 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeObfuscation Based Privacy Preserving Representations are Recoverable Using Neighborhood Information
Sep 17, 2024



Rapid growth in the popularity of AR/VR/MR applications and cloud-based visual localization systems has given rise to an increased focus on the privacy of user content in the localization process. This privacy concern has been further escalated by the ability of deep neural networks to recover detailed images of a scene from a sparse set of 3D or 2D points and their descriptors - the so-called inversion attacks. Research on privacy-preserving localization has therefore focused on preventing these inversion attacks on both the query image keypoints and the 3D points of the scene map. To this end, several geometry obfuscation techniques that lift points to higher-dimensional spaces, i.e., lines or planes, or that swap coordinates between points % have been proposed. In this paper, we point to a common weakness of these obfuscations that allows to recover approximations of the original point positions under the assumption of known neighborhoods. We further show that these neighborhoods can be computed by learning to identify descriptors that co-occur in neighborhoods. Extensive experiments show that our approach for point recovery is practically applicable to all existing geometric obfuscation schemes. Our results show that these schemes should not be considered privacy-preserving, even though they are claimed to be privacy-preserving. Code will be available at \url{https://github.com/kunalchelani/RecoverPointsNeighborhood}.
Comparative Evaluation of 3D Reconstruction Methods for Object Pose Estimation
Aug 15, 2024Object pose estimation is essential to many industrial applications involving robotic manipulation, navigation, and augmented reality. Current generalizable object pose estimators, i.e., approaches that do not need to be trained per object, rely on accurate 3D models. Predominantly, CAD models are used, which can be hard to obtain in practice. At the same time, it is often possible to acquire images of an object. Naturally, this leads to the question whether 3D models reconstructed from images are sufficient to facilitate accurate object pose estimation. We aim to answer this question by proposing a novel benchmark for measuring the impact of 3D reconstruction quality on pose estimation accuracy. Our benchmark provides calibrated images for object reconstruction registered with the test images of the YCB-V dataset for pose evaluation under the BOP benchmark format. Detailed experiments with multiple state-of-the-art 3D reconstruction and object pose estimation approaches show that the geometry produced by modern reconstruction methods is often sufficient for accurate pose estimation. Our experiments lead to interesting observations: (1) Standard metrics for measuring 3D reconstruction quality are not necessarily indicative of pose estimation accuracy, which shows the need for dedicated benchmarks such as ours. (2) Classical, non-learning-based approaches can perform on par with modern learning-based reconstruction techniques and can even offer a better reconstruction time-pose accuracy tradeoff. (3) There is still a sizable gap between performance with reconstructed and with CAD models. To foster research on closing this gap, our benchmark is publicly available at https://github.com/VarunBurde/reconstruction_pose_benchmark}.
Differentiable Product Quantization for Memory Efficient Camera Relocalization
Jul 23, 2024



Camera relocalization relies on 3D models of the scene with a large memory footprint that is incompatible with the memory budget of several applications. One solution to reduce the scene memory size is map compression by removing certain 3D points and descriptor quantization. This achieves high compression but leads to performance drop due to information loss. To address the memory performance trade-off, we train a light-weight scene-specific auto-encoder network that performs descriptor quantization-dequantization in an end-to-end differentiable manner updating both product quantization centroids and network parameters through back-propagation. In addition to optimizing the network for descriptor reconstruction, we encourage it to preserve the descriptor-matching performance with margin-based metric loss functions. Results show that for a local descriptor memory of only 1MB, the synergistic combination of the proposed network and map compression achieves the best performance on the Aachen Day-Night compared to existing compression methods.
Self-Supervised Gaussian Regularization of Deep Classifiers for Mahalanobis-Distance-Based Uncertainty Estimation
May 23, 2023



Recent works show that the data distribution in a network's latent space is useful for estimating classification uncertainty and detecting Out-of-distribution (OOD) samples. To obtain a well-regularized latent space that is conducive for uncertainty estimation, existing methods bring in significant changes to model architectures and training procedures. In this paper, we present a lightweight, fast, and high-performance regularization method for Mahalanobis distance-based uncertainty prediction, and that requires minimal changes to the network's architecture. To derive Gaussian latent representation favourable for Mahalanobis Distance calculation, we introduce a self-supervised representation learning method that separates in-class representations into multiple Gaussians. Classes with non-Gaussian representations are automatically identified and dynamically clustered into multiple new classes that are approximately Gaussian. Evaluation on standard OOD benchmarks shows that our method achieves state-of-the-art results on OOD detection with minimal inference time, and is very competitive on predictive probability calibration. Finally, we show the applicability of our method to a real-life computer vision use case on microorganism classification.
Object-Guided Day-Night Visual Localization in Urban Scenes
Feb 09, 2022
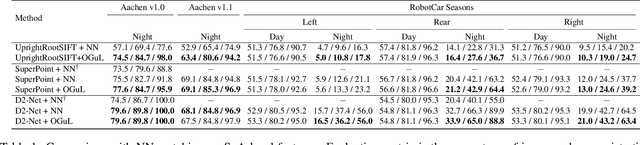
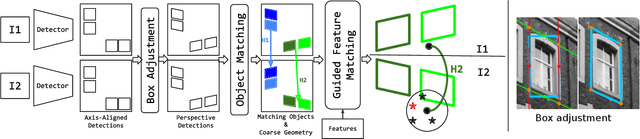

We introduce Object-Guided Localization (OGuL) based on a novel method of local-feature matching. Direct matching of local features is sensitive to significant changes in illumination. In contrast, object detection often survives severe changes in lighting conditions. The proposed method first detects semantic objects and establishes correspondences of those objects between images. Object correspondences provide local coarse alignment of the images in the form of a planar homography. These homographies are consequently used to guide the matching of local features. Experiments on standard urban localization datasets (Aachen, Extended-CMU-Season, RobotCar-Season) show that OGuL significantly improves localization results with as simple local features as SIFT, and its performance competes with the state-of-the-art CNN-based methods trained for day-to-night localization.
Image-Based Place Recognition on Bucolic Environment Across Seasons From Semantic Edge Description
Oct 28, 2019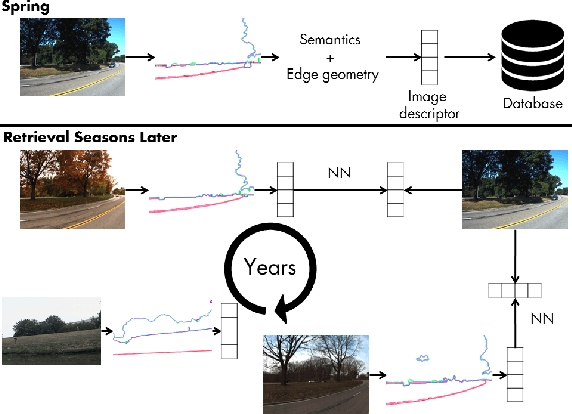



Most of the research effort on image-based place recognition is designed for urban environments. In bucolic environments such as natural scenes with low texture and little semantic content, the main challenge is to handle the variations in visual appearance across time such as illumination, weather, vegetation state or viewpoints. The nature of the variations is different and this leads to a different approach to describing a bucolic scene. We introduce a global image descriptor computed from its semantic and topological information. It is built from the wavelet transforms of the image semantic edges. Matching two images is then equivalent to matching their semantic edge descriptors. We show that this method reaches state-of-the-art image retrieval performance on two multi-season environment-monitoring datasets: the CMU-Seasons and the Symphony Lake dataset. It also generalises to urban scenes on which it is on par with the current baselines NetVLAD and DELF.
ELF: Embedded Localisation of Features in pre-trained CNN
Jul 07, 2019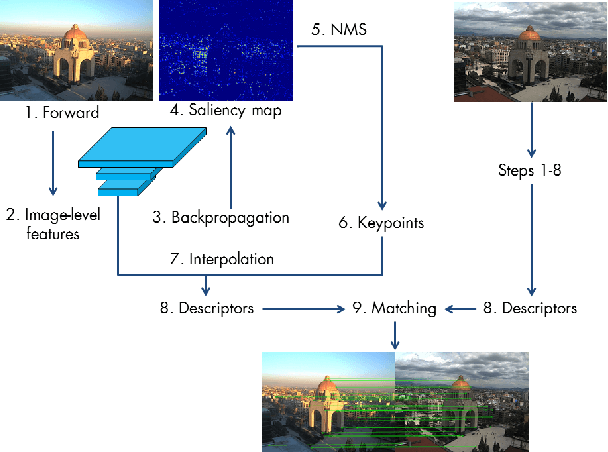
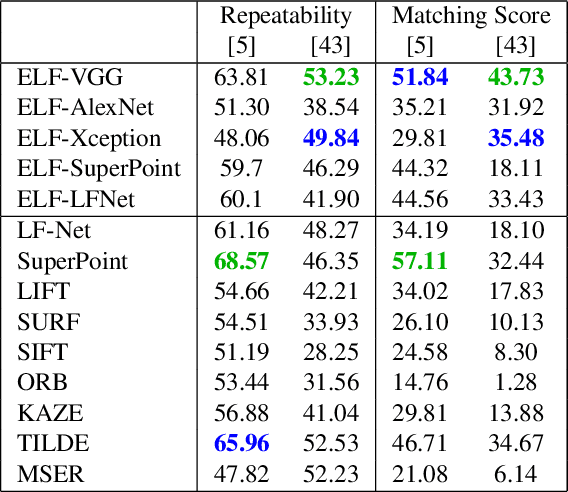

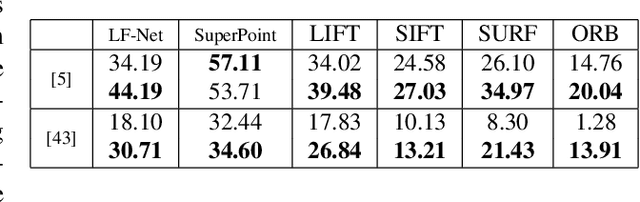
This paper introduces a novel feature detector based only on information embedded inside a CNN trained on standard tasks (e.g. classification). While previous works already show that the features of a trained CNN are suitable descriptors, we show here how to extract the feature locations from the network to build a detector. This information is computed from the gradient of the feature map with respect to the input image. This provides a saliency map with local maxima on relevant keypoint locations. Contrary to recent CNN-based detectors, this method requires neither supervised training nor finetuning. We evaluate how repeatable and how matchable the detected keypoints are with the repeatability and matching scores. Matchability is measured with a simple descriptor introduced for the sake of the evaluation. This novel detector reaches similar performances on the standard evaluation HPatches dataset, as well as comparable robustness against illumination and viewpoint changes on Webcam and photo-tourism images. These results show that a CNN trained on a standard task embeds feature location information that is as relevant as when the CNN is specifically trained for feature detection.
Semantic Nearest Neighbor Fields Monocular Edge Visual-Odometry
Apr 01, 2019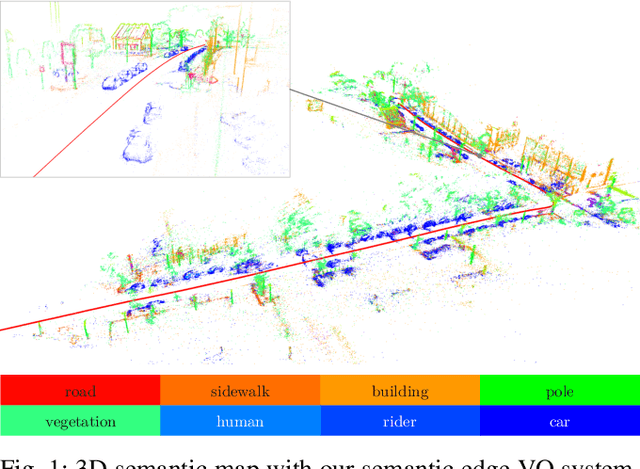
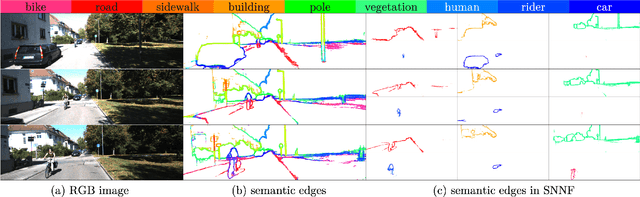
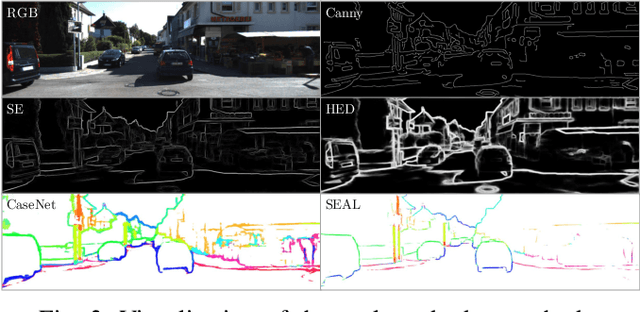
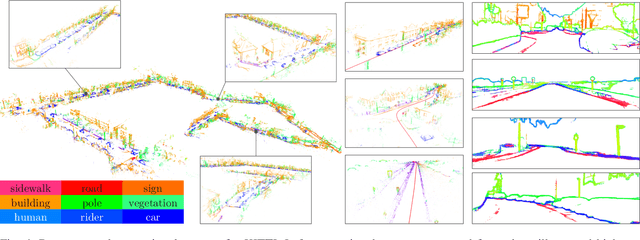
Recent advances in deep learning for edge detection and segmentation opens up a new path for semantic-edge-based ego-motion estimation. In this work, we propose a robust monocular visual odometry (VO) framework using category-aware semantic edges. It can reconstruct large-scale semantic maps in challenging outdoor environments. The core of our approach is a semantic nearest neighbor field that facilitates a robust data association of edges across frames using semantics. This significantly enlarges the convergence radius during tracking phases. The proposed edge registration method can be easily integrated into direct VO frameworks to estimate photometrically, geometrically, and semantically consistent camera motions. Different types of edges are evaluated and extensive experiments demonstrate that our proposed system outperforms state-of-art indirect, direct, and semantic monocular VO systems.
Deep Representation Learning for Domain Adaptation of Semantic Image Segmentation
May 10, 2018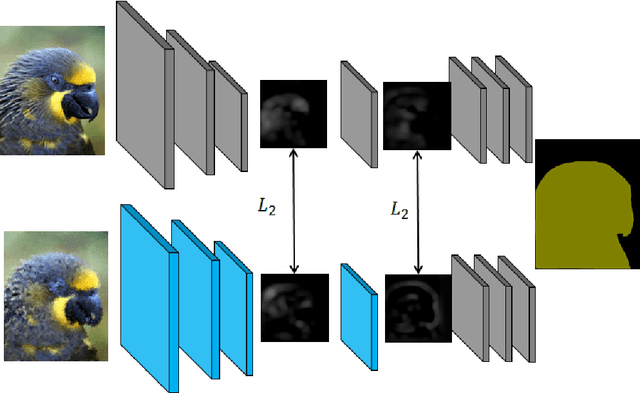
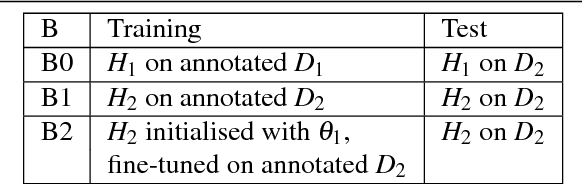


Deep Convolutional Neural Networks have pushed the state-of-the art for semantic segmentation provided that a large amount of images together with pixel-wise annotations is available. Data collection is expensive and a solution to alleviate it is to use transfer learning. This reduces the amount of annotated data required for the network training but it does not get rid of this heavy processing step. We propose a method of transfer learning without annotations on the target task for datasets with redundant content and distinct pixel distributions. Our method takes advantage of the approximate content alignment of the images between two datasets when the approximation error prevents the reuse of annotation from one dataset to another. Given the annotations for only one dataset, we train a first network in a supervised manner. This network autonomously learns to generate deep data representations relevant to the semantic segmentation. Then the images in the new dataset, we train a new network to generate a deep data representation that matches the one from the first network on the previous dataset. The training consists in a regression between feature maps and does not require any annotations on the new dataset. We show that this method reaches performances similar to a classic transfer learning on the PASCAL VOC dataset with synthetic transformations.