 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPAR: Single-Pass Any-Resolution ViT for Open-vocabulary Segmentation
Apr 02, 2026Foundational Vision Transformers (ViTs) have limited effectiveness in tasks requiring fine-grained spatial understanding, due to their fixed pre-training resolution and inherently coarse patch-level representations. These challenges are especially pronounced in dense prediction scenarios, such as open-vocabulary segmentation with ViT-based vision-language models, where high-resolution inputs are essential for accurate pixel-level reasoning. Existing approaches typically process large-resolution images using a sliding-window strategy at the pre-training resolution. While this improves accuracy through finer strides, it comes at a significant computational cost. We introduce SPAR: Single-Pass Any-Resolution ViT, a resolution-agnostic dense feature extractor designed for efficient high-resolution inference. We distill the spatial reasoning capabilities of a finely-strided, sliding-window teacher into a single-pass student using a feature regression loss, without requiring architectural changes or pixel-level supervision. Applied to open-vocabulary segmentation, SPAR improves single-pass baselines by up to 10.5 mIoU and even surpasses the teacher, demonstrating effectiveness in efficient, high-resolution reasoning. Code: https://github.com/naomikombol/SPAR
ELViS: Efficient Visual Similarity from Local Descriptors that Generalizes Across Domains
Mar 30, 2026Large-scale instance-level training data is scarce, so models are typically trained on domain-specific datasets. Yet in real-world retrieval, they must handle diverse domains, making generalization to unseen data critical. We introduce ELViS, an image-to-image similarity model that generalizes effectively to unseen domains. Unlike conventional approaches, our model operates in similarity space rather than representation space, promoting cross-domain transfer. It leverages local descriptor correspondences, refines their similarities through an optimal transport step with data-dependent gains that suppress uninformative descriptors, and aggregates strong correspondences via a voting process into an image-level similarity. This design injects strong inductive biases, yielding a simple, efficient, and interpretable model. To assess generalization, we compile a benchmark of eight datasets spanning landmarks, artworks, products, and multi-domain collections, and evaluate ELViS as a re-ranking method. Our experiments show that ELViS outperforms competing methods by a large margin in out-of-domain scenarios and on average, while requiring only a fraction of their computational cost. Code available at: https://github.com/pavelsuma/ELViS/
Retrieve and Segment: Are a Few Examples Enough to Bridge the Supervision Gap in Open-Vocabulary Segmentation?
Feb 26, 2026Open-vocabulary segmentation (OVS) extends the zero-shot recognition capabilities of vision-language models (VLMs) to pixel-level prediction, enabling segmentation of arbitrary categories specified by text prompts. Despite recent progress, OVS lags behind fully supervised approaches due to two challenges: the coarse image-level supervision used to train VLMs and the semantic ambiguity of natural language. We address these limitations by introducing a few-shot setting that augments textual prompts with a support set of pixel-annotated images. Building on this, we propose a retrieval-augmented test-time adapter that learns a lightweight, per-image classifier by fusing textual and visual support features. Unlike prior methods relying on late, hand-crafted fusion, our approach performs learned, per-query fusion, achieving stronger synergy between modalities. The method supports continually expanding support sets, and applies to fine-grained tasks such as personalized segmentation. Experiments show that we significantly narrow the gap between zero-shot and supervised segmentation while preserving open-vocabulary ability.
Global-Aware Edge Prioritization for Pose Graph Initialization
Feb 25, 2026The pose graph is a core component of Structure-from-Motion (SfM), where images act as nodes and edges encode relative poses. Since geometric verification is expensive, SfM pipelines restrict the pose graph to a sparse set of candidate edges, making initialization critical. Existing methods rely on image retrieval to connect each image to its $k$ nearest neighbors, treating pairs independently and ignoring global consistency. We address this limitation through the concept of edge prioritization, ranking candidate edges by their utility for SfM. Our approach has three components: (1) a GNN trained with SfM-derived supervision to predict globally consistent edge reliability; (2) multi-minimal-spanning-tree-based pose graph construction guided by these ranks; and (3) connectivity-aware score modulation that reinforces weak regions and reduces graph diameter. This globally informed initialization yields more reliable and compact pose graphs, improving reconstruction accuracy in sparse and high-speed settings and outperforming SOTA retrieval methods on ambiguous scenes. The ode and trained models are available at https://github.com/weitong8591/global_edge_prior.
Attention, Please! Revisiting Attentive Probing for Masked Image Modeling
Jun 11, 2025As fine-tuning (FT) becomes increasingly impractical at scale, probing is emerging as the preferred evaluation protocol for self-supervised learning (SSL). Yet, the standard linear probing (LP) fails to adequately reflect the potential of models trained with Masked Image Modeling (MIM), due to the distributed nature of patch tokens. This motivates the need for attentive probing, an alternative that uses attention to selectively aggregate patch-level features. Despite its growing adoption, attentive probing remains under-explored, with existing methods suffering from excessive parameterization and poor computational efficiency. In this work, we revisit attentive probing through the lens of the accuracy-efficiency trade-off. We conduct a systematic study of existing methods, analyzing their mechanisms and benchmarking their performance. We introduce efficient probing (EP), a multi-query cross-attention mechanism that eliminates redundant projections, reduces the number of trainable parameters, and achieves up to a 10$\times$ speed-up over conventional multi-head attention. Despite its simplicity, EP outperforms LP and prior attentive probing approaches across seven benchmarks, generalizes well beyond MIM to diverse pre-training paradigms, produces interpretable attention maps, and achieves strong gains in low-shot and layer-wise settings. Code available at https://github.com/billpsomas/efficient-probing.
A Dataset for Semantic Segmentation in the Presence of Unknowns
Mar 28, 2025Before deployment in the real-world deep neural networks require thorough evaluation of how they handle both knowns, inputs represented in the training data, and unknowns (anomalies). This is especially important for scene understanding tasks with safety critical applications, such as in autonomous driving. Existing datasets allow evaluation of only knowns or unknowns - but not both, which is required to establish "in the wild" suitability of deep neural network models. To bridge this gap, we propose a novel anomaly segmentation dataset, ISSU, that features a diverse set of anomaly inputs from cluttered real-world environments. The dataset is twice larger than existing anomaly segmentation datasets, and provides a training, validation and test set for controlled in-domain evaluation. The test set consists of a static and temporal part, with the latter comprised of videos. The dataset provides annotations for both closed-set (knowns) and anomalies, enabling closed-set and open-set evaluation. The dataset covers diverse conditions, such as domain and cross-sensor shift, illumination variation and allows ablation of anomaly detection methods with respect to these variations. Evaluation results of current state-of-the-art methods confirm the need for improvements especially in domain-generalization, small and large object segmentation.
LOCORE: Image Re-ranking with Long-Context Sequence Modeling
Mar 27, 2025We introduce LOCORE, Long-Context Re-ranker, a model that takes as input local descriptors corresponding to an image query and a list of gallery images and outputs similarity scores between the query and each gallery image. This model is used for image retrieval, where typically a first ranking is performed with an efficient similarity measure, and then a shortlist of top-ranked images is re-ranked based on a more fine-grained similarity measure. Compared to existing methods that perform pair-wise similarity estimation with local descriptors or list-wise re-ranking with global descriptors, LOCORE is the first method to perform list-wise re-ranking with local descriptors. To achieve this, we leverage efficient long-context sequence models to effectively capture the dependencies between query and gallery images at the local-descriptor level. During testing, we process long shortlists with a sliding window strategy that is tailored to overcome the context size limitations of sequence models. Our approach achieves superior performance compared with other re-rankers on established image retrieval benchmarks of landmarks (ROxf and RPar), products (SOP), fashion items (In-Shop), and bird species (CUB-200) while having comparable latency to the pair-wise local descriptor re-rankers.
LPOSS: Label Propagation Over Patches and Pixels for Open-vocabulary Semantic Segmentation
Mar 25, 2025We propose a training-free method for open-vocabulary semantic segmentation using Vision-and-Language Models (VLMs). Our approach enhances the initial per-patch predictions of VLMs through label propagation, which jointly optimizes predictions by incorporating patch-to-patch relationships. Since VLMs are primarily optimized for cross-modal alignment and not for intra-modal similarity, we use a Vision Model (VM) that is observed to better capture these relationships. We address resolution limitations inherent to patch-based encoders by applying label propagation at the pixel level as a refinement step, significantly improving segmentation accuracy near class boundaries. Our method, called LPOSS+, performs inference over the entire image, avoiding window-based processing and thereby capturing contextual interactions across the full image. LPOSS+ achieves state-of-the-art performance among training-free methods, across a diverse set of datasets. Code: https://github.com/vladan-stojnic/LPOSS
ILIAS: Instance-Level Image retrieval At Scale
Feb 17, 2025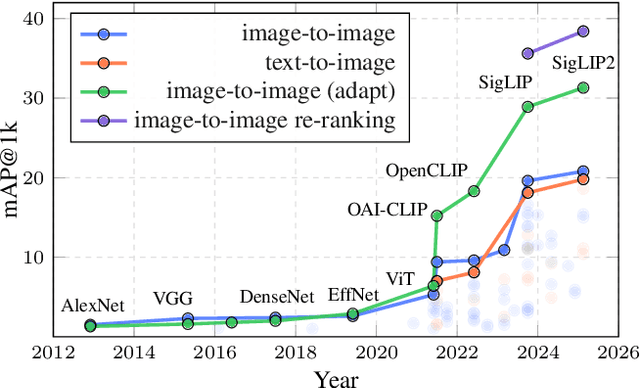
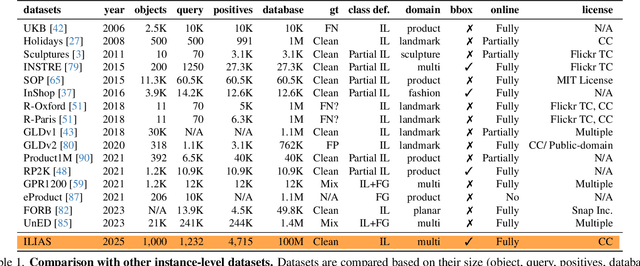

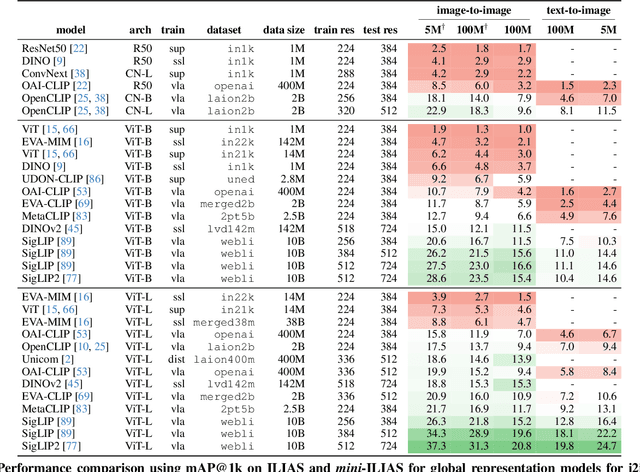
This work introduces ILIAS, a new test dataset for Instance-Level Image retrieval At Scale. It is designed to evaluate the ability of current and future foundation models and retrieval techniques to recognize particular objects. The key benefits over existing datasets include large scale, domain diversity, accurate ground truth, and a performance that is far from saturated. ILIAS includes query and positive images for 1,000 object instances, manually collected to capture challenging conditions and diverse domains. Large-scale retrieval is conducted against 100 million distractor images from YFCC100M. To avoid false negatives without extra annotation effort, we include only query objects confirmed to have emerged after 2014, i.e. the compilation date of YFCC100M. An extensive benchmarking is performed with the following observations: i) models fine-tuned on specific domains, such as landmarks or products, excel in that domain but fail on ILIAS ii) learning a linear adaptation layer using multi-domain class supervision results in performance improvements, especially for vision-language models iii) local descriptors in retrieval re-ranking are still a key ingredient, especially in the presence of severe background clutter iv) the text-to-image performance of the vision-language foundation models is surprisingly close to the corresponding image-to-image case. website: https://vrg.fel.cvut.cz/ilias/
Three Things to Know about Deep Metric Learning
Dec 17, 2024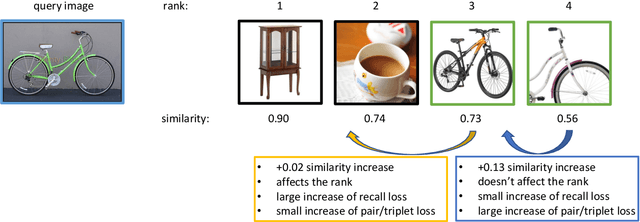
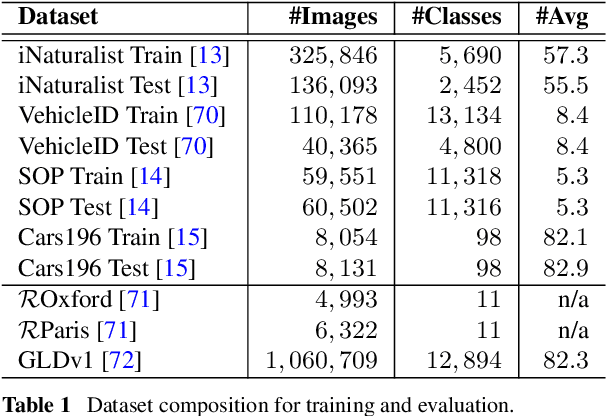
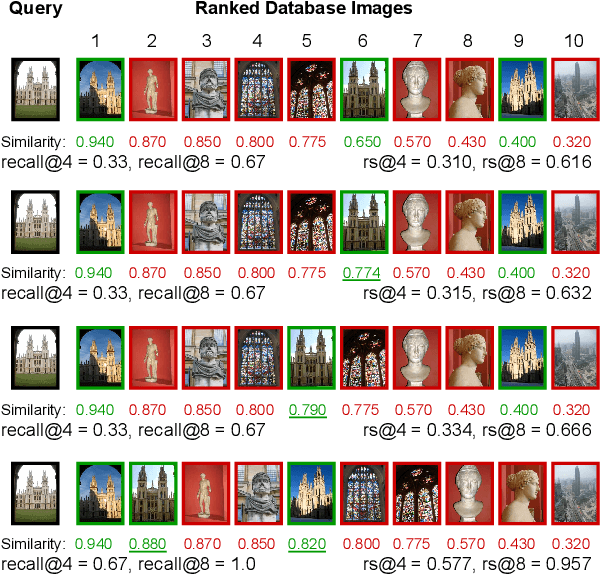

This paper addresses supervised deep metric learning for open-set image retrieval, focusing on three key aspects: the loss function, mixup regularization, and model initialization. In deep metric learning, optimizing the retrieval evaluation metric, recall@k, via gradient descent is desirable but challenging due to its non-differentiable nature. To overcome this, we propose a differentiable surrogate loss that is computed on large batches, nearly equivalent to the entire training set. This computationally intensive process is made feasible through an implementation that bypasses the GPU memory limitations. Additionally, we introduce an efficient mixup regularization technique that operates on pairwise scalar similarities, effectively increasing the batch size even further. The training process is further enhanced by initializing the vision encoder using foundational models, which are pre-trained on large-scale datasets. Through a systematic study of these components, we demonstrate that their synergy enables large models to nearly solve popular benchmarks.