 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Model for Tracking and Image-Video Detection Has More Power
Nov 20, 2022



Objection detection (OD) has been one of the most fundamental tasks in computer vision. Recent developments in deep learning have pushed the performance of image OD to new heights by learning-based, data-driven approaches. On the other hand, video OD remains less explored, mostly due to much more expensive data annotation needs. At the same time, multi-object tracking (MOT) which requires reasoning about track identities and spatio-temporal trajectories, shares similar spirits with video OD. However, most MOT datasets are class-specific (e.g., person-annotated only), which constrains a model's flexibility to perform tracking on other objects. We propose TrIVD (Tracking and Image-Video Detection), the first framework that unifies image OD, video OD, and MOT within one end-to-end model. To handle the discrepancies and semantic overlaps across datasets, TrIVD formulates detection/tracking as grounding and reasons about object categories via visual-text alignments. The unified formulation enables cross-dataset, multi-task training, and thus equips TrIVD with the ability to leverage frame-level features, video-level spatio-temporal relations, as well as track identity associations. With such joint training, we can now extend the knowledge from OD data, that comes with much richer object category annotations, to MOT and achieve zero-shot tracking capability. Experiments demonstrate that TrIVD achieves state-of-the-art performances across all image/video OD and MOT tasks.
A Self-Supervised Descriptor for Image Copy Detection
Mar 25, 2022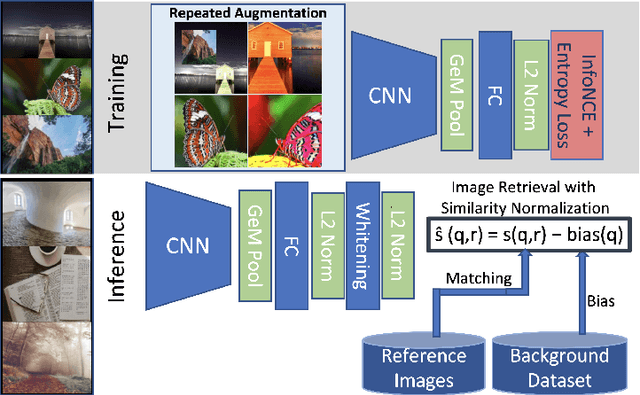


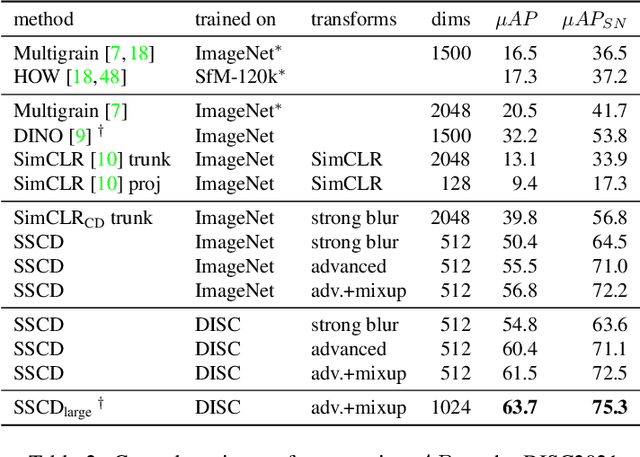
Image copy detection is an important task for content moderation. We introduce SSCD, a model that builds on a recent self-supervised contrastive training objective. We adapt this method to the copy detection task by changing the architecture and training objective, including a pooling operator from the instance matching literature, and adapting contrastive learning to augmentations that combine images. Our approach relies on an entropy regularization term, promoting consistent separation between descriptor vectors, and we demonstrate that this significantly improves copy detection accuracy. Our method produces a compact descriptor vector, suitable for real-world web scale applications. Statistical information from a background image distribution can be incorporated into the descriptor. On the recent DISC2021 benchmark, SSCD is shown to outperform both baseline copy detection models and self-supervised architectures designed for image classification by huge margins, in all settings. For example, SSCD out-performs SimCLR descriptors by 48% absolute. Code is available at https://github.com/facebookresearch/sscd-copy-detection.
MOOD: Multi-level Out-of-distribution Detection
Apr 30, 2021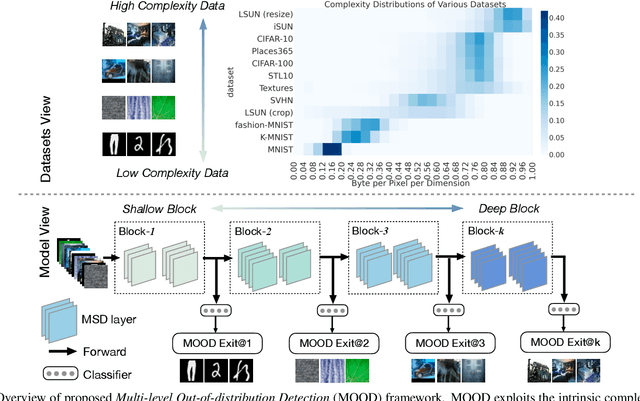
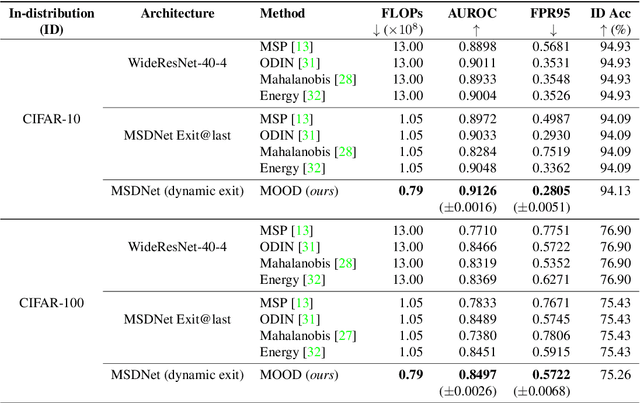
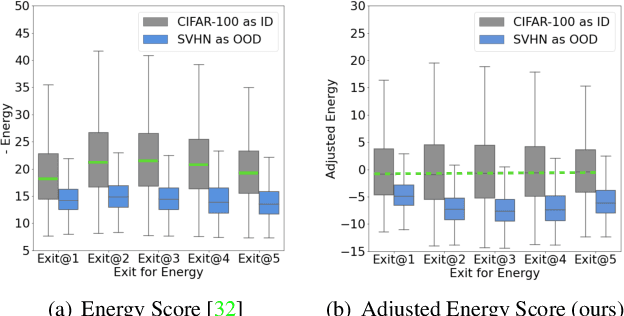
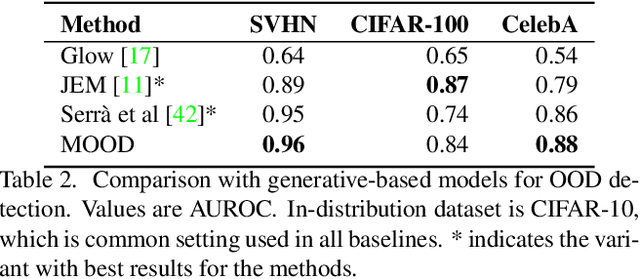
Out-of-distribution (OOD) detection is essential to prevent anomalous inputs from causing a model to fail during deployment. While improved OOD detection methods have emerged, they often rely on the final layer outputs and require a full feedforward pass for any given input. In this paper, we propose a novel framework, multi-level out-of-distribution detection MOOD, which exploits intermediate classifier outputs for dynamic and efficient OOD inference. We explore and establish a direct relationship between the OOD data complexity and optimal exit level, and show that easy OOD examples can be effectively detected early without propagating to deeper layers. At each exit, the OOD examples can be distinguished through our proposed adjusted energy score, which is both empirically and theoretically suitable for networks with multiple classifiers. We extensively evaluate MOOD across 10 OOD datasets spanning a wide range of complexities. Experiments demonstrate that MOOD achieves up to 71.05% computational reduction in inference, while maintaining competitive OOD detection performance.