 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2023 Video Similarity Dataset and Challenge
Jun 15, 2023
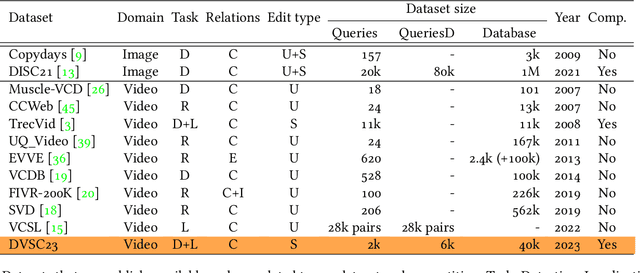

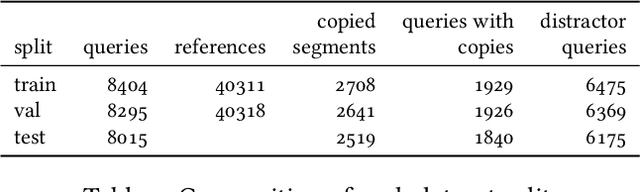
This work introduces a dataset, benchmark, and challenge for the problem of video copy detection and localization. The problem comprises two distinct but related tasks: determining whether a query video shares content with a reference video ("detection"), and additionally temporally localizing the shared content within each video ("localization"). The benchmark is designed to evaluate methods on these two tasks, and simulates a realistic needle-in-haystack setting, where the majority of both query and reference videos are "distractors" containing no copied content. We propose a metric that reflects both detection and localization accuracy. The associated challenge consists of two corresponding tracks, each with restrictions that reflect real-world settings. We provide implementation code for evaluation and baselines. We also analyze the results and methods of the top submissions to the challenge. The dataset, baseline methods and evaluation code is publicly available and will be discussed at a dedicated CVPR'23 workshop.
A Self-Supervised Descriptor for Image Copy Detection
Mar 25, 2022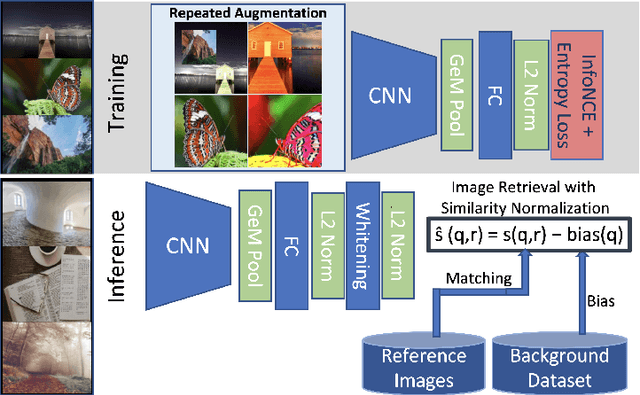


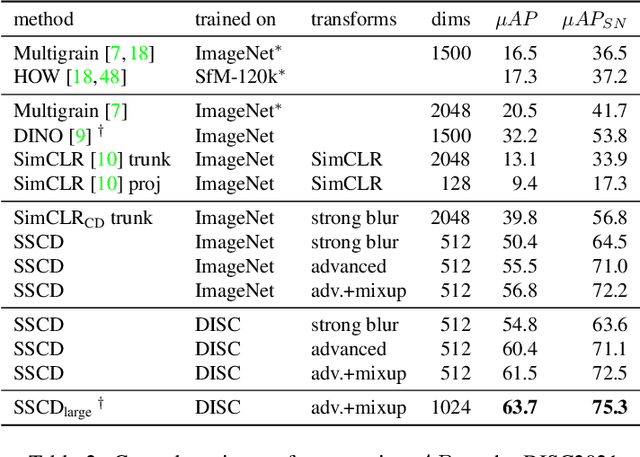
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute. Code is available at https://github.com/facebookresearch/sscd-copy-detection.
Results and findings of the 2021 Image Similarity Challenge
Feb 08, 2022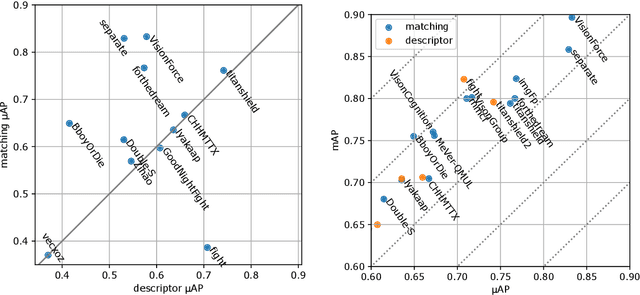
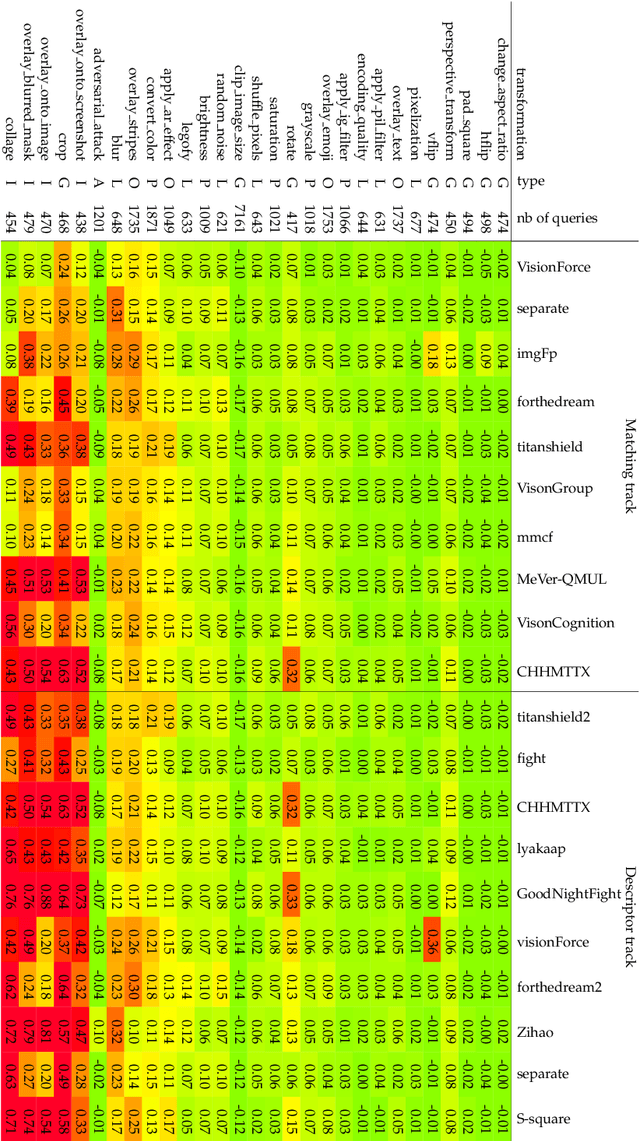
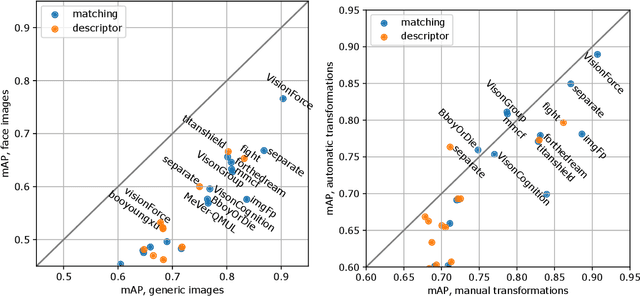
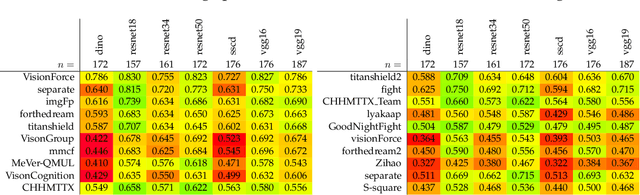
The 2021 Image Similarity Challenge introduced a dataset to serve as a new benchmark to evaluate recent image copy detection methods. There were 200 participants to the competition. This paper presents a quantitative and qualitative analysis of the top submissions. It appears that the most difficult image transformations involve either severe image crops or hiding into unrelated images, combined with local pixel perturbations. The key algorithmic elements in the winning submissions are: training on strong augmentations, self-supervised learning, score normalization, explicit overlay detection, and global descriptor matching followed by pairwise image comparison.
The 2021 Image Similarity Dataset and Challenge
Jul 01, 2021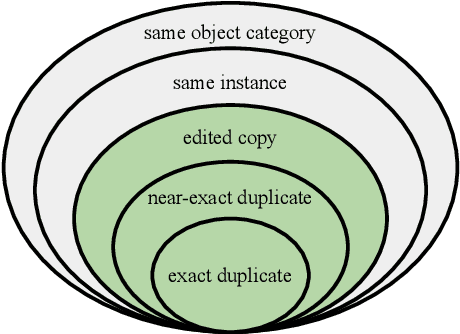
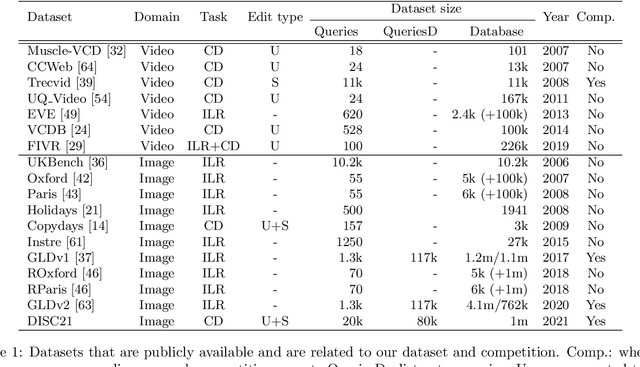
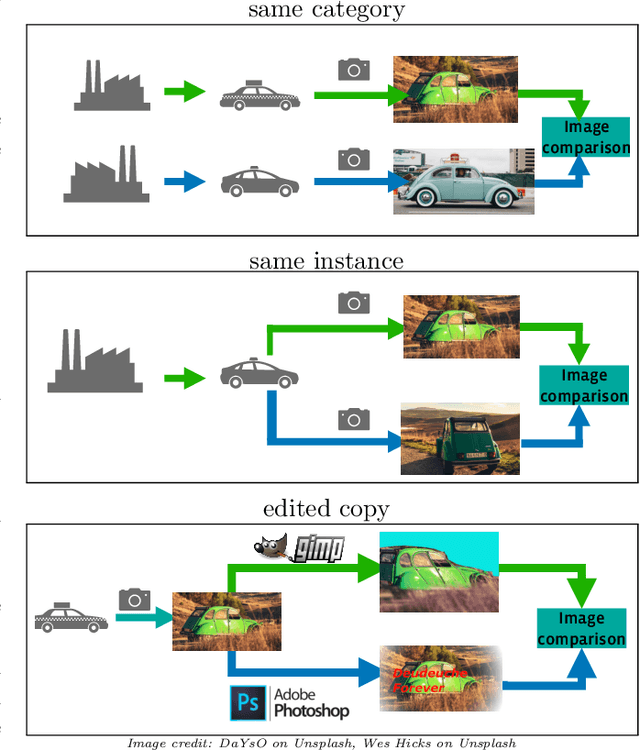

This paper introduces a new benchmark for large-scale image similarity detection. This benchmark is used for the Image Similarity Challenge at NeurIPS'21 (ISC2021). The goal is to determine whether a query image is a modified copy of any image in a reference corpus of size 1~million. The benchmark features a variety of image transformations such as automated transformations, hand-crafted image edits and machine-learning based manipulations. This mimics real-life cases appearing in social media, for example for integrity-related problems dealing with misinformation and objectionable content. The strength of the image manipulations, and therefore the difficulty of the benchmark, is calibrated according to the performance of a set of baseline approaches. Both the query and reference set contain a majority of "distractor" images that do not match, which corresponds to a real-life needle-in-haystack setting, and the evaluation metric reflects that. We expect the DISC21 benchmark to promote image copy detection as an important and challenging computer vision task and refresh the state of the art.