 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComposed Image Retrieval for Remote Sensing
May 29, 2024
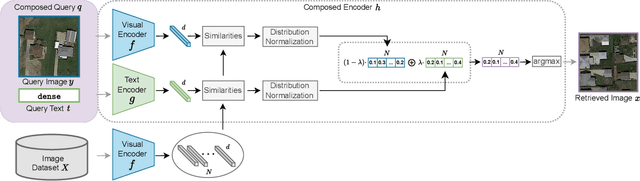


This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
Edge Augmentation for Large-Scale Sketch Recognition without Sketches
Feb 26, 2022



This work addresses scaling up the sketch classification task into a large number of categories. Collecting sketches for training is a slow and tedious process that has so far precluded any attempts to large-scale sketch recognition. We overcome the lack of training sketch data by exploiting labeled collections of natural images that are easier to obtain. To bridge the domain gap we present a novel augmentation technique that is tailored to the task of learning sketch recognition from a training set of natural images. Randomization is introduced in the parameters of edge detection and edge selection. Natural images are translated to a pseudo-novel domain called "randomized Binary Thin Edges" (rBTE), which is used as a training domain instead of natural images. The ability to scale up is demonstrated by training CNN-based sketch recognition of more than 2.5 times larger number of categories than used previously. For this purpose, a dataset of natural images from 874 categories is constructed by combining a number of popular computer vision datasets. The categories are selected to be suitable for sketch recognition. To estimate the performance, a subset of 393 categories with sketches is also collected.
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022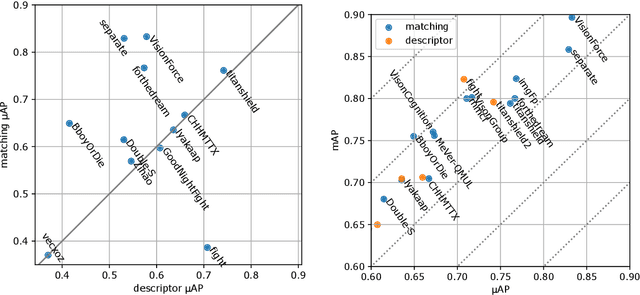
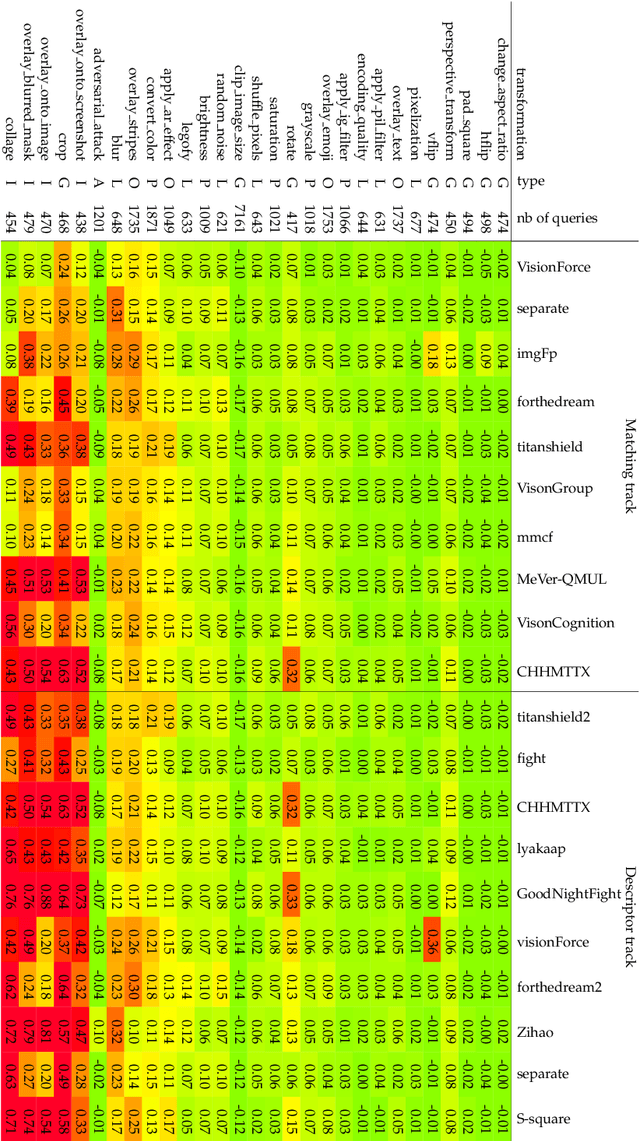
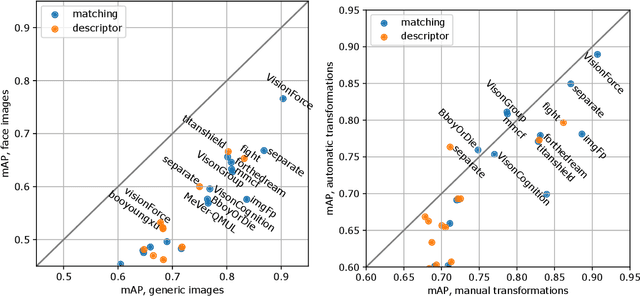
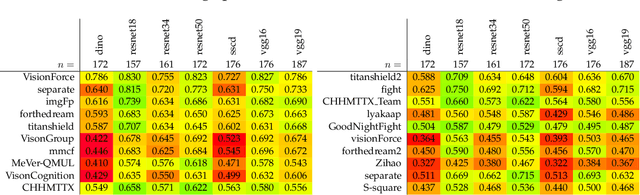
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
Graph convolutional networks for learning with few clean and many noisy labels
Oct 01, 2019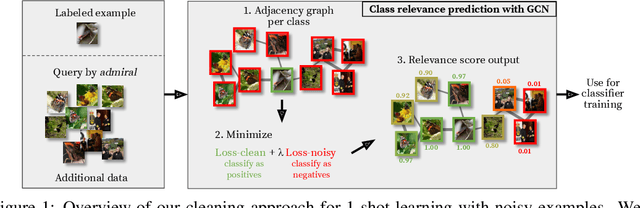
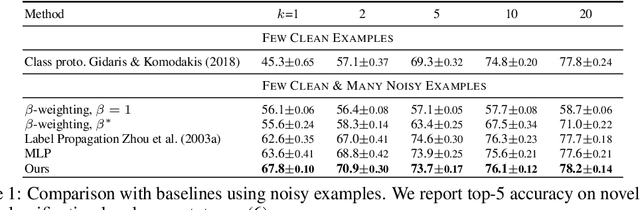

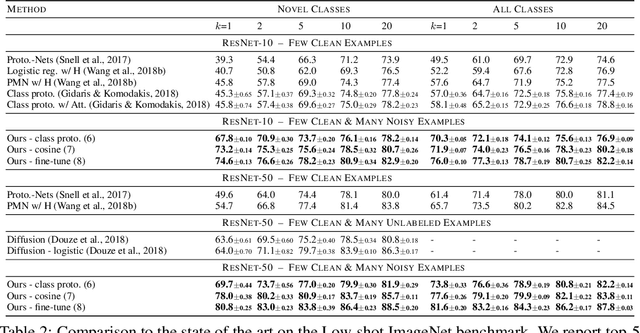
In this work we consider the problem of learning a classifier from noisy labels when a few clean labeled examples are given. The structure of clean and noisy data is modeled by a graph per class and Graph Convolutional Networks (GCN) are used to predict class relevance of noisy examples. For each class, the GCN is treated as a binary classifier learning to discriminate clean from noisy examples using a weighted binary cross-entropy loss function, and then the GCN-inferred "clean" probability is exploited as a relevance measure. Each noisy example is weighted by its relevance when learning a classifier for the end task. We evaluate our method on an extended version of a few-shot learning problem, where the few clean examples of novel classes are supplemented with additional noisy data. Experimental results show that our GCN-based cleaning process significantly improves the classification accuracy over not cleaning the noisy data and standard few-shot classification where only few clean examples are used. The proposed GCN-based method outperforms the transductive approach (Douze et al., 2018) that is using the same additional data without labels.
Local Features and Visual Words Emerge in Activations
May 15, 2019
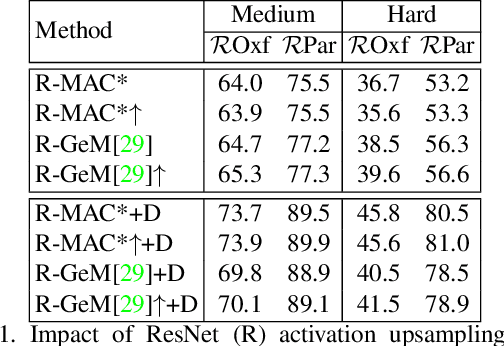

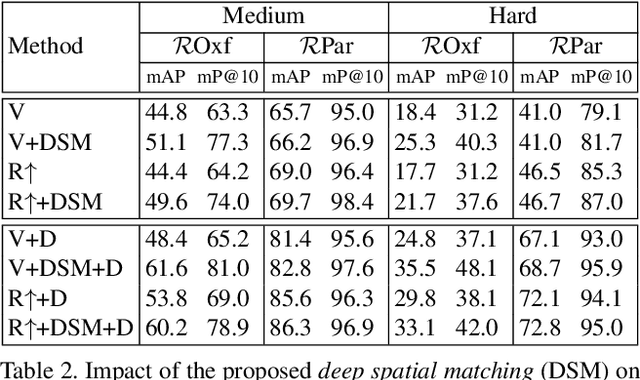
We propose a novel method of deep spatial matching (DSM) for image retrieval. Initial ranking is based on image descriptors extracted from convolutional neural network activations by global pooling, as in recent state-of-the-art work. However, the same sparse 3D activation tensor is also approximated by a collection of local features. These local features are then robustly matched to approximate the optimal alignment of the tensors. This happens without any network modification, additional layers or training. No local feature detection happens on the original image. No local feature descriptors and no visual vocabulary are needed throughout the whole process. We experimentally show that the proposed method achieves the state-of-the-art performance on standard benchmarks across different network architectures and different global pooling methods. The highest gain in performance is achieved when diffusion on the nearest-neighbor graph of global descriptors is initiated from spatially verified images.
Explicit Spatial Encoding for Deep Local Descriptors
Apr 15, 2019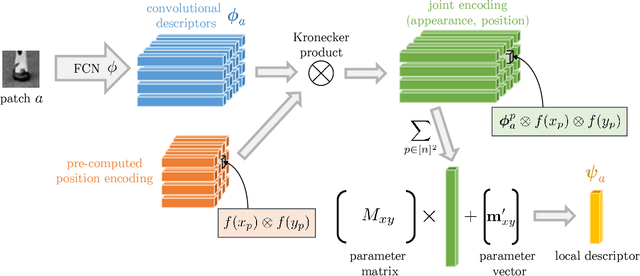

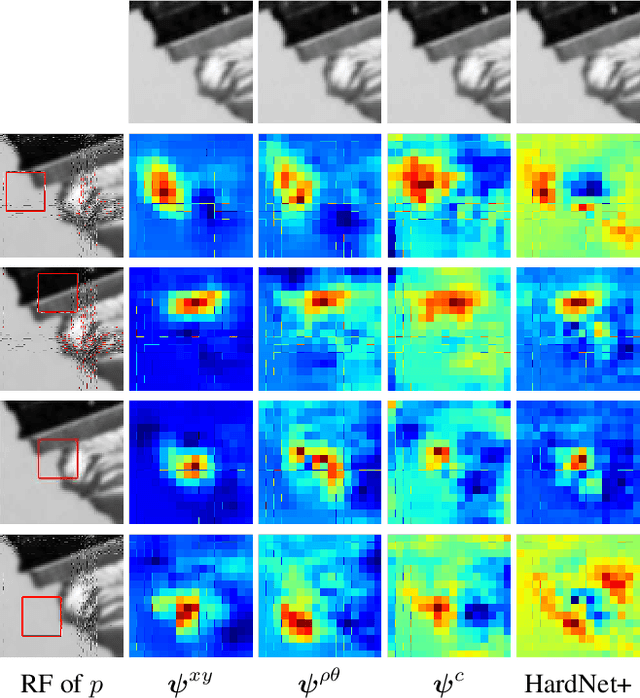

We propose a kernelized deep local-patch descriptor based on efficient match kernels of neural network activations. Response of each receptive field is encoded together with its spatial location using explicit feature maps. Two location parametrizations, Cartesian and polar, are used to provide robustness to a different types of canonical patch misalignment. Additionally, we analyze how the conventional architecture, i.e. a fully connected layer attached after the convolutional part, encodes responses in a spatially variant way. In contrary, explicit spatial encoding is used in our descriptor, whose potential applications are not limited to local-patches. We evaluate the descriptor on standard benchmarks. Both versions, encoding 32x32 or 64x64 patches, consistently outperform all other methods on all benchmarks. The number of parameters of the model is independent of the input patch resolution.
Label Propagation for Deep Semi-supervised Learning
Apr 09, 2019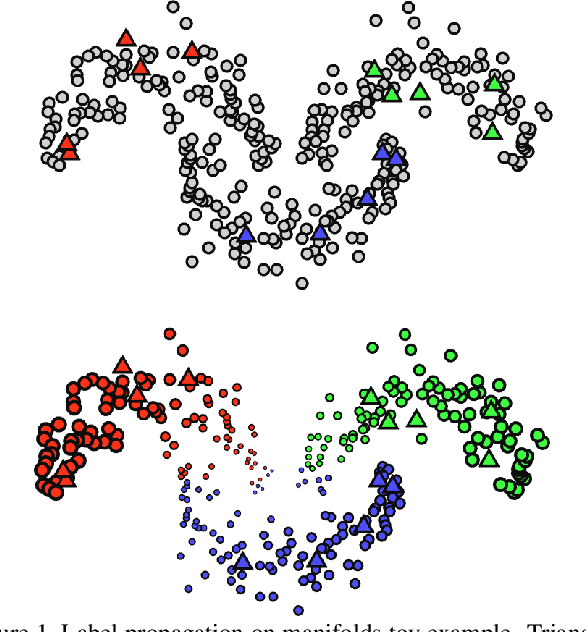
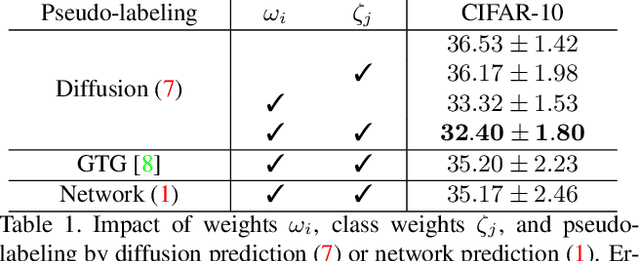
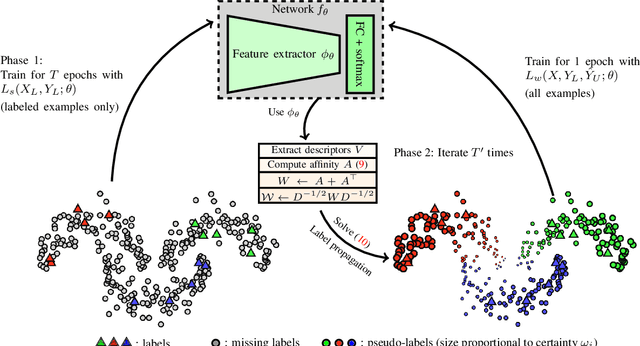
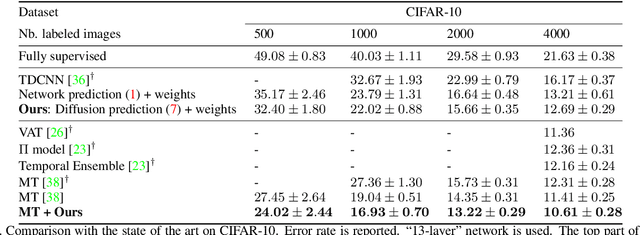
Semi-supervised learning is becoming increasingly important because it can combine data carefully labeled by humans with abundant unlabeled data to train deep neural networks. Classic methods on semi-supervised learning that have focused on transductive learning have not been fully exploited in the inductive framework followed by modern deep learning. The same holds for the manifold assumption---that similar examples should get the same prediction. In this work, we employ a transductive label propagation method that is based on the manifold assumption to make predictions on the entire dataset and use these predictions to generate pseudo-labels for the unlabeled data and train a deep neural network. At the core of the transductive method lies a nearest neighbor graph of the dataset that we create based on the embeddings of the same network.Therefore our learning process iterates between these two steps. We improve performance on several datasets especially in the few labels regime and show that our work is complementary to current state of the art.
Rectification from Radially-Distorted Scales
Oct 30, 2018



This paper introduces the first minimal solvers that jointly estimate lens distortion and affine rectification from repetitions of rigidly transformed coplanar local features. The proposed solvers incorporate lens distortion into the camera model and extend accurate rectification to wide-angle images that contain nearly any type of coplanar repeated content. We demonstrate a principled approach to generating stable minimal solvers by the Grobner basis method, which is accomplished by sampling feasible monomial bases to maximize numerical stability. Synthetic and real-image experiments confirm that the solvers give accurate rectifications from noisy measurements when used in a RANSAC-based estimator. The proposed solvers demonstrate superior robustness to noise compared to the state-of-the-art. The solvers work on scenes without straight lines and, in general, relax the strong assumptions on scene content made by the state-of-the-art. Accurate rectifications on imagery that was taken with narrow focal length to near fish-eye lenses demonstrate the wide applicability of the proposed method. The method is fully automated, and the code is publicly available at https://github.com/prittjam/repeats.
Local Orthogonal-Group Testing
Sep 20, 2018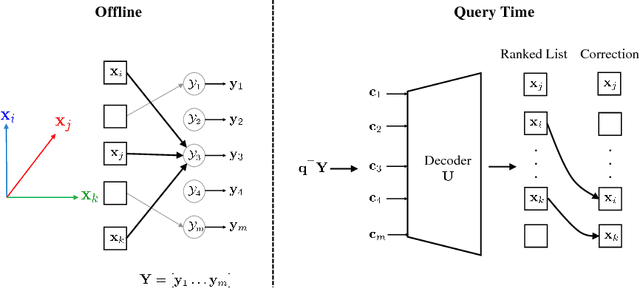

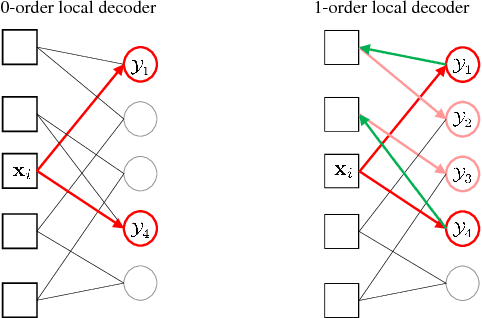
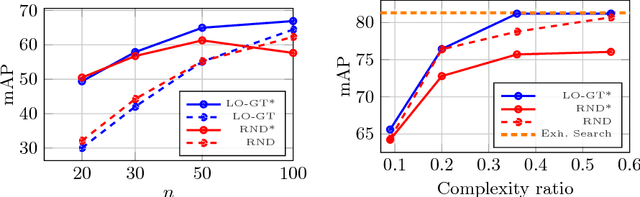
This work addresses approximate nearest neighbor search applied in the domain of large-scale image retrieval. Within the group testing framework we propose an efficient off-line construction of the search structures. The linear-time complexity orthogonal grouping increases the probability that at most one element from each group is matching to a given query. Non-maxima suppression with each group efficiently reduces the number of false positive results at no extra cost. Unlike in other well-performing approaches, all processing is local, fast, and suitable to process data in batches and in parallel. We experimentally show that the proposed method achieves search accuracy of the exhaustive search with significant reduction in the search complexity. The method can be naturally combined with existing embedding methods.
Hybrid Diffusion: Spectral-Temporal Graph Filtering for Manifold Ranking
Jul 23, 2018


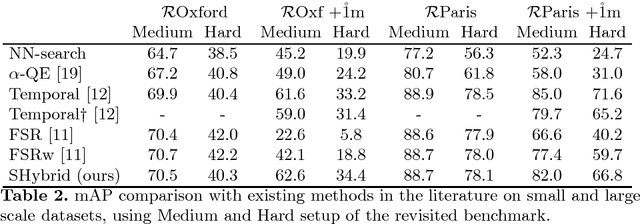
State of the art image retrieval performance is achieved with CNN features and manifold ranking using a k-NN similarity graph that is pre-computed off-line. The two most successful existing approaches are temporal filtering, where manifold ranking amounts to solving a sparse linear system online, and spectral filtering, where eigen-decomposition of the adjacency matrix is performed off-line and then manifold ranking amounts to dot-product search online. The former suffers from expensive queries and the latter from significant space overhead. Here we introduce a novel, theoretically well-founded hybrid filtering approach allowing full control of the space-time trade-off between these two extremes. Experimentally, we verify that our hybrid method delivers results on par with the state of the art, with lower memory demands compared to spectral filtering approaches and faster compared to temporal filtering.