 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixture-of-World Models: Scaling Multi-Task Reinforcement Learning with Modular Latent Dynamics
Feb 01, 2026A fundamental challenge in multi-task reinforcement learning (MTRL) is achieving sample efficiency in visual domains where tasks exhibit substantial heterogeneity in both observations and dynamics. Model-based reinforcement learning offers a promising path to improved sample efficiency through world models, but standard monolithic architectures struggle to capture diverse task dynamics, resulting in poor reconstruction and prediction accuracy. We introduce Mixture-of-World Models (MoW), a scalable architecture that combines modular variational autoencoders for task-adaptive visual compression, a hybrid Transformer-based dynamics model with task-conditioned experts and a shared backbone, and a gradient-based task clustering strategy for efficient parameter allocation. On the Atari 100k benchmark, a single MoW agent trained once on 26 Atari games achieves a mean human-normalized score of 110.4%, competitive with the score of 114.2% achieved by STORM, an ensemble of 26 task-specific models, while using 50% fewer parameters. On Meta-World, MoW achieves a 74.5% average success rate within 300 thousand environment steps, establishing a new state of the art. These results demonstrate that MoW provides a scalable and parameter-efficient foundation for generalist world models.
Objects matter: object-centric world models improve reinforcement learning in visually complex environments
Jan 27, 2025Deep reinforcement learning has achieved remarkable success in learning control policies from pixels across a wide range of tasks, yet its application remains hindered by low sample efficiency, requiring significantly more environment interactions than humans to reach comparable performance. Model-based reinforcement learning (MBRL) offers a solution by leveraging learnt world models to generate simulated experience, thereby improving sample efficiency. However, in visually complex environments, small or dynamic elements can be critical for decision-making. Yet, traditional MBRL methods in pixel-based environments typically rely on auto-encoding with an $L_2$ loss, which is dominated by large areas and often fails to capture decision-relevant details. To address these limitations, we propose an object-centric MBRL pipeline, which integrates recent advances in computer vision to allow agents to focus on key decision-related elements. Our approach consists of four main steps: (1) annotating key objects related to rewards and goals with segmentation masks, (2) extracting object features using a pre-trained, frozen foundation vision model, (3) incorporating these object features with the raw observations to predict environmental dynamics, and (4) training the policy using imagined trajectories generated by this object-centric world model. Building on the efficient MBRL algorithm STORM, we call this pipeline OC-STORM. We demonstrate OC-STORM's practical value in overcoming the limitations of conventional MBRL approaches on both Atari games and the visually complex game Hollow Knight.
STORM: Efficient Stochastic Transformer based World Models for Reinforcement Learning
Oct 14, 2023Recently, model-based reinforcement learning algorithms have demonstrated remarkable efficacy in visual input environments. These approaches begin by constructing a parameterized simulation world model of the real environment through self-supervised learning. By leveraging the imagination of the world model, the agent's policy is enhanced without the constraints of sampling from the real environment. The performance of these algorithms heavily relies on the sequence modeling and generation capabilities of the world model. However, constructing a perfectly accurate model of a complex unknown environment is nearly impossible. Discrepancies between the model and reality may cause the agent to pursue virtual goals, resulting in subpar performance in the real environment. Introducing random noise into model-based reinforcement learning has been proven beneficial. In this work, we introduce Stochastic Transformer-based wORld Model (STORM), an efficient world model architecture that combines the strong sequence modeling and generation capabilities of Transformers with the stochastic nature of variational autoencoders. STORM achieves a mean human performance of $126.7\%$ on the Atari $100$k benchmark, setting a new record among state-of-the-art methods that do not employ lookahead search techniques. Moreover, training an agent with $1.85$ hours of real-time interaction experience on a single NVIDIA GeForce RTX 3090 graphics card requires only $4.3$ hours, showcasing improved efficiency compared to previous methodologies.
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022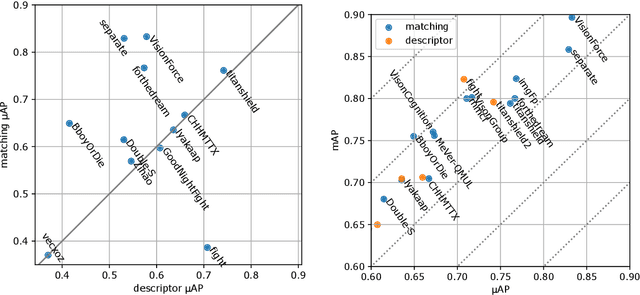
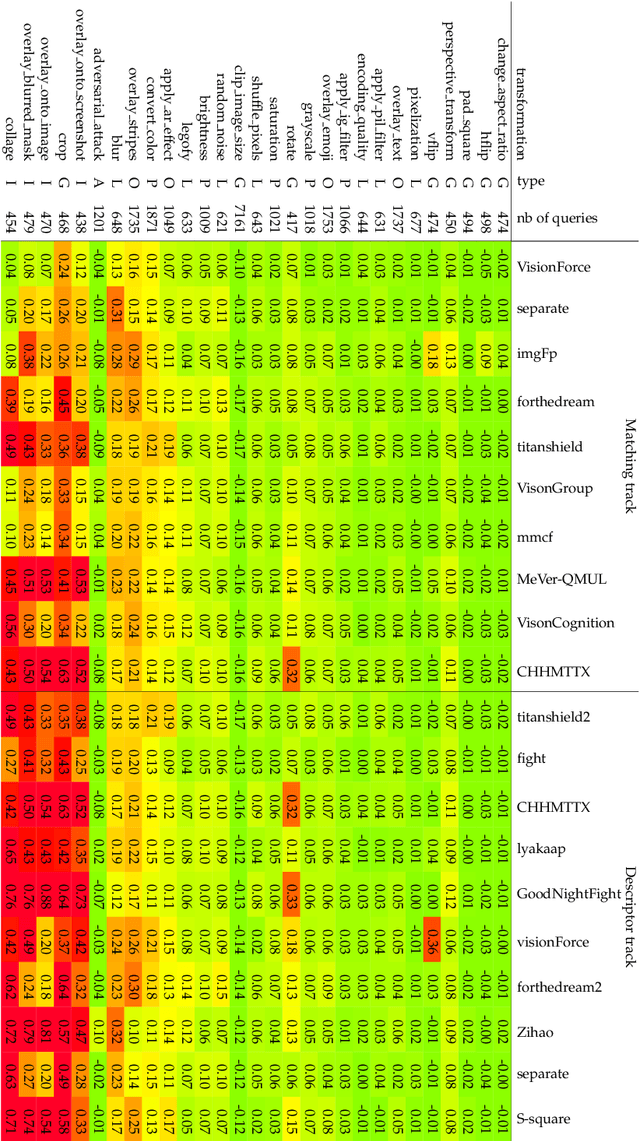
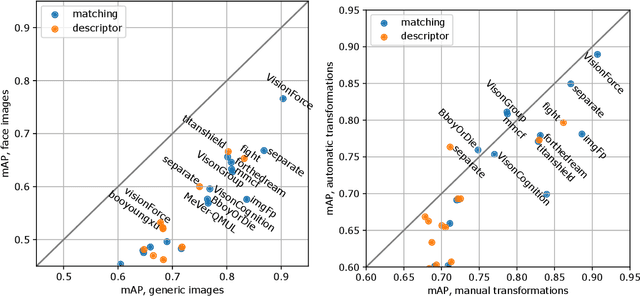
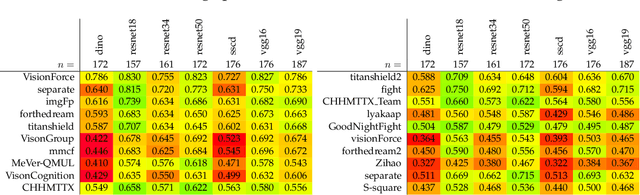
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
CSSR: A Context-Aware Sequential Software Service Recommendation Model
Dec 20, 2021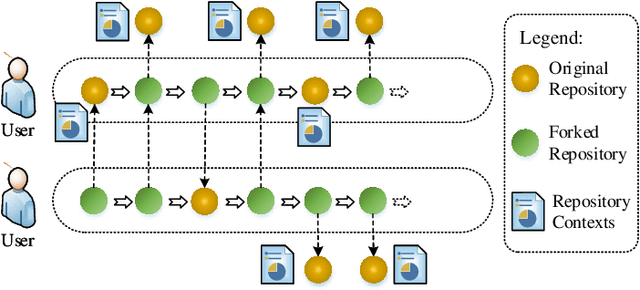
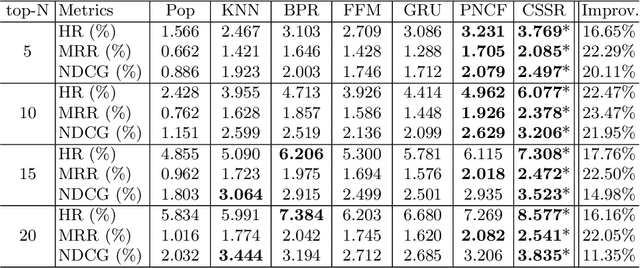
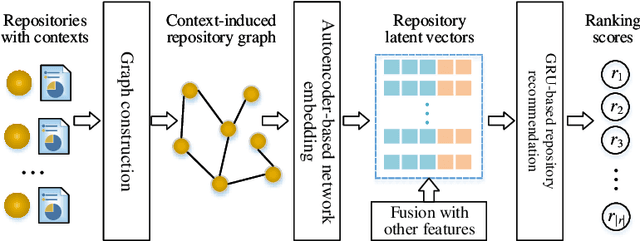
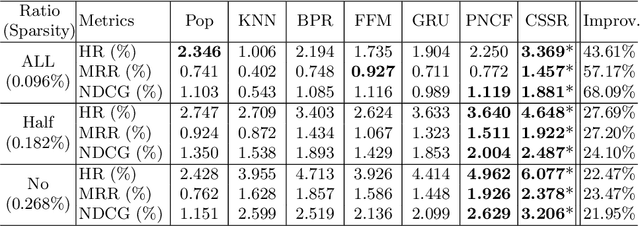
We propose a novel software service recommendation model to help users find their suitable repositories in GitHub. Our model first designs a novel context-induced repository graph embedding method to leverage rich contextual information of repositories to alleviate the difficulties caused by the data sparsity issue. It then leverages sequence information of user-repository interactions for the first time in the software service recommendation field. Specifically, a deep-learning based sequential recommendation technique is adopted to capture the dynamics of user preferences. Comprehensive experiments have been conducted on a large dataset collected from GitHub against a list of existing methods. The results illustrate the superiority of our method in various aspects.
* 16 pages, 5 figures, 2 tables, The long version of the paper with the same title in ICSoC 2021
D$^2$LV: A Data-Driven and Local-Verification Approach for Image Copy Detection
Dec 04, 2021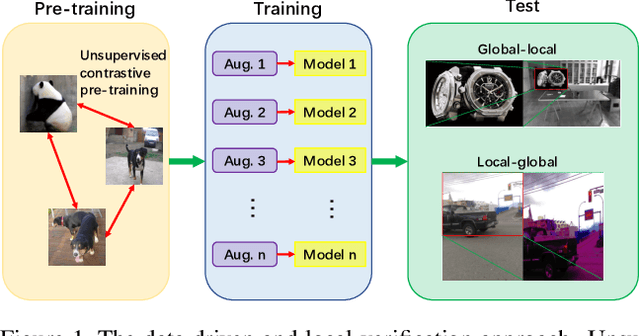
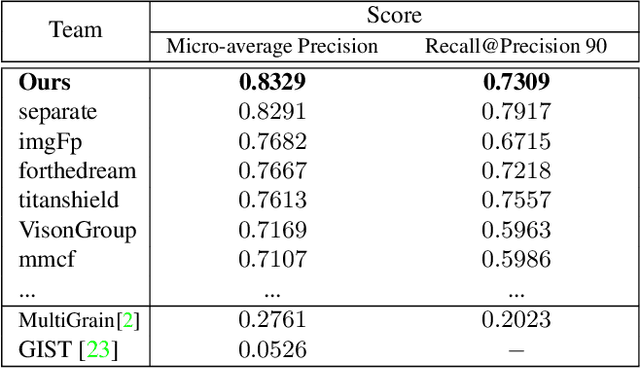
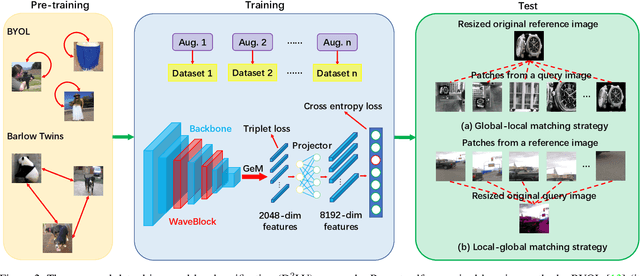
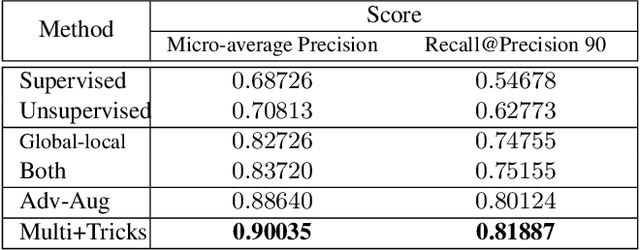
Image copy detection is of great importance in real-life social media. In this paper, a data-driven and local-verification (D$^2$LV) approach is proposed to compete for Image Similarity Challenge: Matching Track at NeurIPS'21. In D$^2$LV, unsupervised pre-training substitutes the commonly-used supervised one. When training, we design a set of basic and six advanced transformations, and a simple but effective baseline learns robust representation. During testing, a global-local and local-global matching strategy is proposed. The strategy performs local-verification between reference and query images. Experiments demonstrate that the proposed method is effective. The proposed approach ranks first out of 1,103 participants on the Facebook AI Image Similarity Challenge: Matching Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track1-Submission.
Bag of Tricks and A Strong baseline for Image Copy Detection
Dec 04, 2021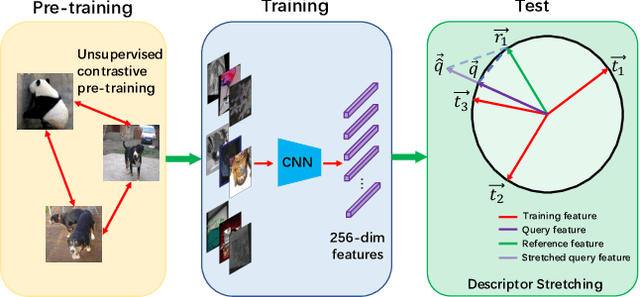
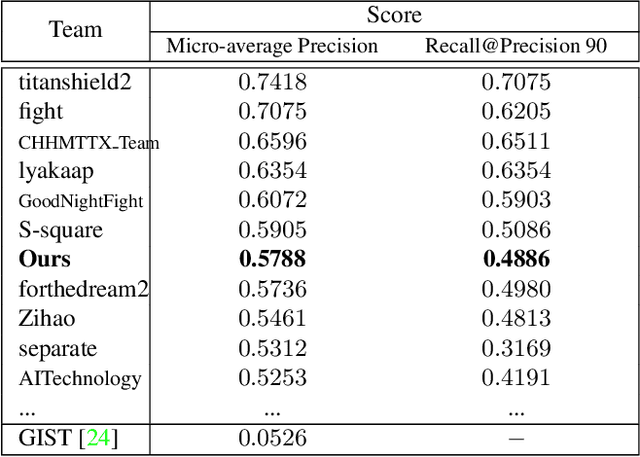
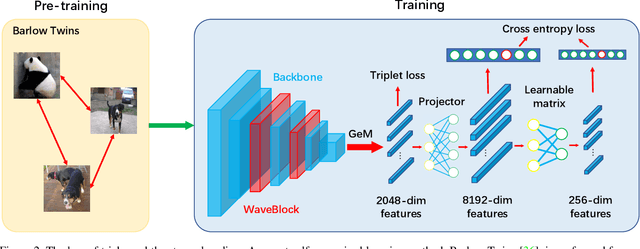
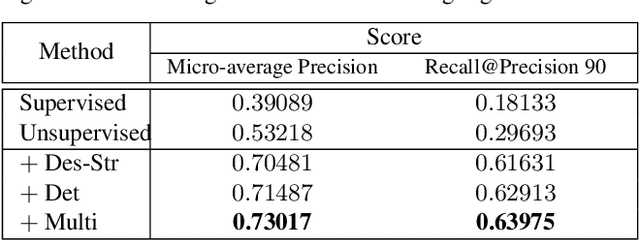
Image copy detection is of great importance in real-life social media. In this paper, a bag of tricks and a strong baseline are proposed for image copy detection. Unsupervised pre-training substitutes the commonly-used supervised one. Beyond that, we design a descriptor stretching strategy to stabilize the scores of different queries. Experiments demonstrate that the proposed method is effective. The proposed baseline ranks third out of 526 participants on the Facebook AI Image Similarity Challenge: Descriptor Track. The code and trained models are available at https://github.com/WangWenhao0716/ISC-Track2-Submission.