiency. In this paper, we propose Hindsight Goal-conditioned Regularization (HGR), a technique that generates action regularization priors based on hindsight goals. When combined with hindsight self-imitation regularization (HSR), our approach enables off-policy RL algorithms to maximize experience utilization. Compared to existing GCRL methods that employ HER and self-imitation techniques, our hindsight regularizations achieve substantially more efficient sample reuse and the best performances, which we empirically demonstrate on a suite of navigation and manipulation tasks.
Smoothing Slot Attention Iterations and Recurrences
Aug 07, 2025Slot Attention (SA) and its variants lie at the heart of mainstream Object-Centric Learning (OCL). Objects in an image can be aggregated into respective slot vectors, by \textit{iteratively} refining cold-start query vectors, typically three times, via SA on image features. For video, such aggregation is \textit{recurrently} shared across frames, with queries cold-started on the first frame while transitioned from the previous frame's slots on non-first frames. However, the cold-start queries lack sample-specific cues thus hinder precise aggregation on the image or video's first frame; Also, non-first frames' queries are already sample-specific thus require transforms different from the first frame's aggregation. We address these issues for the first time with our \textit{SmoothSA}: (1) To smooth SA iterations on the image or video's first frame, we \textit{preheat} the cold-start queries with rich information of input features, via a tiny module self-distilled inside OCL; (2) To smooth SA recurrences across all video frames, we \textit{differentiate} the homogeneous transforms on the first and non-first frames, by using full and single iterations respectively. Comprehensive experiments on object discovery, recognition and downstream benchmarks validate our method's effectiveness. Further analyses intuitively illuminate how our method smooths SA iterations and recurrences. Our code is available in the supplement.
Symbolically-Guided Visual Plan Inference from Uncurated Video Data
May 13, 2025Visual planning, by offering a sequence of intermediate visual subgoals to a goal-conditioned low-level policy, achieves promising performance on long-horizon manipulation tasks. To obtain the subgoals, existing methods typically resort to video generation models but suffer from model hallucination and computational cost. We present Vis2Plan, an efficient, explainable and white-box visual planning framework powered by symbolic guidance. From raw, unlabeled play data, Vis2Plan harnesses vision foundation models to automatically extract a compact set of task symbols, which allows building a high-level symbolic transition graph for multi-goal, multi-stage planning. At test time, given a desired task goal, our planner conducts planning at the symbolic level and assembles a sequence of physically consistent intermediate sub-goal images grounded by the underlying symbolic representation. Our Vis2Plan outperforms strong diffusion video generation-based visual planners by delivering 53\% higher aggregate success rate in real robot settings while generating visual plans 35$\times$ faster. The results indicate that Vis2Plan is able to generate physically consistent image goals while offering fully inspectable reasoning steps.
DeMoBot: Deformable Mobile Manipulation with Vision-based Sub-goal Retrieval
Aug 28, 2024

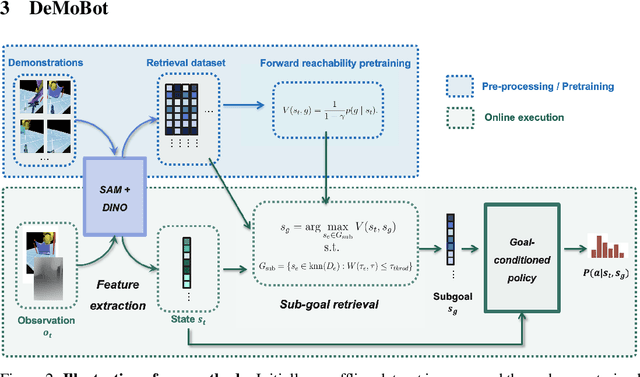

Imitation learning (IL) algorithms typically distill experience into parametric behavior policies to mimic expert demonstrations. Despite their effectiveness, previous methods often struggle with data efficiency and accurately aligning the current state with expert demonstrations, especially in deformable mobile manipulation tasks characterized by partial observations and dynamic object deformations. In this paper, we introduce \textbf{DeMoBot}, a novel IL approach that directly retrieves observations from demonstrations to guide robots in \textbf{De}formable \textbf{Mo}bile manipulation tasks. DeMoBot utilizes vision foundation models to identify relevant expert data based on visual similarity and matches the current trajectory with demonstrated trajectories using trajectory similarity and forward reachability constraints to select suitable sub-goals. Once a goal is determined, a motion generation policy will guide the robot to the next state until the task is completed. We evaluated DeMoBot using a Spot robot in several simulated and real-world settings, demonstrating its effectiveness and generalizability. With only 20 demonstrations, DeMoBot significantly outperforms the baselines, reaching a 50\% success rate in curtain opening and 85\% in gap covering in simulation.
Probabilistic Subgoal Representations for Hierarchical Reinforcement learning
Jun 24, 2024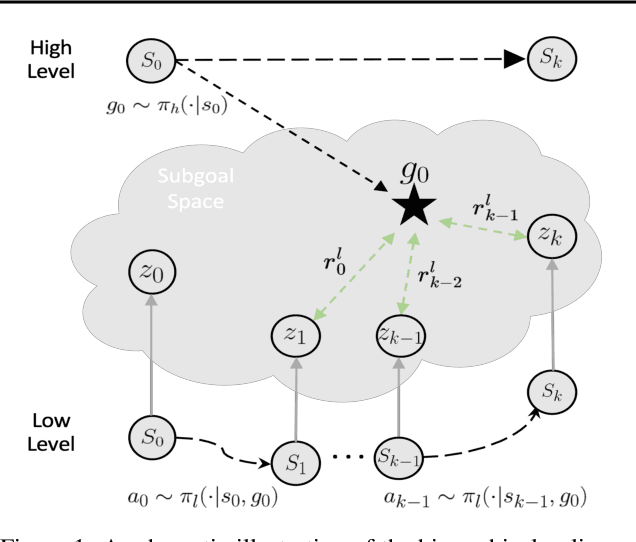
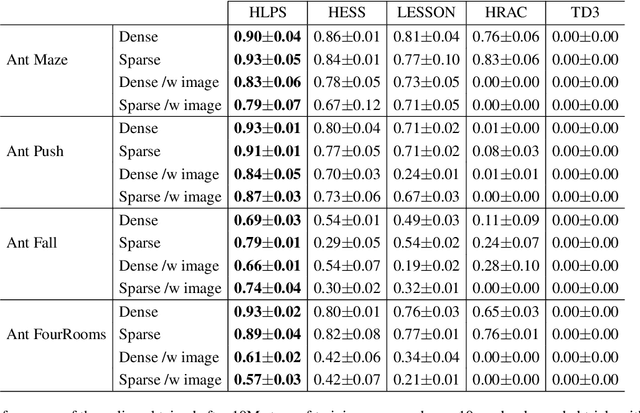
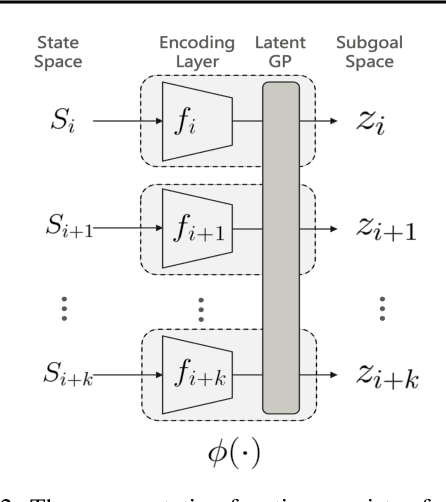
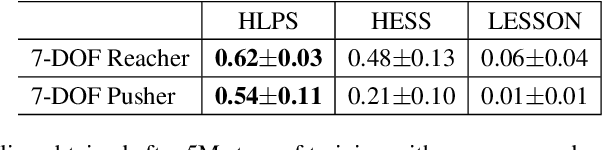
In goal-conditioned hierarchical reinforcement learning (HRL), a high-level policy specifies a subgoal for the low-level policy to reach. Effective HRL hinges on a suitable subgoal represen tation function, abstracting state space into latent subgoal space and inducing varied low-level behaviors. Existing methods adopt a subgoal representation that provides a deterministic mapping from state space to latent subgoal space. Instead, this paper utilizes Gaussian Processes (GPs) for the first probabilistic subgoal representation. Our method employs a GP prior on the latent subgoal space to learn a posterior distribution over the subgoal representation functions while exploiting the long-range correlation in the state space through learnable kernels. This enables an adaptive memory that integrates long-range subgoal information from prior planning steps allowing to cope with stochastic uncertainties. Furthermore, we propose a novel learning objective to facilitate the simultaneous learning of probabilistic subgoal representations and policies within a unified framework. In experiments, our approach outperforms state-of-the-art baselines in standard benchmarks but also in environments with stochastic elements and under diverse reward conditions. Additionally, our model shows promising capabilities in transferring low-level policies across different tasks.
Seq2Seq Imitation Learning for Tactile Feedback-based Manipulation
Mar 05, 2023Robot control for tactile feedback-based manipulation can be difficult due to the modeling of physical contacts, partial observability of the environment, and noise in perception and control. This work focuses on solving partial observability of contact-rich manipulation tasks as a Sequence-to-Sequence (Seq2Seq)} Imitation Learning (IL) problem. The proposed Seq2Seq model produces a robot-environment interaction sequence to estimate the partially observable environment state variables. Then, the observed interaction sequence is transformed to a control sequence for the task itself. The proposed Seq2Seq IL for tactile feedback-based manipulation is experimentally validated on a door-open task in a simulated environment and a snap-on insertion task with a real robot. The model is able to learn both tasks from only 50 expert demonstrations, while state-of-the-art reinforcement learning and imitation learning methods fail.
Swapped goal-conditioned offline reinforcement learning
Feb 17, 2023Offline goal-conditioned reinforcement learning (GCRL) can be challenging due to overfitting to the given dataset. To generalize agents' skills outside the given dataset, we propose a goal-swapping procedure that generates additional trajectories. To alleviate the problem of noise and extrapolation errors, we present a general offline reinforcement learning method called deterministic Q-advantage policy gradient (DQAPG). In the experiments, DQAPG outperforms state-of-the-art goal-conditioned offline RL methods in a wide range of benchmark tasks, and goal-swapping further improves the test results. It is noteworthy, that the proposed method obtains good performance on the challenging dexterous in-hand manipulation tasks for which the prior methods failed.