 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPIC: Amortized Physics-Informed Calibration using Neural Processes
Jun 02, 2026Physics models are inherently imperfect due to misspecified or missing mechanisms, resulting in systematic discrepancies between model predictions and real-world observations. The Kennedy-O'Hagan (KOH) framework addresses this issue through explicit discrepancy modeling. However, its non-amortized, per-instance formulation limits scalability across families of related systems. We introduce Amortized Physics-Informed Calibration (APIC), a population-level extension of KOH that leverages Neural Processes to perform scalable Bayesian inference across realizations. Our framework employs a two-branch latent architecture to disentangle instance-specific physical parameters from shared, state-dependent structural discrepancies. By integrating differentiable physics into an amortized inference backbone, APIC enables rapid calibration of unseen realizations from sparse observations while quantifying uncertainty. Experiments on the damped spring oscillator, the Lotka-Volterra system, and the advection-diffusion PDE with misspecified physics demonstrate improved parameter recovery and consistent identification of the systemic discrepancy structure compared to other calibration approaches.
Uncertainty-aware Physics-informed Neural Networks for Robust CARS-to-Raman Signal Reconstruction
Nov 17, 2025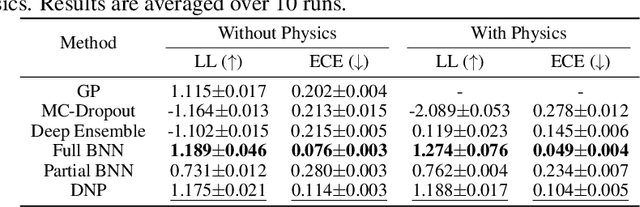
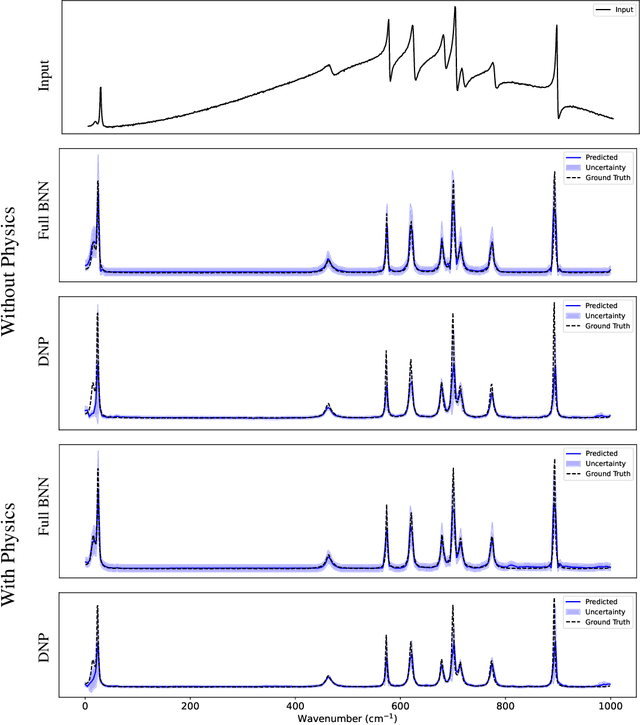
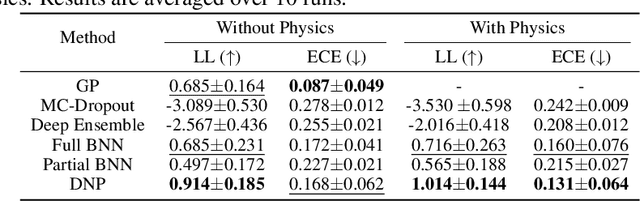
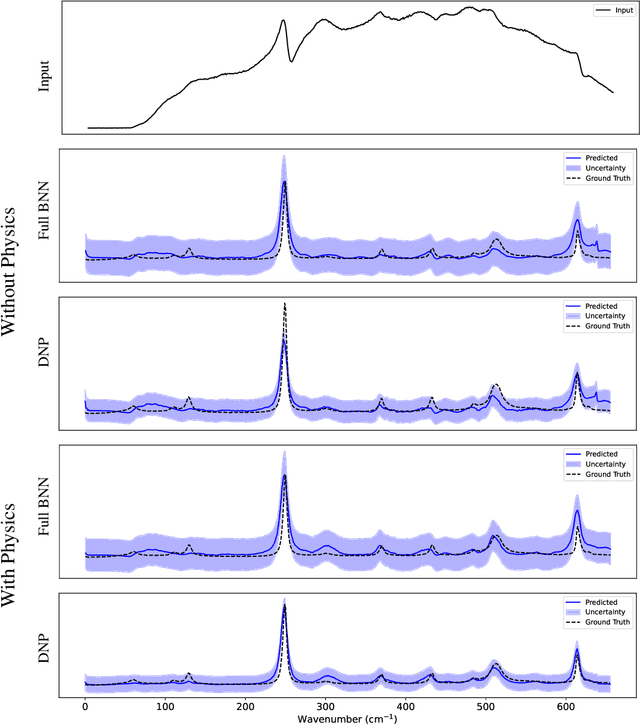
Coherent anti-Stokes Raman scattering (CARS) spectroscopy is a powerful and rapid technique widely used in medicine, material science, and chemical analyses. However, its effectiveness is hindered by the presence of a non-resonant background that interferes with and distorts the true Raman signal. Deep learning methods have been employed to reconstruct the true Raman spectrum from measured CARS data using labeled datasets. A more recent development integrates the domain knowledge of Kramers-Kronig relationships and smoothness constraints in the form of physics-informed loss functions. However, these deterministic models lack the ability to quantify uncertainty, an essential feature for reliable deployment in high-stakes scientific and biomedical applications. In this work, we evaluate and compare various uncertainty quantification (UQ) techniques within the context of CARS-to-Raman signal reconstruction. Furthermore, we demonstrate that incorporating physics-informed constraints into these models improves their calibration, offering a promising path toward more trustworthy CARS data analysis.
Distance-informed Neural Processes
Aug 26, 2025We propose the Distance-informed Neural Process (DNP), a novel variant of Neural Processes that improves uncertainty estimation by combining global and distance-aware local latent structures. Standard Neural Processes (NPs) often rely on a global latent variable and struggle with uncertainty calibration and capturing local data dependencies. DNP addresses these limitations by introducing a global latent variable to model task-level variations and a local latent variable to capture input similarity within a distance-preserving latent space. This is achieved through bi-Lipschitz regularization, which bounds distortions in input relationships and encourages the preservation of relative distances in the latent space. This modeling approach allows DNP to produce better-calibrated uncertainty estimates and more effectively distinguish in- from out-of-distribution data. Empirical results demonstrate that DNP achieves strong predictive performance and improved uncertainty calibration across regression and classification tasks.
Probabilistic Embeddings for Frozen Vision-Language Models: Uncertainty Quantification with Gaussian Process Latent Variable Models
May 08, 2025Vision-Language Models (VLMs) learn joint representations by mapping images and text into a shared latent space. However, recent research highlights that deterministic embeddings from standard VLMs often struggle to capture the uncertainties arising from the ambiguities in visual and textual descriptions and the multiple possible correspondences between images and texts. Existing approaches tackle this by learning probabilistic embeddings during VLM training, which demands large datasets and does not leverage the powerful representations already learned by large-scale VLMs like CLIP. In this paper, we propose GroVE, a post-hoc approach to obtaining probabilistic embeddings from frozen VLMs. GroVE builds on Gaussian Process Latent Variable Model (GPLVM) to learn a shared low-dimensional latent space where image and text inputs are mapped to a unified representation, optimized through single-modal embedding reconstruction and cross-modal alignment objectives. Once trained, the Gaussian Process model generates uncertainty-aware probabilistic embeddings. Evaluation shows that GroVE achieves state-of-the-art uncertainty calibration across multiple downstream tasks, including cross-modal retrieval, visual question answering, and active learning.
Integrating Visual and Semantic Similarity Using Hierarchies for Image Retrieval
Aug 16, 2023
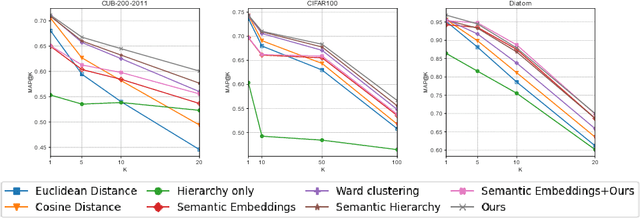
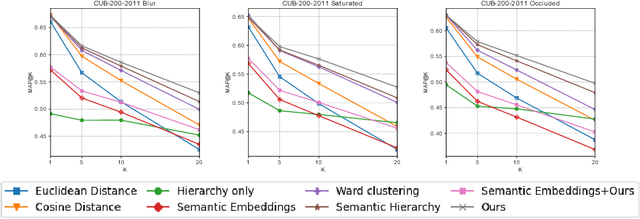
Most of the research in content-based image retrieval (CBIR) focus on developing robust feature representations that can effectively retrieve instances from a database of images that are visually similar to a query. However, the retrieved images sometimes contain results that are not semantically related to the query. To address this, we propose a method for CBIR that captures both visual and semantic similarity using a visual hierarchy. The hierarchy is constructed by merging classes with overlapping features in the latent space of a deep neural network trained for classification, assuming that overlapping classes share high visual and semantic similarities. Finally, the constructed hierarchy is integrated into the distance calculation metric for similarity search. Experiments on standard datasets: CUB-200-2011 and CIFAR100, and a real-life use case using diatom microscopy images show that our method achieves superior performance compared to the existing methods on image retrieval.
Self-Supervised Gaussian Regularization of Deep Classifiers for Mahalanobis-Distance-Based Uncertainty Estimation
May 23, 2023



Recent works show that the data distribution in a network's latent space is useful for estimating classification uncertainty and detecting Out-of-distribution (OOD) samples. To obtain a well-regularized latent space that is conducive for uncertainty estimation, existing methods bring in significant changes to model architectures and training procedures. In this paper, we present a lightweight, fast, and high-performance regularization method for Mahalanobis distance-based uncertainty prediction, and that requires minimal changes to the network's architecture. To derive Gaussian latent representation favourable for Mahalanobis Distance calculation, we introduce a self-supervised representation learning method that separates in-class representations into multiple Gaussians. Classes with non-Gaussian representations are automatically identified and dynamically clustered into multiple new classes that are approximately Gaussian. Evaluation on standard OOD benchmarks shows that our method achieves state-of-the-art results on OOD detection with minimal inference time, and is very competitive on predictive probability calibration. Finally, we show the applicability of our method to a real-life computer vision use case on microorganism classification.
Tackling Inter-Class Similarity and Intra-Class Variance for Microscopic Image-based Classification
Sep 24, 2021
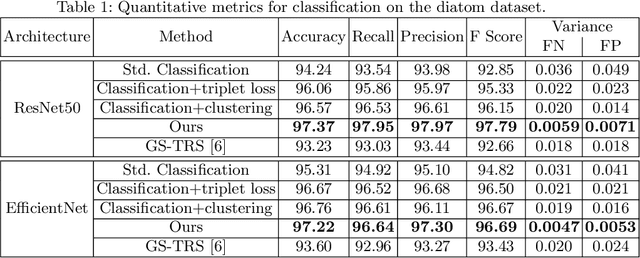

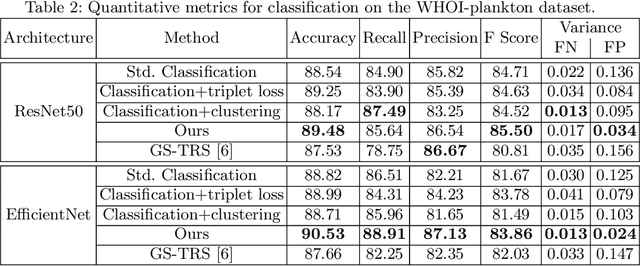
Automatic classification of aquatic microorganisms is based on the morphological features extracted from individual images. The current works on their classification do not consider the inter-class similarity and intra-class variance that causes misclassification. We are particularly interested in the case where variance within a class occurs due to discrete visual changes in microscopic images. In this paper, we propose to account for it by partitioning the classes with high variance based on the visual features. Our algorithm automatically decides the optimal number of sub-classes to be created and consider each of them as a separate class for training. This way, the network learns finer-grained visual features. Our experiments on two databases of freshwater benthic diatoms and marine plankton show that our method can outperform the state-of-the-art approaches for classification of these aquatic microorganisms.