 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effects of Short Video-Sharing Services on Video Copy Detection
Mar 26, 2024The short video-sharing services that allow users to post 10-30 second videos (e.g., YouTube Shorts and TikTok) have attracted a lot of attention in recent years. However, conventional video copy detection (VCD) methods mainly focus on general video-sharing services (e.g., YouTube and Bilibili), and the effects of short video-sharing services on video copy detection are still unclear. Considering that illegally copied videos in short video-sharing services have service-distinctive characteristics, especially in those time lengths, the pros and cons of VCD in those services are required to be analyzed. In this paper, we examine the effects of short video-sharing services on VCD by constructing a dataset that has short video-sharing service characteristics. Our novel dataset is automatically constructed from the publicly available dataset to have reference videos and fixed short-time-length query videos, and such automation procedures assure the reproducibility and data privacy preservation of this paper. From the experimental results focusing on segment-level and video-level situations, we can see that three effects: "Segment-level VCD in short video-sharing services is more difficult than those in general video-sharing services", "Video-level VCD in short video-sharing services is easier than those in general video-sharing services", "The video alignment component mainly suppress the detection performance in short video-sharing services".
Leveraging Image-Text Similarity and Caption Modification for the DataComp Challenge: Filtering Track and BYOD Track
Oct 23, 2023Large web crawl datasets have already played an important role in learning multimodal features with high generalization capabilities. However, there are still very limited studies investigating the details or improvements of data design. Recently, a DataComp challenge has been designed to propose the best training data with the fixed models. This paper presents our solution to both filtering track and BYOD track of the DataComp challenge. Our solution adopts large multimodal models CLIP and BLIP-2 to filter and modify web crawl data, and utilize external datasets along with a bag of tricks to improve the data quality. Experiments show our solution significantly outperforms DataComp baselines (filtering track: 6.6% improvement, BYOD track: 48.5% improvement).
3rd Place Solution to Meta AI Video Similarity Challenge
Apr 24, 2023This paper presents our 3rd place solution in both Descriptor Track and Matching Track of the Meta AI Video Similarity Challenge (VSC2022), a competition aimed at detecting video copies. Our approach builds upon existing image copy detection techniques and incorporates several strategies to exploit on the properties of video data, resulting in a simple yet powerful solution. By employing our proposed method, we achieved substantial improvements in accuracy compared to the baseline results (Descriptor Track: 41% improvement, Matching Track: 76% improvement). Our code is publicly available here: https://github.com/line/Meta-AI-Video-Similarity-Challenge-3rd-Place-Solution
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022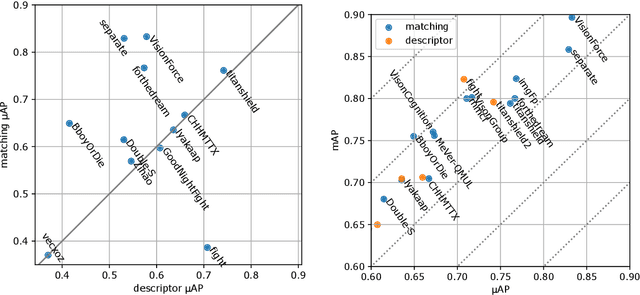
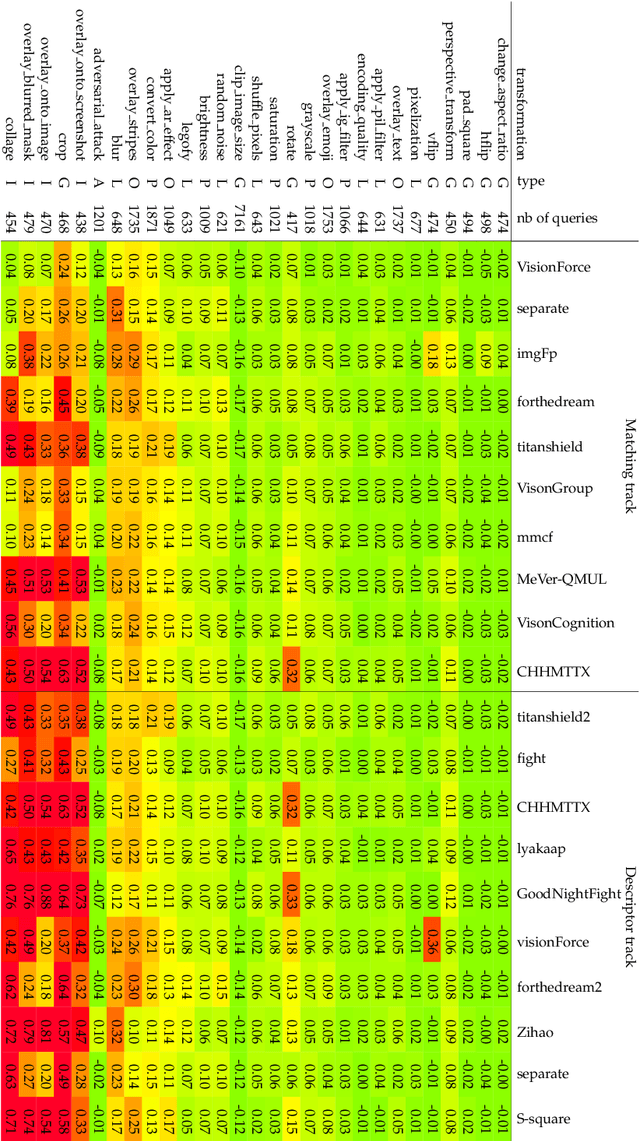
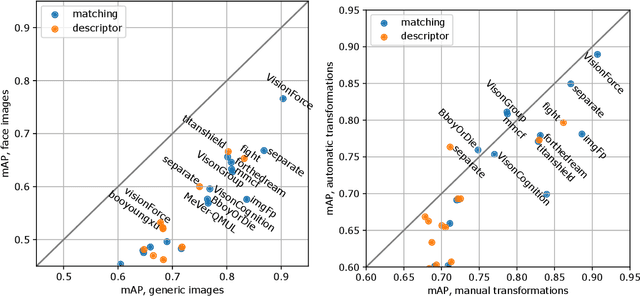
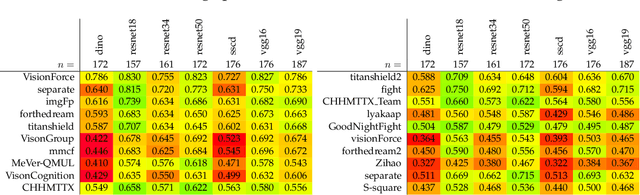
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
Contrastive Learning with Large Memory Bank and Negative Embedding Subtraction for Accurate Copy Detection
Dec 08, 2021


Copy detection, which is a task to determine whether an image is a modified copy of any image in a database, is an unsolved problem. Thus, we addressed copy detection by training convolutional neural networks (CNNs) with contrastive learning. Training with a large memory-bank and hard data augmentation enables the CNNs to obtain more discriminative representation. Our proposed negative embedding subtraction further boosts the copy detection accuracy. Using our methods, we achieved 1st place in the Facebook AI Image Similarity Challenge: Descriptor Track. Our code is publicly available here: \url{https://github.com/lyakaap/ISC21-Descriptor-Track-1st}
Two-stage Discriminative Re-ranking for Large-scale Landmark Retrieval
Mar 25, 2020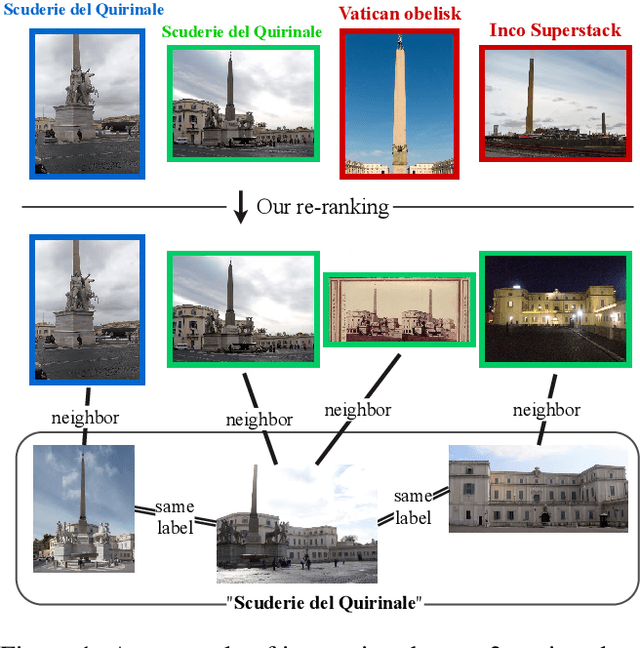
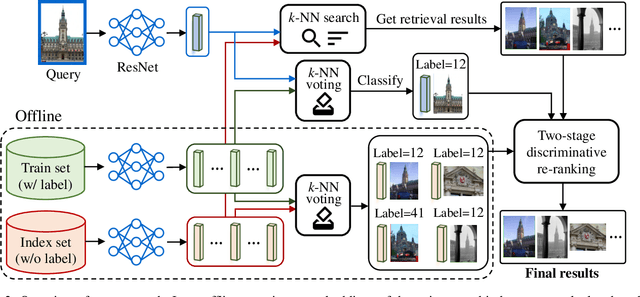
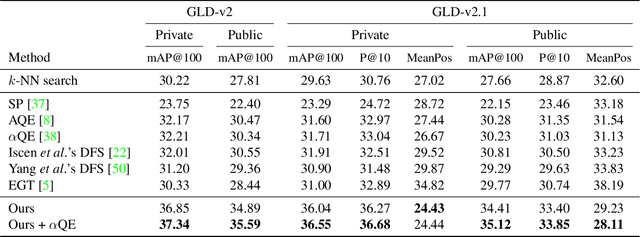
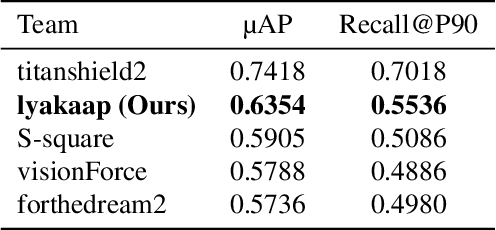
We propose an efficient pipeline for large-scale landmark image retrieval that addresses the diversity of the dataset through two-stage discriminative re-ranking. Our approach is based on embedding the images in a feature-space using a convolutional neural network trained with a cosine softmax loss. Due to the variance of the images, which include extreme viewpoint changes such as having to retrieve images of the exterior of a landmark from images of the interior, this is very challenging for approaches based exclusively on visual similarity. Our proposed re-ranking approach improves the results in two steps: in the sort-step, $k$-nearest neighbor search with soft-voting to sort the retrieved results based on their label similarity to the query images, and in the insert-step, we add additional samples from the dataset that were not retrieved by image-similarity. This approach allows overcoming the low visual diversity in retrieved images. In-depth experimental results show that the proposed approach significantly outperforms existing approaches on the challenging Google Landmarks Datasets. Using our methods, we achieved 1st place in the Google Landmark Retrieval 2019 challenge and 3rd place in the Google Landmark Recognition 2019 challenge on Kaggle. Our code is publicly available here: \url{https://github.com/lyakaap/Landmark2019-1st-and-3rd-Place-Solution}
Large-scale Landmark Retrieval/Recognition under a Noisy and Diverse Dataset
Jun 11, 2019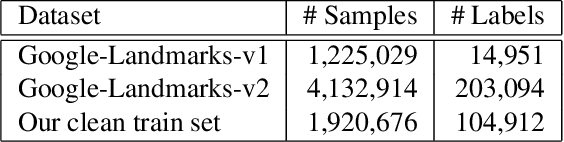

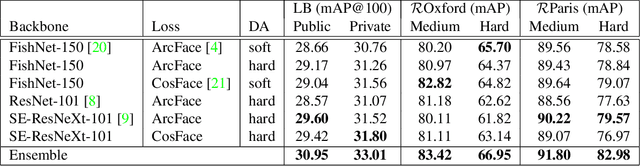
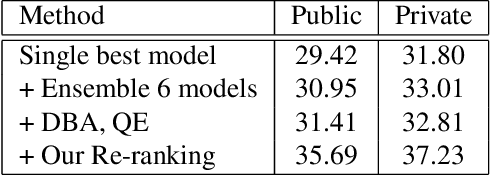
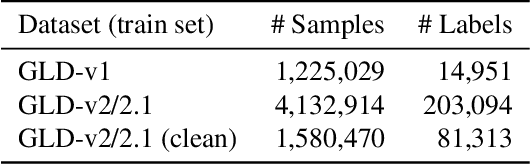
The Google-Landmarks-v2 dataset is the biggest worldwide landmarks dataset characterized by a large magnitude of noisiness and diversity. We present a novel landmark retrieval/recognition system, robust to a noisy and diverse dataset, by our team, smlyaka. Our approach is based on deep convolutional neural networks with metric learning, trained by cosine-softmax based losses. Deep metric learning methods are usually sensitive to noise, and it could hinder to learn a reliable metric. To address this issue, we develop an automated data cleaning system. Besides, we devise a discriminative re-ranking method to address the diversity of the dataset for landmark retrieval. Using our methods, we achieved 1st place in the Google Landmark Retrieval 2019 challenge and 3rd place in the Google Landmark Recognition 2019 challenge on Kaggle.