 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Representation Learning for Domain Adaptation of Semantic Image Segmentation
Paper and Code
May 10, 2018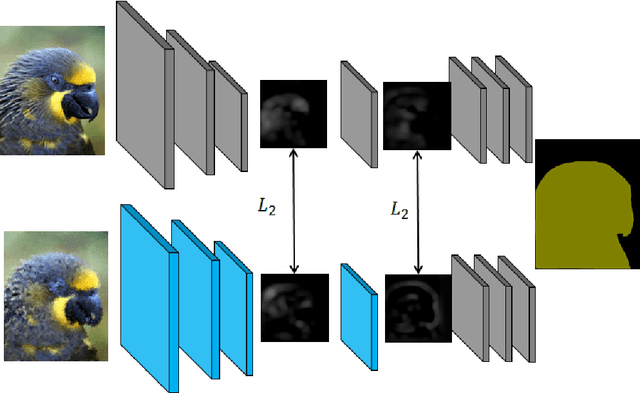


Deep Convolutional Neural Networks have pushed the state-of-the art for semantic segmentation provided that a large amount of images together with pixel-wise annotations is available. Data collection is expensive and a solution to alleviate it is to use transfer learning. This reduces the amount of annotated data required for the network training but it does not get rid of this heavy processing step. We propose a method of transfer learning without annotations on the target task for datasets with redundant content and distinct pixel distributions. Our method takes advantage of the approximate content alignment of the images between two datasets when the approximation error prevents the reuse of annotation from one dataset to another. Given the annotations for only one dataset, we train a first network in a supervised manner. This network autonomously learns to generate deep data representations relevant to the semantic segmentation. Then the images in the new dataset, we train a new network to generate a deep data representation that matches the one from the first network on the previous dataset. The training consists in a regression between feature maps and does not require any annotations on the new dataset. We show that this method reaches performances similar to a classic transfer learning on the PASCAL VOC dataset with synthetic transformations.