 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFIORD: A Fisheye Indoor-Outdoor Dataset with LIDAR Ground Truth for 3D Scene Reconstruction and Benchmarking
Apr 02, 2025The development of large-scale 3D scene reconstruction and novel view synthesis methods mostly rely on datasets comprising perspective images with narrow fields of view (FoV). While effective for small-scale scenes, these datasets require large image sets and extensive structure-from-motion (SfM) processing, limiting scalability. To address this, we introduce a fisheye image dataset tailored for scene reconstruction tasks. Using dual 200-degree fisheye lenses, our dataset provides full 360-degree coverage of 5 indoor and 5 outdoor scenes. Each scene has sparse SfM point clouds and precise LIDAR-derived dense point clouds that can be used as geometric ground-truth, enabling robust benchmarking under challenging conditions such as occlusions and reflections. While the baseline experiments focus on vanilla Gaussian Splatting and NeRF based Nerfacto methods, the dataset supports diverse approaches for scene reconstruction, novel view synthesis, and image-based rendering.
AGS-Mesh: Adaptive Gaussian Splatting and Meshing with Geometric Priors for Indoor Room Reconstruction Using Smartphones
Nov 28, 2024Geometric priors are often used to enhance 3D reconstruction. With many smartphones featuring low-resolution depth sensors and the prevalence of off-the-shelf monocular geometry estimators, incorporating geometric priors as regularization signals has become common in 3D vision tasks. However, the accuracy of depth estimates from mobile devices is typically poor for highly detailed geometry, and monocular estimators often suffer from poor multi-view consistency and precision. In this work, we propose an approach for joint surface depth and normal refinement of Gaussian Splatting methods for accurate 3D reconstruction of indoor scenes. We develop supervision strategies that adaptively filters low-quality depth and normal estimates by comparing the consistency of the priors during optimization. We mitigate regularization in regions where prior estimates have high uncertainty or ambiguities. Our filtering strategy and optimization design demonstrate significant improvements in both mesh estimation and novel-view synthesis for both 3D and 2D Gaussian Splatting-based methods on challenging indoor room datasets. Furthermore, we explore the use of alternative meshing strategies for finer geometry extraction. We develop a scale-aware meshing strategy inspired by TSDF and octree-based isosurface extraction, which recovers finer details from Gaussian models compared to other commonly used open-source meshing tools. Our code is released in https://xuqianren.github.io/ags_mesh_website/.
DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
Mar 26, 2024



3D Gaussian splatting, a novel differentiable rendering technique, has achieved state-of-the-art novel view synthesis results with high rendering speeds and relatively low training times. However, its performance on scenes commonly seen in indoor datasets is poor due to the lack of geometric constraints during optimization. We extend 3D Gaussian splatting with depth and normal cues to tackle challenging indoor datasets and showcase techniques for efficient mesh extraction, an important downstream application. Specifically, we regularize the optimization procedure with depth information, enforce local smoothness of nearby Gaussians, and use the geometry of the 3D Gaussians supervised by normal cues to achieve better alignment with the true scene geometry. We improve depth estimation and novel view synthesis results over baselines and show how this simple yet effective regularization technique can be used to directly extract meshes from the Gaussian representation yielding more physically accurate reconstructions on indoor scenes. Our code will be released in https://github.com/maturk/dn-splatter.
HumanRecon: Neural Reconstruction of Dynamic Human Using Geometric Cues and Physical Priors
Nov 26, 2023Recent methods for dynamic human reconstruction have attained promising reconstruction results. Most of these methods rely only on RGB color supervision without considering explicit geometric constraints. This leads to existing human reconstruction techniques being more prone to overfitting to color and causes geometrically inherent ambiguities, especially in the sparse multi-view setup. Motivated by recent advances in the field of monocular geometry prediction, we consider the geometric constraints of estimated depth and normals in the learning of neural implicit representation for dynamic human reconstruction. As a geometric regularization, this provides reliable yet explicit supervision information, and improves reconstruction quality. We also exploit several beneficial physical priors, such as adding noise into view direction and maximizing the density on the human surface. These priors ensure the color rendered along rays to be robust to view direction and reduce the inherent ambiguities of density estimated along rays. Experimental results demonstrate that depth and normal cues, predicted by human-specific monocular estimators, can provide effective supervision signals and render more accurate images. Finally, we also show that the proposed physical priors significantly reduce overfitting and improve the overall quality of novel view synthesis. Our code is available at:~\href{https://github.com/PRIS-CV/HumanRecon}{https://github.com/PRIS-CV/HumanRecon}.
MuSHRoom: Multi-Sensor Hybrid Room Dataset for Joint 3D Reconstruction and Novel View Synthesis
Nov 05, 2023Metaverse technologies demand accurate, real-time, and immersive modeling on consumer-grade hardware for both non-human perception (e.g., drone/robot/autonomous car navigation) and immersive technologies like AR/VR, requiring both structural accuracy and photorealism. However, there exists a knowledge gap in how to apply geometric reconstruction and photorealism modeling (novel view synthesis) in a unified framework. To address this gap and promote the development of robust and immersive modeling and rendering with consumer-grade devices, first, we propose a real-world Multi-Sensor Hybrid Room Dataset (MuSHRoom). Our dataset presents exciting challenges and requires state-of-the-art methods to be cost-effective, robust to noisy data and devices, and can jointly learn 3D reconstruction and novel view synthesis, instead of treating them as separate tasks, making them ideal for real-world applications. Second, we benchmark several famous pipelines on our dataset for joint 3D mesh reconstruction and novel view synthesis. Finally, in order to further improve the overall performance, we propose a new method that achieves a good trade-off between the two tasks. Our dataset and benchmark show great potential in promoting the improvements for fusing 3D reconstruction and high-quality rendering in a robust and computationally efficient end-to-end fashion.
Unsupervised Gait Recognition with Selective Fusion
Mar 19, 2023Previous gait recognition methods primarily trained on labeled datasets, which require painful labeling effort. However, using a pre-trained model on a new dataset without fine-tuning can lead to significant performance degradation. So to make the pre-trained gait recognition model able to be fine-tuned on unlabeled datasets, we propose a new task: Unsupervised Gait Recognition (UGR). We introduce a new cluster-based baseline to solve UGR with cluster-level contrastive learning. But we further find more challenges this task meets. First, sequences of the same person in different clothes tend to cluster separately due to the significant appearance changes. Second, sequences taken from 0 and 180 views lack walking postures and do not cluster with sequences taken from other views. To address these challenges, we propose a Selective Fusion method, which includes Selective Cluster Fusion (SCF) and Selective Sample Fusion (SSF). With SCF, we merge matched clusters of the same person wearing different clothes by updating the cluster-level memory bank with a multi-cluster update strategy. And in SSF, we merge sequences taken from front/back views gradually with curriculum learning. Extensive experiments show the effectiveness of our method in improving the rank-1 accuracy in walking with different coats condition and front/back views conditions.
Semantic-guided Multi-Mask Image Harmonization
Jul 24, 2022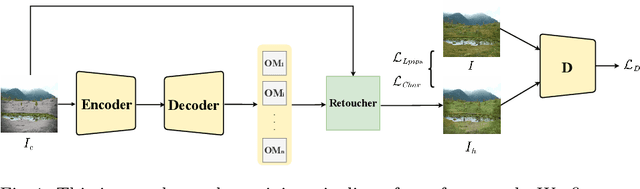



Previous harmonization methods focus on adjusting one inharmonious region in an image based on an input mask. They may face problems when dealing with different perturbations on different semantic regions without available input masks. To deal with the problem that one image has been pasted with several foregrounds coming from different images and needs to harmonize them towards different domain directions without any mask as input, we propose a new semantic-guided multi-mask image harmonization task. Different from the previous single-mask image harmonization task, each inharmonious image is perturbed with different methods according to the semantic segmentation masks. Two challenging benchmarks, HScene and HLIP, are constructed based on $150$ and $19$ semantic classes, respectively. Furthermore, previous baselines focus on regressing the exact value for each pixel of the harmonized images. The generated results are in the `black box' and cannot be edited. In this work, we propose a novel way to edit the inharmonious images by predicting a series of operator masks. The masks indicate the level and the position to apply a certain image editing operation, which could be the brightness, the saturation, and the color in a specific dimension. The operator masks provide more flexibility for users to edit the image further. Extensive experiments verify that the operator mask-based network can further improve those state-of-the-art methods which directly regress RGB images when the perturbations are structural. Experiments have been conducted on our constructed benchmarks to verify that our proposed operator mask-based framework can locate and modify the inharmonious regions in more complex scenes. Our code and models are available at https://github.com/XuqianRen/Semantic-guided-Multi-mask-Image-Harmonization.git.
Progressive Feature Learning for Realistic Cloth-Changing Gait Recognition
Jul 24, 2022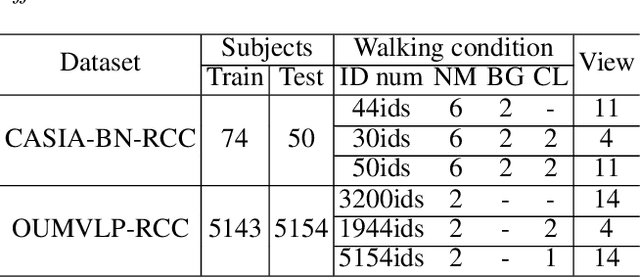
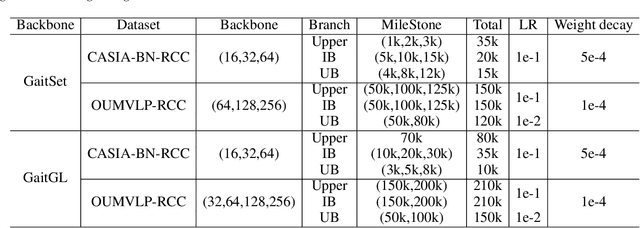
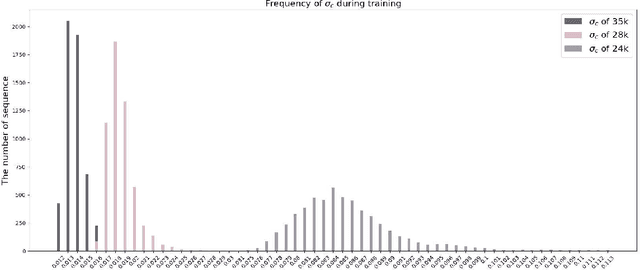
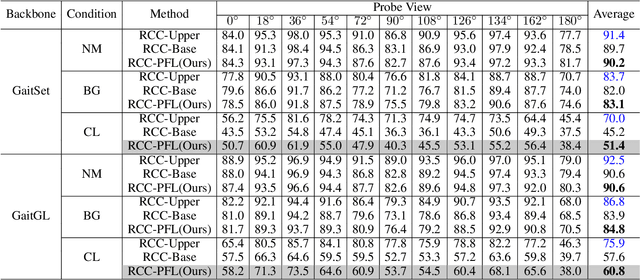
Gait recognition is instrumental in crime prevention and social security, for it can be conducted at a long distance without the cooperation of subjects. However, existing datasets and methods cannot deal with the most challenging problem in realistic gait recognition effectively: walking in different clothes (CL). In order to tackle this problem, we propose two benchmarks: CASIA-BN-RCC and OUMVLP-RCC, to simulate the cloth-changing condition in practice. The two benchmarks can force the algorithm to realize cross-view and cross-cloth with two sub-datasets. Furthermore, we propose a new framework that can be applied with off-the-shelf backbones to improve its performance in the Realistic Cloth-Changing problem with Progressive Feature Learning. Specifically, in our framework, we design Progressive Mapping and Progressive Uncertainty to extract the cross-view features and then extract cross-cloth features on the basis. In this way, the features from the cross-view sub-dataset can first dominate the feature space and relieve the uneven distribution caused by the adverse effect from the cross-cloth sub-dataset. The experiments on our benchmarks show that our framework can effectively improve the recognition performance in CL conditions. Our codes and datasets will be released after accepted.
A Generative Adversarial Framework for Optimizing Image Matting and Harmonization Simultaneously
Aug 13, 2021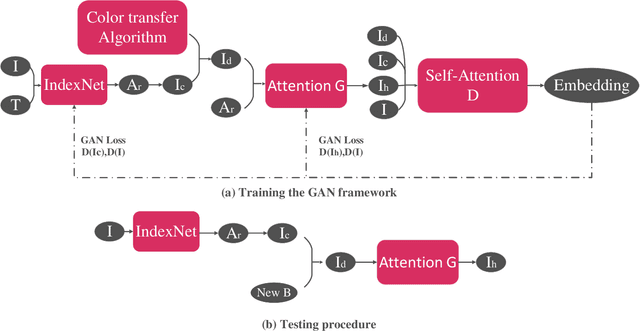
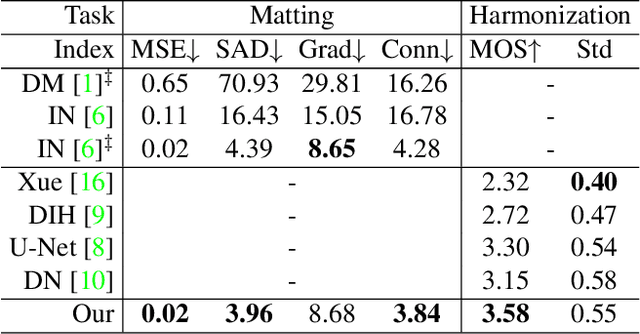
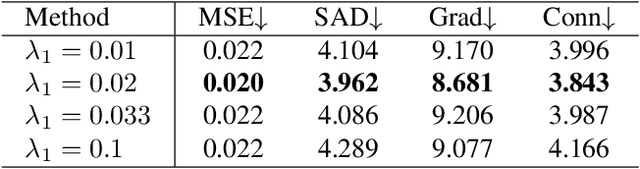
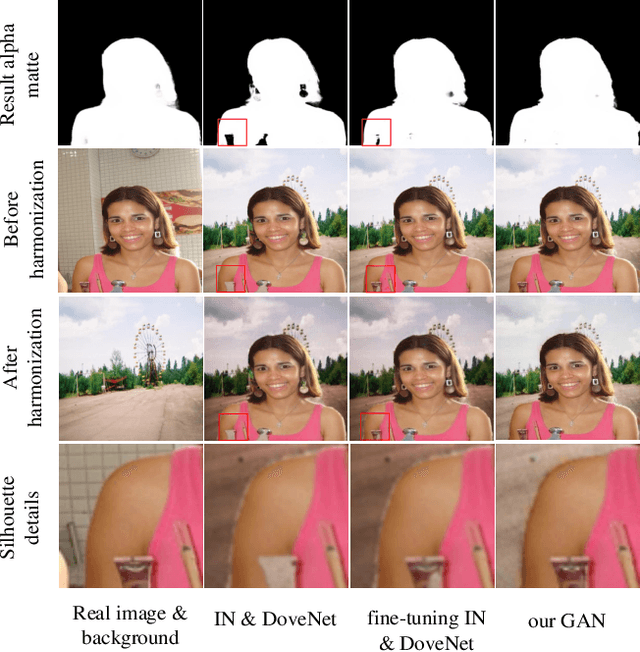
Image matting and image harmonization are two important tasks in image composition. Image matting, aiming to achieve foreground boundary details, and image harmonization, aiming to make the background compatible with the foreground, are both promising yet challenging tasks. Previous works consider optimizing these two tasks separately, which may lead to a sub-optimal solution. We propose to optimize matting and harmonization simultaneously to get better performance on both the two tasks and achieve more natural results. We propose a new Generative Adversarial (GAN) framework which optimizing the matting network and the harmonization network based on a self-attention discriminator. The discriminator is required to distinguish the natural images from different types of fake synthesis images. Extensive experiments on our constructed dataset demonstrate the effectiveness of our proposed method. Our dataset and dataset generating pipeline can be found in \url{https://git.io/HaMaGAN}
* Extension for accepted ICIP 2021