 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers in the Dark: Navigating Unknown Search Spaces via Bandit Feedback
Mar 25, 2026Effective problem solving with Large Language Models (LLMs) can be enhanced when they are paired with external search algorithms. By viewing the space of diverse ideas and their follow-up possibilities as a tree structure, the search algorithm can navigate such a search space and guide the LLM toward better solutions more efficiently. While the search algorithm enables an effective balance between exploitation and exploration of a tree-structured space, the need for an external component can complicate the overall problem-solving process. We therefore pose the following question: Can LLMs or their underlying Transformer architectures approximate a search algorithm? To answer this question, we first introduce a simplified framework in which tree extensions and feedback signals are externally specified, allowing for controlled evaluation of search capabilities. We call this setting unknown tree search with bandit feedback. Within this setting, we show that Transformers are theoretically expressive enough to implement distinct search strategies and can be trained from scratch to approximate those strategies. Our Transformer models exhibit the possibility of generalizing to unseen conditions such as longer horizons or deeper trees. Furthermore, we demonstrate that continued task-focused training unlocks the complete capabilities of a pretrained LLM, by fine-tuning the LLM on search trajectories.
Think Deep, Not Just Long: Measuring LLM Reasoning Effort via Deep-Thinking Tokens
Feb 13, 2026Large language models (LLMs) have demonstrated impressive reasoning capabilities by scaling test-time compute via long Chain-of-Thought (CoT). However, recent findings suggest that raw token counts are unreliable proxies for reasoning quality: increased generation length does not consistently correlate with accuracy and may instead signal "overthinking," leading to performance degradation. In this work, we quantify inference-time effort by identifying deep-thinking tokens -- tokens where internal predictions undergo significant revisions in deeper model layers prior to convergence. Across four challenging mathematical and scientific benchmarks (AIME 24/25, HMMT 25, and GPQA-diamond) and a diverse set of reasoning-focused models (GPT-OSS, DeepSeek-R1, and Qwen3), we show that deep-thinking ratio (the proportion of deep-thinking tokens in a generated sequence) exhibits a robust and consistently positive correlation with accuracy, substantially outperforming both length-based and confidence-based baselines. Leveraging this insight, we introduce Think@n, a test-time scaling strategy that prioritizes samples with high deep-thinking ratios. We demonstrate that Think@n matches or exceeds standard self-consistency performance while significantly reducing inference costs by enabling the early rejection of unpromising generations based on short prefixes.
DS-ProGen: A Dual-Structure Deep Language Model for Functional Protein Design
May 18, 2025Inverse Protein Folding (IPF) is a critical subtask in the field of protein design, aiming to engineer amino acid sequences capable of folding correctly into a specified three-dimensional (3D) conformation. Although substantial progress has been achieved in recent years, existing methods generally rely on either backbone coordinates or molecular surface features alone, which restricts their ability to fully capture the complex chemical and geometric constraints necessary for precise sequence prediction. To address this limitation, we present DS-ProGen, a dual-structure deep language model for functional protein design, which integrates both backbone geometry and surface-level representations. By incorporating backbone coordinates as well as surface chemical and geometric descriptors into a next-amino-acid prediction paradigm, DS-ProGen is able to generate functionally relevant and structurally stable sequences while satisfying both global and local conformational constraints. On the PRIDE dataset, DS-ProGen attains the current state-of-the-art recovery rate of 61.47%, demonstrating the synergistic advantage of multi-modal structural encoding in protein design. Furthermore, DS-ProGen excels in predicting interactions with a variety of biological partners, including ligands, ions, and RNA, confirming its robust functional retention capabilities.
In-Context Learning with Hypothesis-Class Guidance
Feb 28, 2025



Recent research has investigated the underlying mechanisms of in-context learning (ICL) both theoretically and empirically, often using data generated from simple function classes. However, the existing work often focuses on the sequence consisting solely of labeled examples, while in practice, labeled examples are typically accompanied by an instruction, providing some side information about the task. In this work, we propose ICL with hypothesis-class guidance (ICL-HCG), a novel synthetic data model for ICL where the input context consists of the literal description of a (finite) hypothesis class H and $(x,y)$ pairs from a hypothesis chosen from H. Under our framework ICL-HCG, we conduct extensive experiments to explore: (i) a variety of generalization abilities to new hypothesis classes; (ii) different model architectures; (iii) sample complexity; (iv) in-context data imbalance; (v) the role of instruction; and (vi) the effect of pretraining hypothesis diversity. As a result, we show that (a) Transformers can successfully learn ICL-HCG and generalize to unseen hypotheses and unseen hypothesis classes, and (b) compared with ICL without instruction, ICL-HCG achieves significantly higher accuracy, demonstrating the role of instructions.
Task Vectors in In-Context Learning: Emergence, Formation, and Benefit
Jan 16, 2025In-context learning is a remarkable capability of transformers, referring to their ability to adapt to specific tasks based on a short history or context. Previous research has found that task-specific information is locally encoded within models, though their emergence and functionality remain unclear due to opaque pre-training processes. In this work, we investigate the formation of task vectors in a controlled setting, using models trained from scratch on synthetic datasets. Our findings confirm that task vectors naturally emerge under certain conditions, but the tasks may be relatively weakly and/or non-locally encoded within the model. To promote strong task vectors encoded at a prescribed location within the model, we propose an auxiliary training mechanism based on a task vector prompting loss (TVP-loss). This method eliminates the need to search for task-correlated encodings within the trained model and demonstrably improves robustness and generalization.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024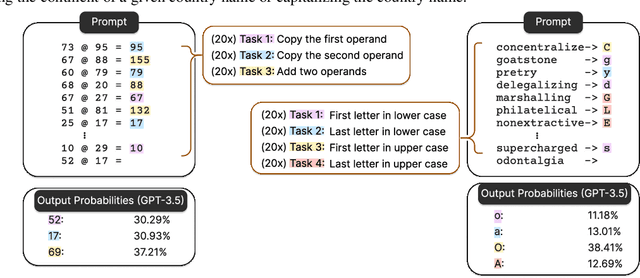

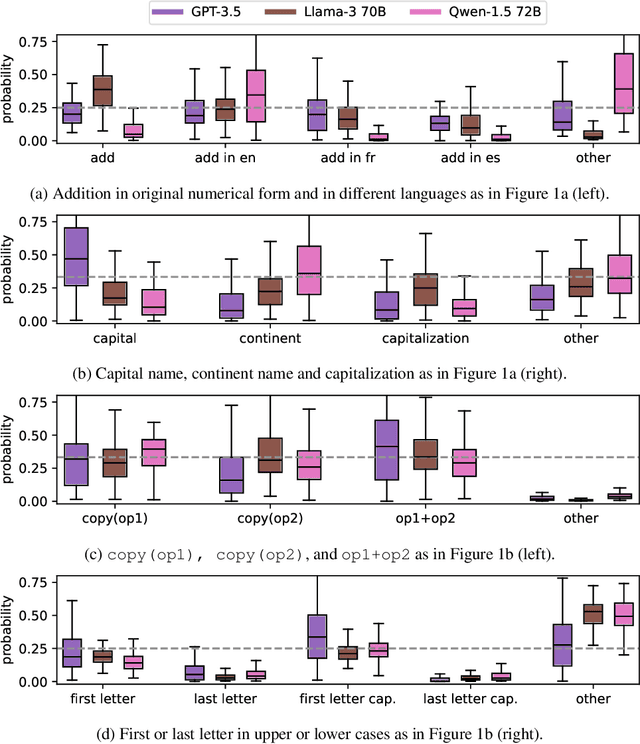
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
Dual Operating Modes of In-Context Learning
Feb 29, 2024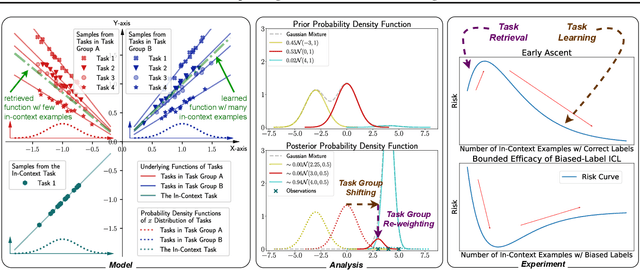

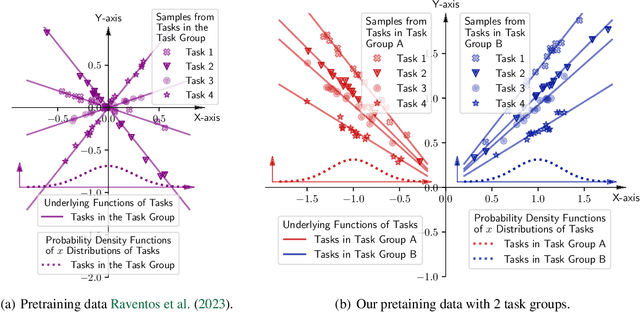

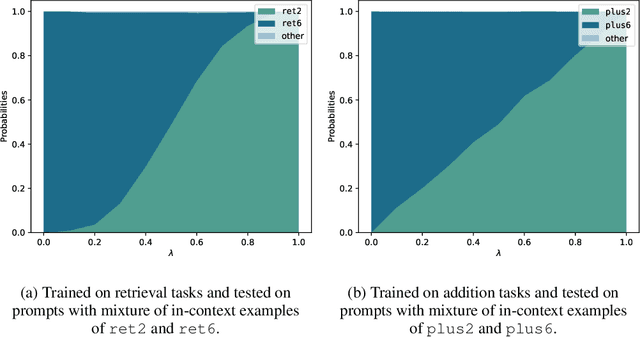
In-context learning (ICL) exhibits dual operating modes: task learning, i.e., acquiring a new skill from in-context samples, and task retrieval, i.e., locating and activating a relevant pretrained skill. Recent theoretical work investigates various mathematical models to analyze ICL, but existing models explain only one operating mode at a time. We introduce a probabilistic model, with which one can explain the dual operating modes of ICL simultaneously. Focusing on in-context learning of linear functions, we extend existing models for pretraining data by introducing multiple task groups and task-dependent input distributions. We then analyze the behavior of the optimally pretrained model under the squared loss, i.e., the MMSE estimator of the label given in-context examples. Regarding pretraining task distribution as prior and in-context examples as the observation, we derive the closed-form expression of the task posterior distribution. With the closed-form expression, we obtain a quantitative understanding of the two operating modes of ICL. Furthermore, we shed light on an unexplained phenomenon observed in practice: under certain settings, the ICL risk initially increases and then decreases with more in-context examples. Our model offers a plausible explanation for this "early ascent" phenomenon: a limited number of in-context samples may lead to the retrieval of an incorrect skill, thereby increasing the risk, which will eventually diminish as task learning takes effect with more in-context samples. We also theoretically analyze ICL with biased labels, e.g., zero-shot ICL, where in-context examples are assigned random labels. Lastly, we validate our findings and predictions via experiments involving Transformers and large language models.
Pre-trained Recommender Systems: A Causal Debiasing Perspective
Oct 30, 2023



Recent studies on pre-trained vision/language models have demonstrated the practical benefit of a new, promising solution-building paradigm in AI where models can be pre-trained on broad data describing a generic task space and then adapted successfully to solve a wide range of downstream tasks, even when training data is severely limited (e.g., in zero- or few-shot learning scenarios). Inspired by such progress, we investigate in this paper the possibilities and challenges of adapting such a paradigm to the context of recommender systems, which is less investigated from the perspective of pre-trained model. In particular, we propose to develop a generic recommender that captures universal interaction patterns by training on generic user-item interaction data extracted from different domains, which can then be fast adapted to improve few-shot learning performance in unseen new domains (with limited data). However, unlike vision/language data which share strong conformity in the semantic space, universal patterns underlying recommendation data collected across different domains (e.g., different countries or different E-commerce platforms) are often occluded by both in-domain and cross-domain biases implicitly imposed by the cultural differences in their user and item bases, as well as their uses of different e-commerce platforms. As shown in our experiments, such heterogeneous biases in the data tend to hinder the effectiveness of the pre-trained model. To address this challenge, we further introduce and formalize a causal debiasing perspective, which is substantiated via a hierarchical Bayesian deep learning model, named PreRec. Our empirical studies on real-world data show that the proposed model could significantly improve the recommendation performance in zero- and few-shot learning settings under both cross-market and cross-platform scenarios.
LIFT: Language-Interfaced Fine-Tuning for Non-Language Machine Learning Tasks
Jun 15, 2022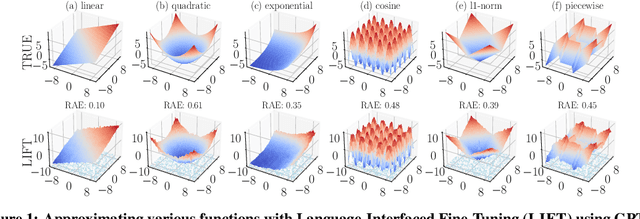
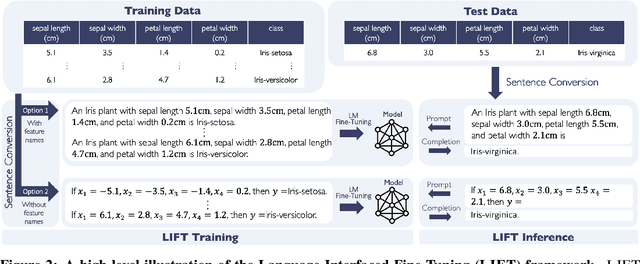

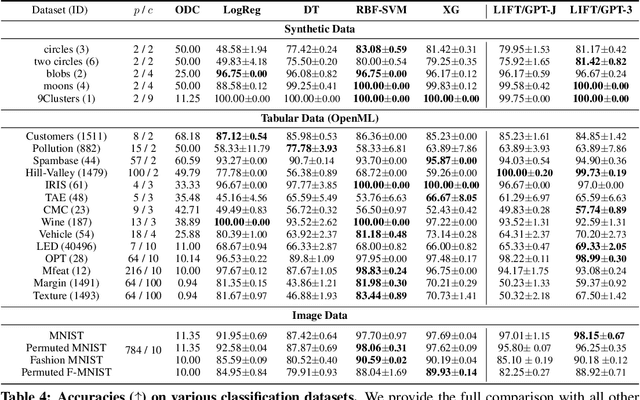
Fine-tuning pretrained language models (LMs) without making any architectural changes has become a norm for learning various language downstream tasks. However, for non-language downstream tasks, a common practice is to employ task-specific designs for input, output layers, and loss functions. For instance, it is possible to fine-tune an LM into an MNIST classifier by replacing the word embedding layer with an image patch embedding layer, the word token output layer with a 10-way output layer, and the word prediction loss with a 10-way classification loss, respectively. A natural question arises: can LM fine-tuning solve non-language downstream tasks without changing the model architecture or loss function? To answer this, we propose Language-Interfaced Fine-Tuning (LIFT) and study its efficacy and limitations by conducting an extensive empirical study on a suite of non-language classification and regression tasks. LIFT does not make any changes to the model architecture or loss function, and it solely relies on the natural language interface, enabling "no-code machine learning with LMs." We find that LIFT performs relatively well across a wide range of low-dimensional classification and regression tasks, matching the performances of the best baselines in many cases, especially for the classification tasks. We report the experimental results on the fundamental properties of LIFT, including its inductive bias, sample efficiency, ability to extrapolate, robustness to outliers and label noise, and generalization. We also analyze a few properties/techniques specific to LIFT, e.g., context-aware learning via appropriate prompting, quantification of predictive uncertainty, and two-stage fine-tuning. Our code is available at https://github.com/UW-Madison-Lee-Lab/LanguageInterfacedFineTuning.
MOOD: Multi-level Out-of-distribution Detection
Apr 30, 2021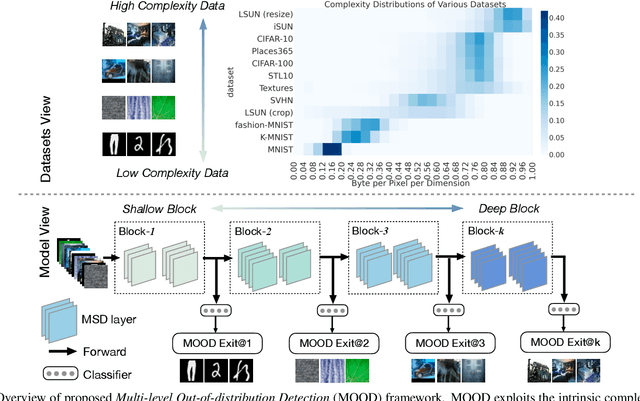
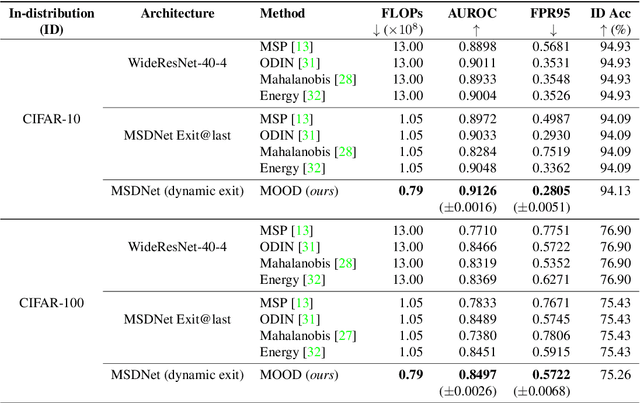
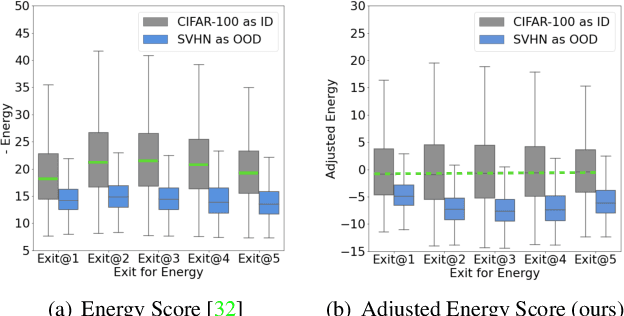
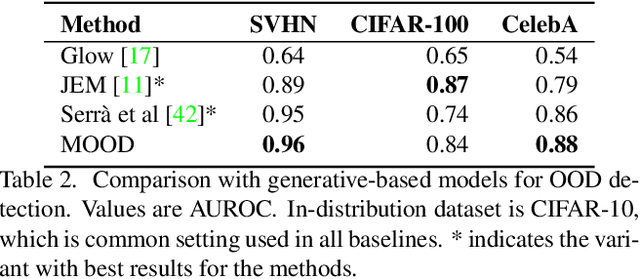
Out-of-distribution (OOD) detection is essential to prevent anomalous inputs from causing a model to fail during deployment. While improved OOD detection methods have emerged, they often rely on the final layer outputs and require a full feedforward pass for any given input. In this paper, we propose a novel framework, multi-level out-of-distribution detection MOOD, which exploits intermediate classifier outputs for dynamic and efficient OOD inference. We explore and establish a direct relationship between the OOD data complexity and optimal exit level, and show that easy OOD examples can be effectively detected early without propagating to deeper layers. At each exit, the OOD examples can be distinguished through our proposed adjusted energy score, which is both empirically and theoretically suitable for networks with multiple classifiers. We extensively evaluate MOOD across 10 OOD datasets spanning a wide range of complexities. Experiments demonstrate that MOOD achieves up to 71.05% computational reduction in inference, while maintaining competitive OOD detection performance.