 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGS-Pose: Cascaded Framework for Generalizable Segmentation-based 6D Object Pose Estimation
Mar 15, 2024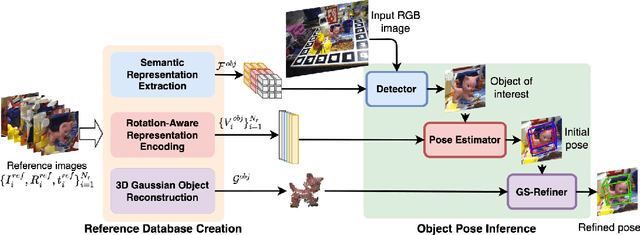
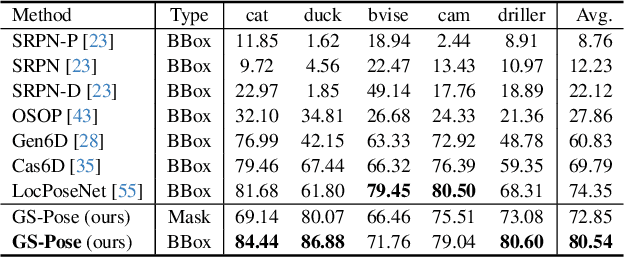
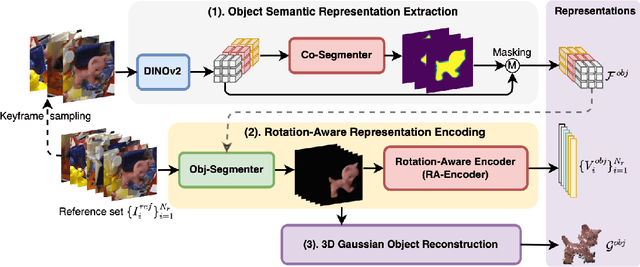
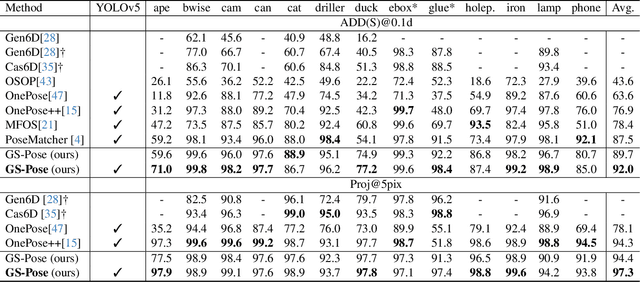
This paper introduces GS-Pose, an end-to-end framework for locating and estimating the 6D pose of objects. GS-Pose begins with a set of posed RGB images of a previously unseen object and builds three distinct representations stored in a database. At inference, GS-Pose operates sequentially by locating the object in the input image, estimating its initial 6D pose using a retrieval approach, and refining the pose with a render-and-compare method. The key insight is the application of the appropriate object representation at each stage of the process. In particular, for the refinement step, we utilize 3D Gaussian splatting, a novel differentiable rendering technique that offers high rendering speed and relatively low optimization time. Off-the-shelf toolchains and commodity hardware, such as mobile phones, can be used to capture new objects to be added to the database. Extensive evaluations on the LINEMOD and OnePose-LowTexture datasets demonstrate excellent performance, establishing the new state-of-the-art. Project page: https://dingdingcai.github.io/gs-pose.
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
Nov 05, 2023Metaverse technologies demand accurate, real-time, and immersive modeling on consumer-grade hardware for both non-human perception (e.g., drone/robot/autonomous car navigation) and immersive technologies like AR/VR, requiring both structural accuracy and photorealism. However, there exists a knowledge gap in how to apply geometric reconstruction and photorealism modeling (novel view synthesis) in a unified framework. To address this gap and promote the development of robust and immersive modeling and rendering with consumer-grade devices, first, we propose a real-world Multi-Sensor Hybrid Room Dataset (MuSHRoom). Our dataset presents exciting challenges and requires state-of-the-art methods to be cost-effective, robust to noisy data and devices, and can jointly learn 3D reconstruction and novel view synthesis, instead of treating them as separate tasks, making them ideal for real-world applications. Second, we benchmark several famous pipelines on our dataset for joint 3D mesh reconstruction and novel view synthesis. Finally, in order to further improve the overall performance, we propose a new method that achieves a good trade-off between the two tasks. Our dataset and benchmark show great potential in promoting the improvements for fusing 3D reconstruction and high-quality rendering in a robust and computationally efficient end-to-end fashion.
Swapped goal-conditioned offline reinforcement learning
Feb 17, 2023Offline goal-conditioned reinforcement learning (GCRL) can be challenging due to overfitting to the given dataset. To generalize agents' skills outside the given dataset, we propose a goal-swapping procedure that generates additional trajectories. To alleviate the problem of noise and extrapolation errors, we present a general offline reinforcement learning method called deterministic Q-advantage policy gradient (DQAPG). In the experiments, DQAPG outperforms state-of-the-art goal-conditioned offline RL methods in a wide range of benchmark tasks, and goal-swapping further improves the test results. It is noteworthy, that the proposed method obtains good performance on the challenging dexterous in-hand manipulation tasks for which the prior methods failed.
MSDA: Monocular Self-supervised Domain Adaptation for 6D Object Pose Estimation
Feb 14, 2023
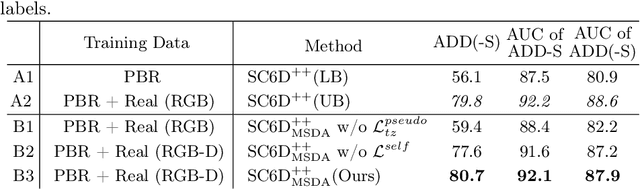

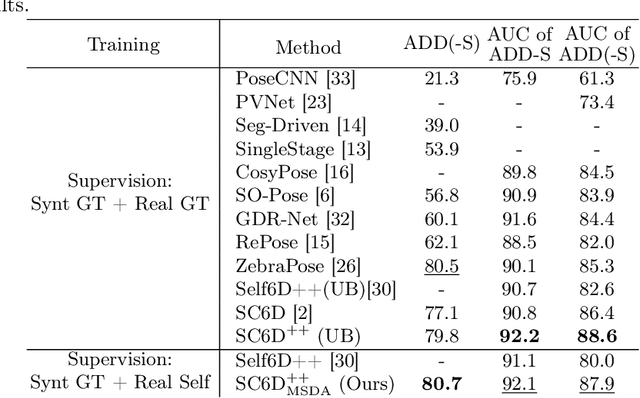
Acquiring labeled 6D poses from real images is an expensive and time-consuming task. Though massive amounts of synthetic RGB images are easy to obtain, the models trained on them suffer from noticeable performance degradation due to the synthetic-to-real domain gap. To mitigate this degradation, we propose a practical self-supervised domain adaptation approach that takes advantage of real RGB(-D) data without needing real pose labels. We first pre-train the model with synthetic RGB images and then utilize real RGB(-D) images to fine-tune the pre-trained model. The fine-tuning process is self-supervised by the RGB-based pose-aware consistency and the depth-guided object distance pseudo-label, which does not require the time-consuming online differentiable rendering. We build our domain adaptation method based on the recent pose estimator SC6D and evaluate it on the YCB-Video dataset. We experimentally demonstrate that our method achieves comparable performance against its fully-supervised counterpart while outperforming existing state-of-the-art approaches.
SC6D: Symmetry-agnostic and Correspondence-free 6D Object Pose Estimation
Aug 04, 2022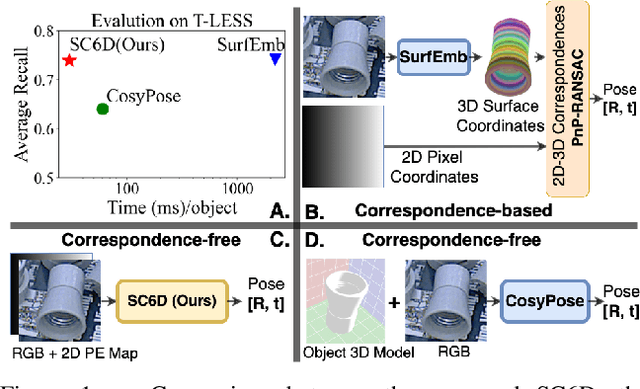
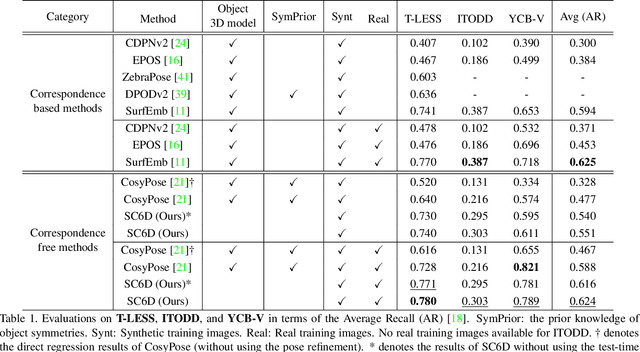


This paper presents an efficient symmetry-agnostic and correspondence-free framework, referred to as SC6D, for 6D object pose estimation from a single monocular RGB image. SC6D requires neither the 3D CAD model of the object nor any prior knowledge of the symmetries. The pose estimation is decomposed into three sub-tasks: a) object 3D rotation representation learning and matching; b) estimation of the 2D location of the object center; and c) scale-invariant distance estimation (the translation along the z-axis) via classification. SC6D is evaluated on three benchmark datasets, T-LESS, YCB-V, and ITODD, and results in state-of-the-art performance on the T-LESS dataset. Moreover, SC6D is computationally much more efficient than the previous state-of-the-art method SurfEmb. The implementation and pre-trained models are publicly available at https://github.com/dingdingcai/SC6D-pose.
OVE6D: Object Viewpoint Encoding for Depth-based 6D Object Pose Estimation
Apr 07, 2022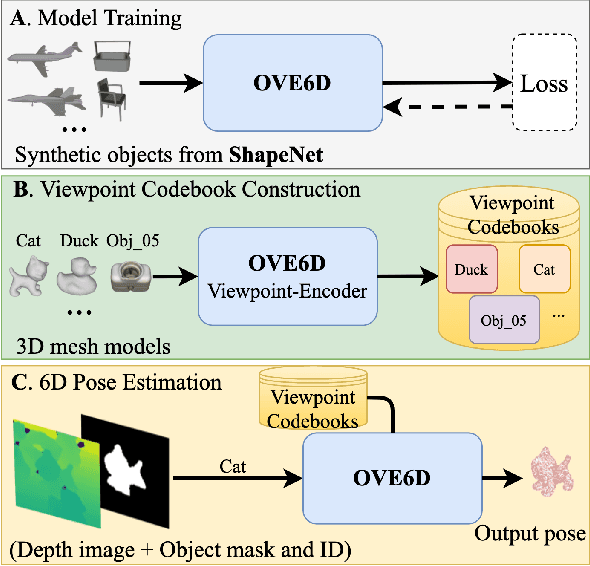
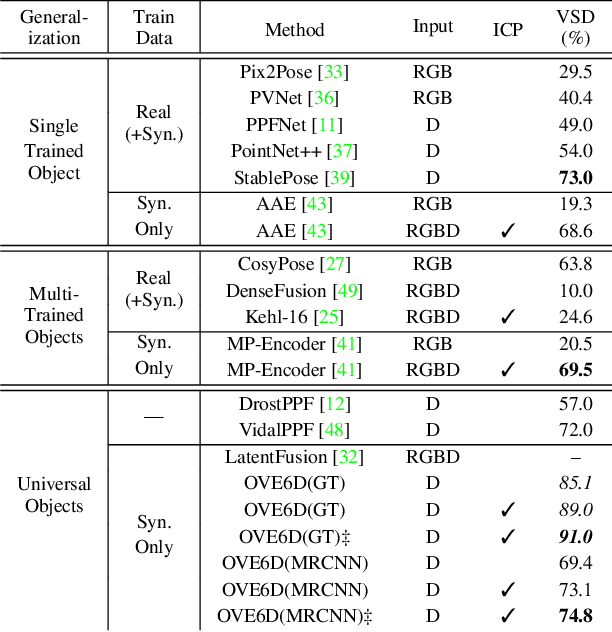
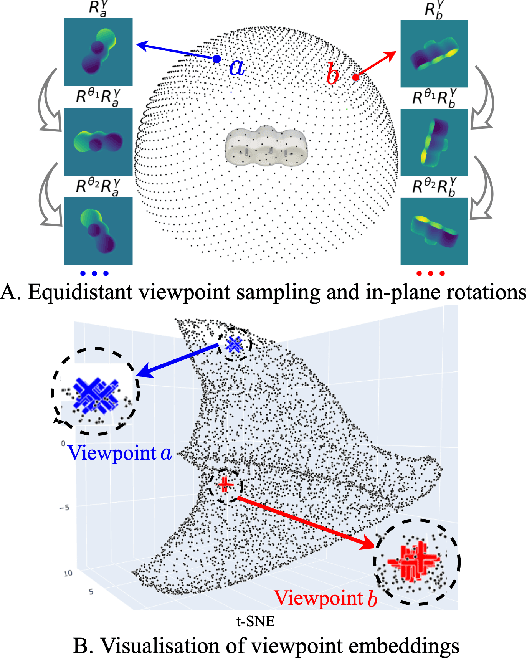
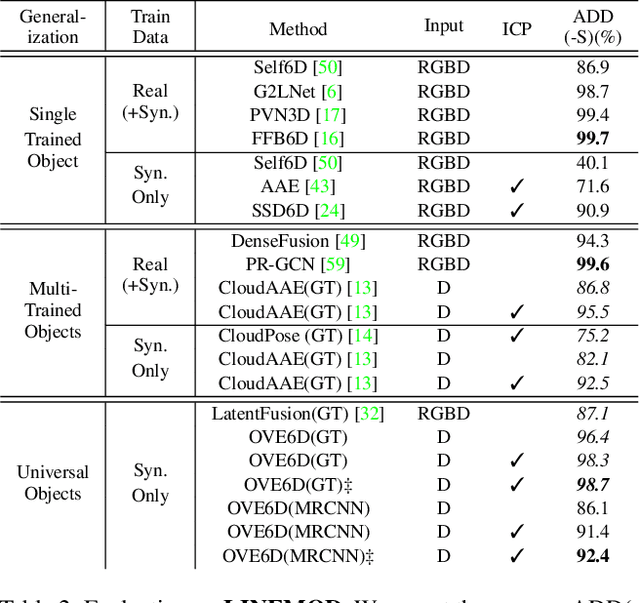
This paper proposes a universal framework, called OVE6D, for model-based 6D object pose estimation from a single depth image and a target object mask. Our model is trained using purely synthetic data rendered from ShapeNet, and, unlike most of the existing methods, it generalizes well on new real-world objects without any fine-tuning. We achieve this by decomposing the 6D pose into viewpoint, in-plane rotation around the camera optical axis and translation, and introducing novel lightweight modules for estimating each component in a cascaded manner. The resulting network contains less than 4M parameters while demonstrating excellent performance on the challenging T-LESS and Occluded LINEMOD datasets without any dataset-specific training. We show that OVE6D outperforms some contemporary deep learning-based pose estimation methods specifically trained for individual objects or datasets with real-world training data. The implementation and the pre-trained model will be made publicly available.
Convolutional Low-Resolution Fine-Grained Classification
Oct 16, 2017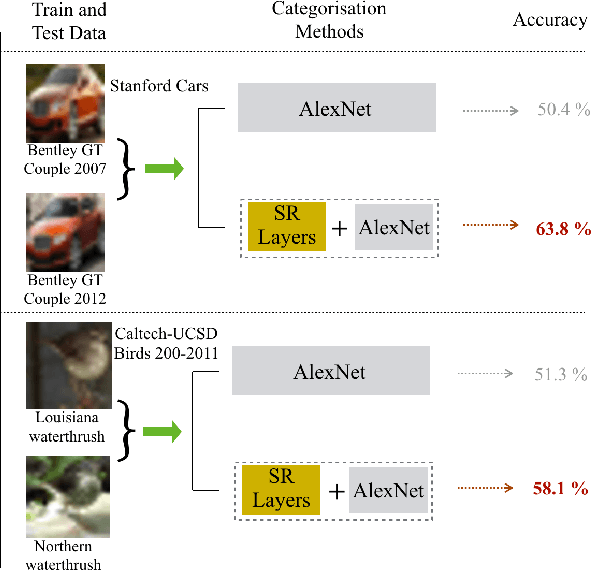
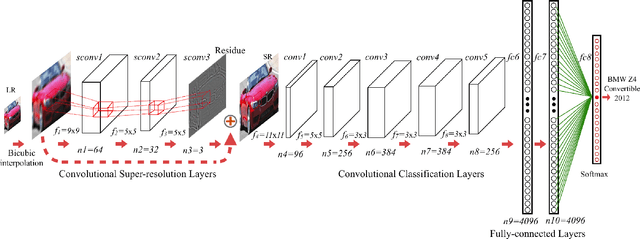

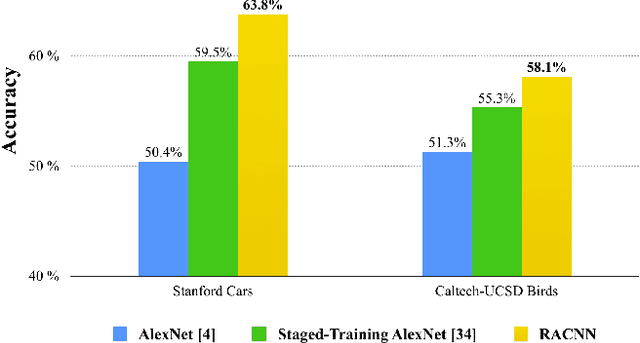
Successful fine-grained image classification methods learn subtle details between visually similar (sub-)classes, but the problem becomes significantly more challenging if the details are missing due to low resolution. Encouraged by the recent success of Convolutional Neural Network (CNN) architectures in image classification, we propose a novel resolution-aware deep model which combines convolutional image super-resolution and convolutional fine-grained classification into a single model in an end-to-end manner. Extensive experiments on the Stanford Cars and Caltech-UCSD Birds 200-2011 benchmarks demonstrate that the proposed model consistently performs better than conventional convolutional net on classifying fine-grained object classes in low-resolution images.