 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVSMask3D: Hard Visual Prompting with Camera Pose Interpolation for 3D Open Vocabulary Instance Segmentation
Apr 20, 2025Vision-language models (VLMs) have demonstrated impressive zero-shot transfer capabilities in image-level visual perception tasks. However, they fall short in 3D instance-level segmentation tasks that require accurate localization and recognition of individual objects. To bridge this gap, we introduce a novel 3D Gaussian Splatting based hard visual prompting approach that leverages camera interpolation to generate diverse viewpoints around target objects without any 2D-3D optimization or fine-tuning. Our method simulates realistic 3D perspectives, effectively augmenting existing hard visual prompts by enforcing geometric consistency across viewpoints. This training-free strategy seamlessly integrates with prior hard visual prompts, enriching object-descriptive features and enabling VLMs to achieve more robust and accurate 3D instance segmentation in diverse 3D scenes.
Road Grip Uncertainty Estimation Through Surface State Segmentation
Apr 11, 2025Slippery road conditions pose significant challenges for autonomous driving. Beyond predicting road grip, it is crucial to estimate its uncertainty reliably to ensure safe vehicle control. In this work, we benchmark several uncertainty prediction methods to assess their effectiveness for grip uncertainty estimation. Additionally, we propose a novel approach that leverages road surface state segmentation to predict grip uncertainty. Our method estimates a pixel-wise grip probability distribution based on inferred road surface conditions. Experimental results indicate that the proposed approach enhances the robustness of grip uncertainty prediction.
A Dataset for Semantic Segmentation in the Presence of Unknowns
Mar 28, 2025Before deployment in the real-world deep neural networks require thorough evaluation of how they handle both knowns, inputs represented in the training data, and unknowns (anomalies). This is especially important for scene understanding tasks with safety critical applications, such as in autonomous driving. Existing datasets allow evaluation of only knowns or unknowns - but not both, which is required to establish "in the wild" suitability of deep neural network models. To bridge this gap, we propose a novel anomaly segmentation dataset, ISSU, that features a diverse set of anomaly inputs from cluttered real-world environments. The dataset is twice larger than existing anomaly segmentation datasets, and provides a training, validation and test set for controlled in-domain evaluation. The test set consists of a static and temporal part, with the latter comprised of videos. The dataset provides annotations for both closed-set (knowns) and anomalies, enabling closed-set and open-set evaluation. The dataset covers diverse conditions, such as domain and cross-sensor shift, illumination variation and allows ablation of anomaly detection methods with respect to these variations. Evaluation results of current state-of-the-art methods confirm the need for improvements especially in domain-generalization, small and large object segmentation.
AGS-Mesh: Adaptive Gaussian Splatting and Meshing with Geometric Priors for Indoor Room Reconstruction Using Smartphones
Nov 28, 2024Geometric priors are often used to enhance 3D reconstruction. With many smartphones featuring low-resolution depth sensors and the prevalence of off-the-shelf monocular geometry estimators, incorporating geometric priors as regularization signals has become common in 3D vision tasks. However, the accuracy of depth estimates from mobile devices is typically poor for highly detailed geometry, and monocular estimators often suffer from poor multi-view consistency and precision. In this work, we propose an approach for joint surface depth and normal refinement of Gaussian Splatting methods for accurate 3D reconstruction of indoor scenes. We develop supervision strategies that adaptively filters low-quality depth and normal estimates by comparing the consistency of the priors during optimization. We mitigate regularization in regions where prior estimates have high uncertainty or ambiguities. Our filtering strategy and optimization design demonstrate significant improvements in both mesh estimation and novel-view synthesis for both 3D and 2D Gaussian Splatting-based methods on challenging indoor room datasets. Furthermore, we explore the use of alternative meshing strategies for finer geometry extraction. We develop a scale-aware meshing strategy inspired by TSDF and octree-based isosurface extraction, which recovers finer details from Gaussian models compared to other commonly used open-source meshing tools. Our code is released in https://xuqianren.github.io/ags_mesh_website/.
Medical Image Segmentation with SAM-generated Annotations
Sep 30, 2024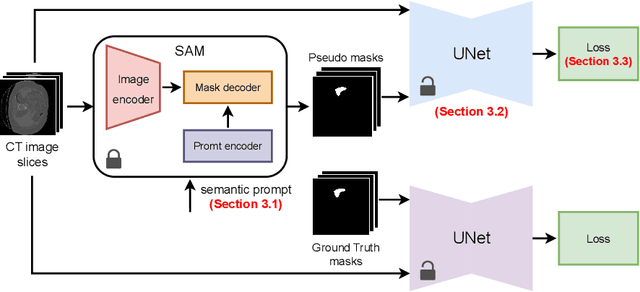

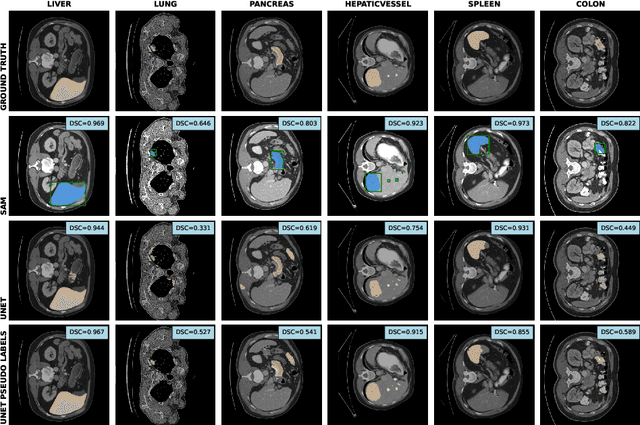
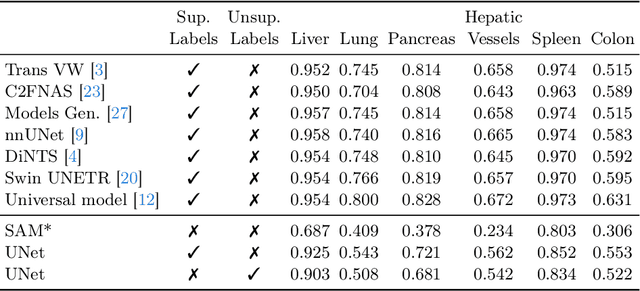
The field of medical image segmentation is hindered by the scarcity of large, publicly available annotated datasets. Not all datasets are made public for privacy reasons, and creating annotations for a large dataset is time-consuming and expensive, as it requires specialized expertise to accurately identify regions of interest (ROIs) within the images. To address these challenges, we evaluate the performance of the Segment Anything Model (SAM) as an annotation tool for medical data by using it to produce so-called "pseudo labels" on the Medical Segmentation Decathlon (MSD) computed tomography (CT) tasks. The pseudo labels are then used in place of ground truth labels to train a UNet model in a weakly-supervised manner. We experiment with different prompt types on SAM and find that the bounding box prompt is a simple yet effective method for generating pseudo labels. This method allows us to develop a weakly-supervised model that performs comparably to a fully supervised model.
Differentiable Product Quantization for Memory Efficient Camera Relocalization
Jul 23, 2024



Camera relocalization relies on 3D models of the scene with a large memory footprint that is incompatible with the memory budget of several applications. One solution to reduce the scene memory size is map compression by removing certain 3D points and descriptor quantization. This achieves high compression but leads to performance drop due to information loss. To address the memory performance trade-off, we train a light-weight scene-specific auto-encoder network that performs descriptor quantization-dequantization in an end-to-end differentiable manner updating both product quantization centroids and network parameters through back-propagation. In addition to optimizing the network for descriptor reconstruction, we encourage it to preserve the descriptor-matching performance with margin-based metric loss functions. Results show that for a local descriptor memory of only 1MB, the synergistic combination of the proposed network and map compression achieves the best performance on the Aachen Day-Night compared to existing compression methods.
Dense Road Surface Grip Map Prediction from Multimodal Image Data
Apr 26, 2024



Slippery road weather conditions are prevalent in many regions and cause a regular risk for traffic. Still, there has been less research on how autonomous vehicles could detect slippery driving conditions on the road to drive safely. In this work, we propose a method to predict a dense grip map from the area in front of the car, based on postprocessed multimodal sensor data. We trained a convolutional neural network to predict pixelwise grip values from fused RGB camera, thermal camera, and LiDAR reflectance images, based on weakly supervised ground truth from an optical road weather sensor. The experiments show that it is possible to predict dense grip values with good accuracy from the used data modalities as the produced grip map follows both ground truth measurements and local weather conditions, such as snowy areas on the road. The model using only the RGB camera or LiDAR reflectance modality provided good baseline results for grip prediction accuracy while using models fusing the RGB camera, thermal camera, and LiDAR modalities improved the grip predictions significantly.
ECLAIR: A High-Fidelity Aerial LiDAR Dataset for Semantic Segmentation
Apr 16, 2024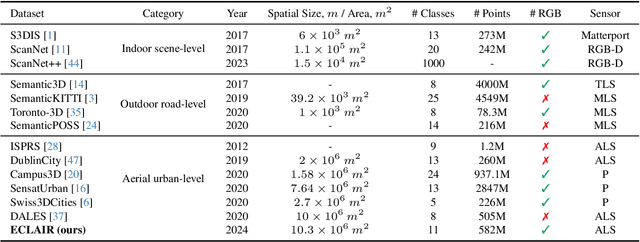
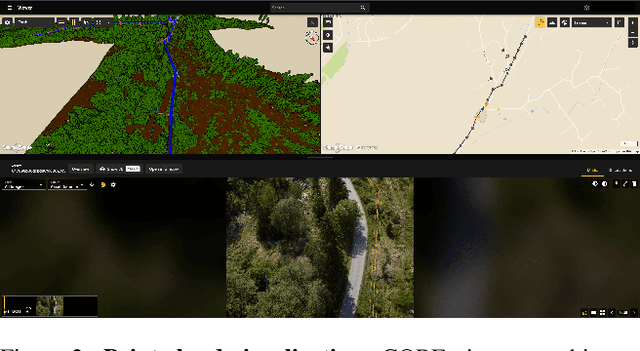

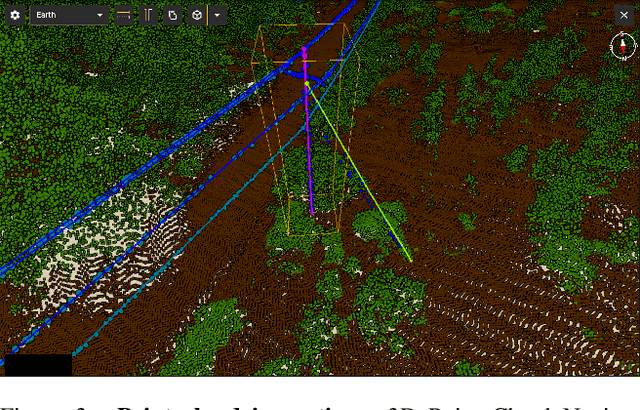
We introduce ECLAIR (Extended Classification of Lidar for AI Recognition), a new outdoor large-scale aerial LiDAR dataset designed specifically for advancing research in point cloud semantic segmentation. As the most extensive and diverse collection of its kind to date, the dataset covers a total area of 10$km^2$ with close to 600 million points and features eleven distinct object categories. To guarantee the dataset's quality and utility, we have thoroughly curated the point labels through an internal team of experts, ensuring accuracy and consistency in semantic labeling. The dataset is engineered to move forward the fields of 3D urban modeling, scene understanding, and utility infrastructure management by presenting new challenges and potential applications. As a benchmark, we report qualitative and quantitative analysis of a voxel-based point cloud segmentation approach based on the Minkowski Engine.
DN-Splatter: Depth and Normal Priors for Gaussian Splatting and Meshing
Mar 26, 2024



3D Gaussian splatting, a novel differentiable rendering technique, has achieved state-of-the-art novel view synthesis results with high rendering speeds and relatively low training times. However, its performance on scenes commonly seen in indoor datasets is poor due to the lack of geometric constraints during optimization. We extend 3D Gaussian splatting with depth and normal cues to tackle challenging indoor datasets and showcase techniques for efficient mesh extraction, an important downstream application. Specifically, we regularize the optimization procedure with depth information, enforce local smoothness of nearby Gaussians, and use the geometry of the 3D Gaussians supervised by normal cues to achieve better alignment with the true scene geometry. We improve depth estimation and novel view synthesis results over baselines and show how this simple yet effective regularization technique can be used to directly extract meshes from the Gaussian representation yielding more physically accurate reconstructions on indoor scenes. Our code will be released in https://github.com/maturk/dn-splatter.
HSCNet++: Hierarchical Scene Coordinate Classification and Regression for Visual Localization with Transformer
May 05, 2023Visual localization is critical to many applications in computer vision and robotics. To address single-image RGB localization, state-of-the-art feature-based methods match local descriptors between a query image and a pre-built 3D model. Recently, deep neural networks have been exploited to regress the mapping between raw pixels and 3D coordinates in the scene, and thus the matching is implicitly performed by the forward pass through the network. However, in a large and ambiguous environment, learning such a regression task directly can be difficult for a single network. In this work, we present a new hierarchical scene coordinate network to predict pixel scene coordinates in a coarse-to-fine manner from a single RGB image. The proposed method, which is an extension of HSCNet, allows us to train compact models which scale robustly to large environments. It sets a new state-of-the-art for single-image localization on the 7-Scenes, 12 Scenes, Cambridge Landmarks datasets, and the combined indoor scenes.