 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooped Transformers are Better at Learning Learning Algorithms
Paper and Code
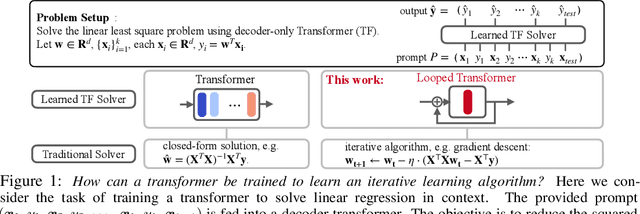
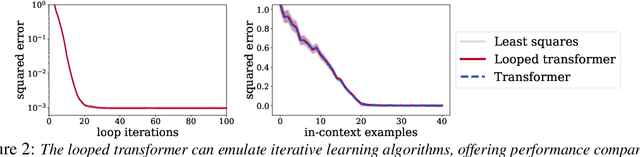
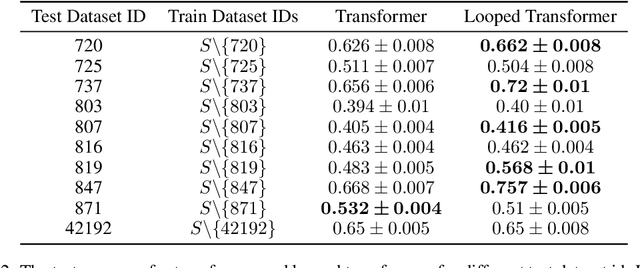
Transformers have demonstrated effectiveness in \emph{in-context solving} data-fitting problems from various (latent) models, as reported by Garg et al. However, the absence of an inherent iterative structure in the transformer architecture presents a challenge in emulating the iterative algorithms, which are commonly employed in traditional machine learning methods. To address this, we propose the utilization of \emph{looped} transformer architecture and its associated training methodology, with the aim of incorporating iterative characteristics into the transformer architectures. Experimental results suggest that the looped transformer achieves performance comparable to the standard transformer in solving various data-fitting problems, while utilizing less than 10\% of the parameter count.