 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultispectral airborne laser scanning for tree species classification: a benchmark of machine learning and deep learning algorithms
Apr 19, 2025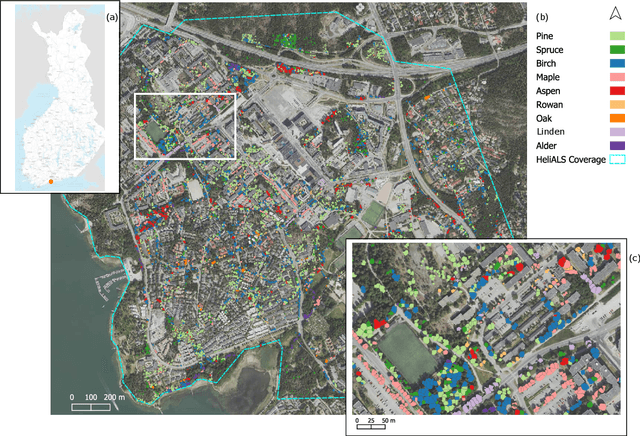


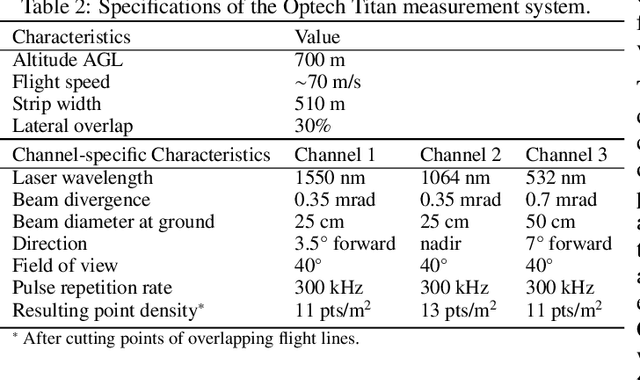
Climate-smart and biodiversity-preserving forestry demands precise information on forest resources, extending to the individual tree level. Multispectral airborne laser scanning (ALS) has shown promise in automated point cloud processing and tree segmentation, but challenges remain in identifying rare tree species and leveraging deep learning techniques. This study addresses these gaps by conducting a comprehensive benchmark of machine learning and deep learning methods for tree species classification. For the study, we collected high-density multispectral ALS data (>1000 pts/m$^2$) at three wavelengths using the FGI-developed HeliALS system, complemented by existing Optech Titan data (35 pts/m$^2$), to evaluate the species classification accuracy of various algorithms in a test site located in Southern Finland. Based on 5261 test segments, our findings demonstrate that point-based deep learning methods, particularly a point transformer model, outperformed traditional machine learning and image-based deep learning approaches on high-density multispectral point clouds. For the high-density ALS dataset, a point transformer model provided the best performance reaching an overall (macro-average) accuracy of 87.9% (74.5%) with a training set of 1065 segments and 92.0% (85.1%) with 5000 training segments. The best image-based deep learning method, DetailView, reached an overall (macro-average) accuracy of 84.3% (63.9%), whereas a random forest (RF) classifier achieved an overall (macro-average) accuracy of 83.2% (61.3%). Importantly, the overall classification accuracy of the point transformer model on the HeliALS data increased from 73.0% with no spectral information to 84.7% with single-channel reflectance, and to 87.9% with spectral information of all the three channels.
Dense Road Surface Grip Map Prediction from Multimodal Image Data
Apr 26, 2024



Slippery road weather conditions are prevalent in many regions and cause a regular risk for traffic. Still, there has been less research on how autonomous vehicles could detect slippery driving conditions on the road to drive safely. In this work, we propose a method to predict a dense grip map from the area in front of the car, based on postprocessed multimodal sensor data. We trained a convolutional neural network to predict pixelwise grip values from fused RGB camera, thermal camera, and LiDAR reflectance images, based on weakly supervised ground truth from an optical road weather sensor. The experiments show that it is possible to predict dense grip values with good accuracy from the used data modalities as the produced grip map follows both ground truth measurements and local weather conditions, such as snowy areas on the road. The model using only the RGB camera or LiDAR reflectance modality provided good baseline results for grip prediction accuracy while using models fusing the RGB camera, thermal camera, and LiDAR modalities improved the grip predictions significantly.
Towards High-Definition Maps: a Framework Leveraging Semantic Segmentation to Improve NDT Map Compression and Descriptivity
Jan 10, 2023



High-Definition (HD) maps are needed for robust navigation of autonomous vehicles, limited by the on-board storage capacity. To solve this, we propose a novel framework, Environment-Aware Normal Distributions Transform (EA-NDT), that significantly improves compression of standard NDT map representation. The compressed representation of EA-NDT is based on semantic-aided clustering of point clouds resulting in more optimal cells compared to grid cells of standard NDT. To evaluate EA-NDT, we present an open-source implementation that extracts planar and cylindrical primitive features from a point cloud and further divides them into smaller cells to represent the data as an EA-NDT HD map. We collected an open suburban environment dataset and evaluated EA-NDT HD map representation against the standard NDT representation. Compared to the standard NDT, EA-NDT achieved consistently at least 1.5x higher map compression while maintaining the same descriptive capability. Moreover, we showed that EA-NDT is capable of producing maps with significantly higher descriptivity score when using the same number of cells than the standard NDT.
Leveraging Road Area Semantic Segmentation with Auxiliary Steering Task
Dec 19, 2022Robustness of different pattern recognition methods is one of the key challenges in autonomous driving, especially when driving in the high variety of road environments and weather conditions, such as gravel roads and snowfall. Although one can collect data from these adverse conditions using cars equipped with sensors, it is quite tedious to annotate the data for training. In this work, we address this limitation and propose a CNN-based method that can leverage the steering wheel angle information to improve the road area semantic segmentation. As the steering wheel angle data can be easily acquired with the associated images, one could improve the accuracy of road area semantic segmentation by collecting data in new road environments without manual data annotation. We demonstrate the effectiveness of the proposed approach on two challenging data sets for autonomous driving and show that when the steering task is used in our segmentation model training, it leads to a 0.1-2.9% gain in the road area mIoU (mean Intersection over Union) compared to the corresponding reference transfer learning model.
* 11 pages, 4 figures (Supplementary material 6 pages, 3 figures). Author's accepted version of the contribution included in proceedings of the 21st International Conference on Image Analysis and Processing (ICIAP), 2022
Multimodal End-to-End Learning for Autonomous Steering in Adverse Road and Weather Conditions
Oct 28, 2020
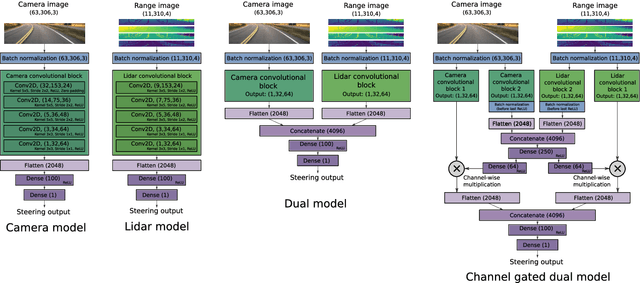
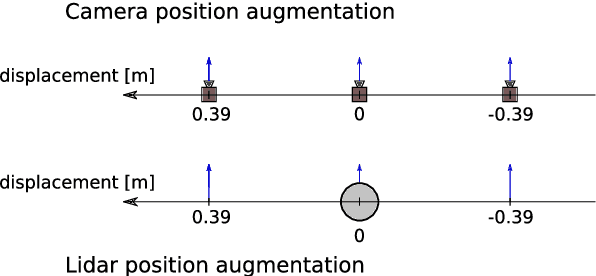

Autonomous driving is challenging in adverse road and weather conditions in which there might not be lane lines, the road might be covered in snow and the visibility might be poor. We extend the previous work on end-to-end learning for autonomous steering to operate in these adverse real-life conditions with multimodal data. We collected 28 hours of driving data in several road and weather conditions and trained convolutional neural networks to predict the car steering wheel angle from front-facing color camera images and lidar range and reflectance data. We compared the CNN model performances based on the different modalities and our results show that the lidar modality improves the performances of different multimodal sensor-fusion models. We also performed on-road tests with different models and they support this observation.