 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEndless Terminals: Scaling RL Environments for Terminal Agents
Jan 27, 2026Environments are the bottleneck for self-improving agents. Current terminal benchmarks were built for evaluation, not training; reinforcement learning requires a scalable pipeline, not just a dataset. We introduce Endless Terminals, a fully autonomous pipeline that procedurally generates terminal-use tasks without human annotation. The pipeline has four stages: generating diverse task descriptions, building and validating containerized environments, producing completion tests, and filtering for solvability. From this pipeline we obtain 3255 tasks spanning file operations, log management, data processing, scripting, and database operations. We train agents using vanilla PPO with binary episode level rewards and a minimal interaction loop: no retrieval, multi-agent coordination, or specialized tools. Despite this simplicity, models trained on Endless Terminals show substantial gains: on our held-out dev set, Llama-3.2-3B improves from 4.0% to 18.2%, Qwen2.5-7B from 10.7% to 53.3%, and Qwen3-8B-openthinker-sft from 42.6% to 59.0%. These improvements transfer to human-curated benchmarks: models trained on Endless Terminals show substantial gains on held out human curated benchmarks: on TerminalBench 2.0, Llama-3.2-3B improves from 0.0% to 2.2%, Qwen2.5-7B from 2.2% to 3.4%, and Qwen3-8B-openthinker-sft from 1.1% to 6.7%, in each case outperforming alternative approaches including models with more complex agentic scaffolds. These results demonstrate that simple RL succeeds when environments scale.
Wait, Wait, Wait... Why Do Reasoning Models Loop?
Dec 15, 2025Reasoning models (e.g., DeepSeek-R1) generate long chains of thought to solve harder problems, but they often loop, repeating the same text at low temperatures or with greedy decoding. We study why this happens and what role temperature plays. With open reasoning models, we find that looping is common at low temperature. Larger models tend to loop less, and distilled students loop significantly even when their teachers rarely do. This points to mismatches between the training distribution and the learned model, which we refer to as errors in learning, as a key cause. To understand how such errors cause loops, we introduce a synthetic graph reasoning task and demonstrate two mechanisms. First, risk aversion caused by hardness of learning: when the correct progress-making action is hard to learn but an easy cyclic action is available, the model puts relatively more probability on the cyclic action and gets stuck. Second, even when there is no hardness, Transformers show an inductive bias toward temporally correlated errors, so the same few actions keep being chosen and loops appear. Higher temperature reduces looping by promoting exploration, but it does not fix the errors in learning, so generations remain much longer than necessary at high temperature; in this sense, temperature is a stopgap rather than a holistic solution. We end with a discussion of training-time interventions aimed at directly reducing errors in learning.
Extrapolation by Association: Length Generalization Transfer in Transformers
Jun 10, 2025Transformer language models have demonstrated impressive generalization capabilities in natural language domains, yet we lack a fine-grained understanding of how such generalization arises. In this paper, we investigate length generalization--the ability to extrapolate from shorter to longer inputs--through the lens of \textit{task association}. We find that length generalization can be \textit{transferred} across related tasks. That is, training a model with a longer and related auxiliary task can lead it to generalize to unseen and longer inputs from some other target task. We demonstrate this length generalization transfer across diverse algorithmic tasks, including arithmetic operations, string transformations, and maze navigation. Our results show that transformer models can inherit generalization capabilities from similar tasks when trained jointly. Moreover, we observe similar transfer effects in pretrained language models, suggesting that pretraining equips models with reusable computational scaffolding that facilitates extrapolation in downstream settings. Finally, we provide initial mechanistic evidence that length generalization transfer correlates with the re-use of the same attention heads between the tasks. Together, our findings deepen our understanding of how transformers generalize to out-of-distribution inputs and highlight the compositional reuse of inductive structure across tasks.
Phi-4-reasoning Technical Report
Apr 30, 2025We introduce Phi-4-reasoning, a 14-billion parameter reasoning model that achieves strong performance on complex reasoning tasks. Trained via supervised fine-tuning of Phi-4 on carefully curated set of "teachable" prompts-selected for the right level of complexity and diversity-and reasoning demonstrations generated using o3-mini, Phi-4-reasoning generates detailed reasoning chains that effectively leverage inference-time compute. We further develop Phi-4-reasoning-plus, a variant enhanced through a short phase of outcome-based reinforcement learning that offers higher performance by generating longer reasoning traces. Across a wide range of reasoning tasks, both models outperform significantly larger open-weight models such as DeepSeek-R1-Distill-Llama-70B model and approach the performance levels of full DeepSeek-R1 model. Our comprehensive evaluations span benchmarks in math and scientific reasoning, coding, algorithmic problem solving, planning, and spatial understanding. Interestingly, we observe a non-trivial transfer of improvements to general-purpose benchmarks as well. In this report, we provide insights into our training data, our training methodologies, and our evaluations. We show that the benefit of careful data curation for supervised fine-tuning (SFT) extends to reasoning language models, and can be further amplified by reinforcement learning (RL). Finally, our evaluation points to opportunities for improving how we assess the performance and robustness of reasoning models.
VersaPRM: Multi-Domain Process Reward Model via Synthetic Reasoning Data
Feb 10, 2025



Process Reward Models (PRMs) have proven effective at enhancing mathematical reasoning for Large Language Models (LLMs) by leveraging increased inference-time computation. However, they are predominantly trained on mathematical data and their generalizability to non-mathematical domains has not been rigorously studied. In response, this work first shows that current PRMs have poor performance in other domains. To address this limitation, we introduce VersaPRM, a multi-domain PRM trained on synthetic reasoning data generated using our novel data generation and annotation method. VersaPRM achieves consistent performance gains across diverse domains. For instance, in the MMLU-Pro category of Law, VersaPRM via weighted majority voting, achieves a 7.9% performance gain over the majority voting baseline -- surpassing Qwen2.5-Math-PRM's gain of 1.3%. We further contribute to the community by open-sourcing all data, code and models for VersaPRM.
Self-Improving Transformers Overcome Easy-to-Hard and Length Generalization Challenges
Feb 03, 2025Large language models often struggle with length generalization and solving complex problem instances beyond their training distribution. We present a self-improvement approach where models iteratively generate and learn from their own solutions, progressively tackling harder problems while maintaining a standard transformer architecture. Across diverse tasks including arithmetic, string manipulation, and maze solving, self-improving enables models to solve problems far beyond their initial training distribution-for instance, generalizing from 10-digit to 100-digit addition without apparent saturation. We observe that in some cases filtering for correct self-generated examples leads to exponential improvements in out-of-distribution performance across training rounds. Additionally, starting from pretrained models significantly accelerates this self-improvement process for several tasks. Our results demonstrate how controlled weak-to-strong curricula can systematically teach a model logical extrapolation without any changes to the positional embeddings, or the model architecture.
Task Vectors in In-Context Learning: Emergence, Formation, and Benefit
Jan 16, 2025In-context learning is a remarkable capability of transformers, referring to their ability to adapt to specific tasks based on a short history or context. Previous research has found that task-specific information is locally encoded within models, though their emergence and functionality remain unclear due to opaque pre-training processes. In this work, we investigate the formation of task vectors in a controlled setting, using models trained from scratch on synthetic datasets. Our findings confirm that task vectors naturally emerge under certain conditions, but the tasks may be relatively weakly and/or non-locally encoded within the model. To promote strong task vectors encoded at a prescribed location within the model, we propose an auxiliary training mechanism based on a task vector prompting loss (TVP-loss). This method eliminates the need to search for task-correlated encodings within the trained model and demonstrably improves robustness and generalization.
Lexico: Extreme KV Cache Compression via Sparse Coding over Universal Dictionaries
Dec 12, 2024



We introduce Lexico, a novel KV cache compression method that leverages sparse coding with a universal dictionary. Our key finding is that key-value cache in modern LLMs can be accurately approximated using sparse linear combination from a small, input-agnostic dictionary of ~4k atoms, enabling efficient compression across different input prompts, tasks and models. Using orthogonal matching pursuit for sparse approximation, Lexico achieves flexible compression ratios through direct sparsity control. On GSM8K, across multiple model families (Mistral, Llama 3, Qwen2.5), Lexico maintains 90-95% of the original performance while using only 15-25% of the full KV-cache memory, outperforming both quantization and token eviction methods. Notably, Lexico remains effective in low memory regimes where 2-bit quantization fails, achieving up to 1.7x better compression on LongBench and GSM8K while maintaining high accuracy.
Everything Everywhere All at Once: LLMs can In-Context Learn Multiple Tasks in Superposition
Oct 08, 2024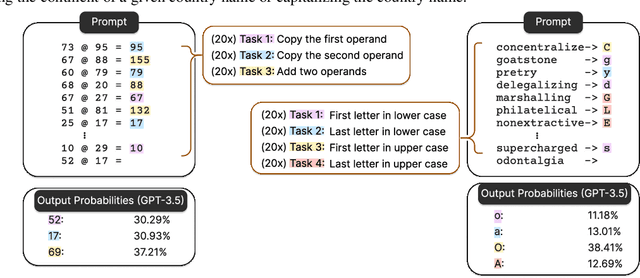

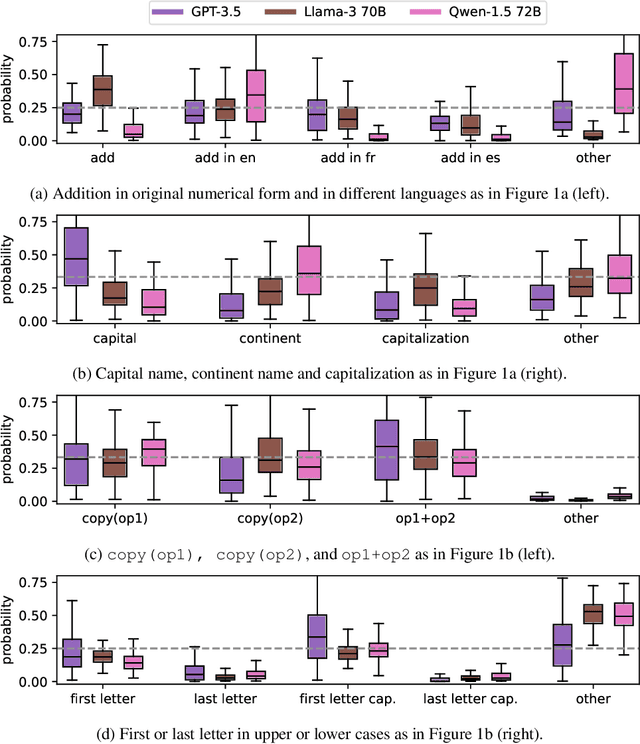
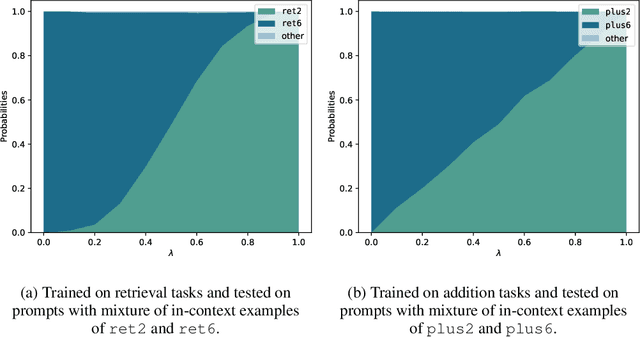
Large Language Models (LLMs) have demonstrated remarkable in-context learning (ICL) capabilities. In this study, we explore a surprising phenomenon related to ICL: LLMs can perform multiple, computationally distinct ICL tasks simultaneously, during a single inference call, a capability we term "task superposition". We provide empirical evidence of this phenomenon across various LLM families and scales and show that this phenomenon emerges even if we train the model to in-context learn one task at a time. We offer theoretical explanations that this capability is well within the expressive power of transformers. We also explore how LLMs internally compose task vectors during superposition. Furthermore, we show that larger models can solve more ICL tasks in parallel, and better calibrate their output distribution. Our findings offer insights into the latent capabilities of LLMs, further substantiate the perspective of "LLMs as superposition of simulators", and raise questions about the mechanisms enabling simultaneous task execution.
From Artificial Needles to Real Haystacks: Improving Retrieval Capabilities in LLMs by Finetuning on Synthetic Data
Jun 27, 2024



Recent studies have shown that Large Language Models (LLMs) struggle to accurately retrieve information and maintain reasoning capabilities when processing long-context inputs. To address these limitations, we propose a finetuning approach utilizing a carefully designed synthetic dataset comprising numerical key-value retrieval tasks. Our experiments on models like GPT-3.5 Turbo and Mistral 7B demonstrate that finetuning LLMs on this dataset significantly improves LLMs' information retrieval and reasoning capabilities in longer-context settings. We present an analysis of the finetuned models, illustrating the transfer of skills from synthetic to real task evaluations (e.g., $10.5\%$ improvement on $20$ documents MDQA at position $10$ for GPT-3.5 Turbo). We also find that finetuned LLMs' performance on general benchmarks remains almost constant while LLMs finetuned on other baseline long-context augmentation data can encourage hallucination (e.g., on TriviaQA, Mistral 7B finetuned on our synthetic data cause no performance drop while other baseline data can cause a drop that ranges from $2.33\%$ to $6.19\%$). Our study highlights the potential of finetuning on synthetic data for improving the performance of LLMs on longer-context tasks.