 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Orthogonal-Group Testing
Paper and Code
Sep 20, 2018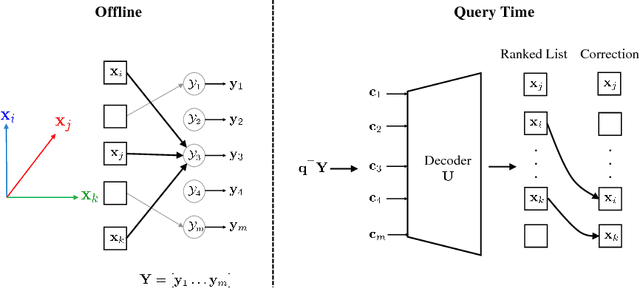

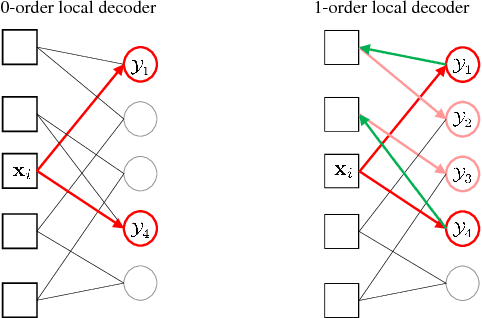
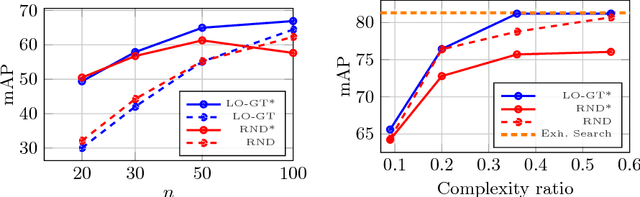
This work addresses approximate nearest neighbor search applied in the domain of large-scale image retrieval. Within the group testing framework we propose an efficient off-line construction of the search structures. The linear-time complexity orthogonal grouping increases the probability that at most one element from each group is matching to a given query. Non-maxima suppression with each group efficiently reduces the number of false positive results at no extra cost. Unlike in other well-performing approaches, all processing is local, fast, and suitable to process data in batches and in parallel. We experimentally show that the proposed method achieves search accuracy of the exhaustive search with significant reduction in the search complexity. The method can be naturally combined with existing embedding methods.