 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Offline Imitation Learning Through State-level Trajectory Stitching
Mar 28, 2025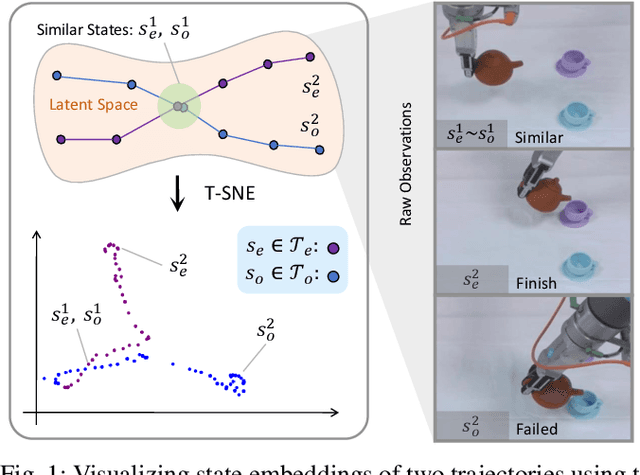



Imitation learning (IL) has proven effective for enabling robots to acquire visuomotor skills through expert demonstrations. However, traditional IL methods are limited by their reliance on high-quality, often scarce, expert data, and suffer from covariate shift. To address these challenges, recent advances in offline IL have incorporated suboptimal, unlabeled datasets into the training. In this paper, we propose a novel approach to enhance policy learning from mixed-quality offline datasets by leveraging task-relevant trajectory fragments and rich environmental dynamics. Specifically, we introduce a state-based search framework that stitches state-action pairs from imperfect demonstrations, generating more diverse and informative training trajectories. Experimental results on standard IL benchmarks and real-world robotic tasks showcase that our proposed method significantly improves both generalization and performance.
STORM: Efficient Stochastic Transformer based World Models for Reinforcement Learning
Oct 14, 2023Recently, model-based reinforcement learning algorithms have demonstrated remarkable efficacy in visual input environments. These approaches begin by constructing a parameterized simulation world model of the real environment through self-supervised learning. By leveraging the imagination of the world model, the agent's policy is enhanced without the constraints of sampling from the real environment. The performance of these algorithms heavily relies on the sequence modeling and generation capabilities of the world model. However, constructing a perfectly accurate model of a complex unknown environment is nearly impossible. Discrepancies between the model and reality may cause the agent to pursue virtual goals, resulting in subpar performance in the real environment. Introducing random noise into model-based reinforcement learning has been proven beneficial. In this work, we introduce Stochastic Transformer-based wORld Model (STORM), an efficient world model architecture that combines the strong sequence modeling and generation capabilities of Transformers with the stochastic nature of variational autoencoders. STORM achieves a mean human performance of $126.7\%$ on the Atari $100$k benchmark, setting a new record among state-of-the-art methods that do not employ lookahead search techniques. Moreover, training an agent with $1.85$ hours of real-time interaction experience on a single NVIDIA GeForce RTX 3090 graphics card requires only $4.3$ hours, showcasing improved efficiency compared to previous methodologies.