 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Image Retrieval for Remote Sensing
Paper and Code

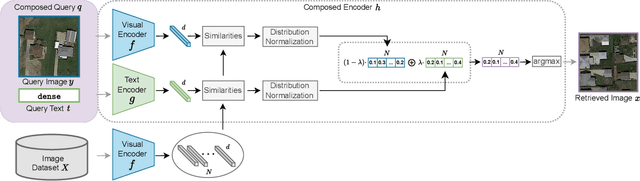


This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir